OpenAI CLIP模型袖珍版,24MB实现文本图像匹配,iPhone上可运行
机器之心报道
OpenAI 的 CLIP 模型在匹配图像与文本类别方面非常强大,但原始 CLIP 模型是在 4 亿多个图像 - 文本对上训练的,耗费了相当大的算力。来自 PicCollage 公司的研究者最近进行了缩小 CLIP 模型尺寸的研究,并取得了出色的效果。
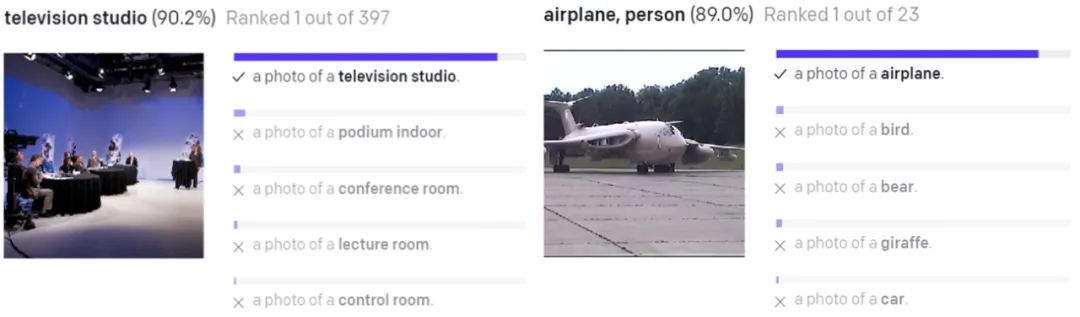
一张带有「Cat」这个词的图片;
一张带有「Gat」这个词的图片;
一张带有猫的图片。


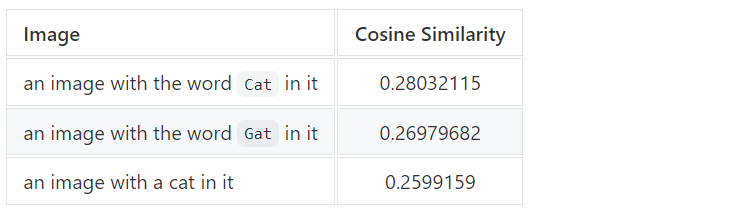
图像包含与搜索词相似的文本:即文本相似;
图像和搜索词语义相似:即语义相似。
image_vectors /= np.linalg.norm(image_vectors, axis=-1, keepdims=True)cosine_similarities = text_vector @ image_vectors
# add bias to the image vectorsimage_vectors += scale * textness_bias# or add bias to the text vectortext_vector += scale * textness_bias
Reducing “textness”: training a small model with no hidden layerWe created a dataset of images with and without text in them. The idea was to train a model and then use the weights of the model as an indicator of textness bias:class Model(nn.Module):def __init__(self, dim=512):super(Model, self).__init__()self.linear = nn.Linear(dim, 2)def forward(self, x):return self.linear(x)model = Model()Then we used the weight vector responsible for predicting the positive label as the textness bias. Another interesting finding was that adding the bias to the text vector was much more effective than adding it to the image vectors.textness_bias = model.linear.weight[1]text_vector += scale * textness_biasThe bigger the scale, the more emphasis CLIP puts on textual similarity. Let's take a look at some of the results.Results of controlling textual similarity in searchFor every search term, we varied the value of scale sequentially like so: -2, -1, 0, 1, 2. For each value of scale, we stored the top ten results in a single row. Thus for each search term, we got a grid of images where each row corresponded to a value of scale and contained top ten results for that scale. Notice how the preference for textual similarity increases as we go from top row to bottom row:
class Model(nn.Module):def __init__(self, dim=512):super(Model, self).__init__()self.linear = nn.Linear(dim, 2)def forward(self, x):return self.linear(x)model = Model()
textness_bias = model.linear.weight[1]text_vector += scale * textness_bias

teacher_clip = VisualTransformer(input_resolution=224,patch_size=32,width=768,layers=12,heads=12,output_dim=512)student_clip_12_heads = VisualTransformer(input_resolution=224,patch_size=32,width=768//2,layers=12//2,heads=12,output_dim=512)student_clip_24_heads = VisualTransformer(input_resolution=224,patch_size=32,width=768//2,layers=12//2,heads=24,output_dim=512)用于训练的数据:该研究首先以从多种来源获取的约 200000 张图像的数据集开始训练。大约 10 个 epoch 之后,一旦开始看到一些有希望的结果,训练数据集就增加到 800000 多张图像。
使用的损失函数:KLD + L1 损失的总和用于训练模型。对于前十个 epoch,温度(temperature)设置为 4,然后降低到 2。


机器之心招人啦!
为进一步生产更多的高质量内容,提供更好数据产品及产业服务,机器之心需要更多的小伙伴加入进来,共同努力打造专业的人工智能信息服务平台。

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com
登录查看更多
相关内容

Arxiv
0+阅读 · 2021年10月15日
Arxiv
6+阅读 · 2021年3月17日


相关VIP内容
相关资讯
相关论文
Arxiv
0+阅读 · 2021年10月15日
Arxiv
6+阅读 · 2021年3月17日