如何优雅地编码文本中的位置信息?三种positioanl encoding方法简述
前言
相信熟悉BERT的小伙伴对positional encoding(位置表示) 肯定都不会陌生~ 虽然positional encoding只是BERT中比较小的一个组成部分,但是实际上却暗藏玄机。所以,今天呢我们就把positional encoding单独拎出来对其进行一个全面的剖析~~
-
Why?为什么需要positional encoding -
What?两种positional encoding方式:绝对位置编码与相对位置编码 -
How?不同方法优缺点对比
Why
众所周知,文本是时序型数据,词与词之间的顺序关系往往影响整个句子的含义。举个栗子:
小夕/是/一个/萌/妹子。一个/妹子/是/萌/小夕??萌/小夕/是/一个/妹子??

为了避免不必要的误会,所以我们在对文本数据进行建模的时候需要考虑词与词之间的顺序关系。
可是,要建模文本中的顺序关系必须要用positional encoding吗?
答案是No!
只有当我们使用对位置不敏感(position-insensitive)的模型对文本数据建模的时候,才需要额外使用positional encoding。
什么是对位置敏感的模型??什么又是对位置不敏感的模型??

如果模型的输出会随着输入文本数据顺序的变化而变化,那么这个模型就是关于位置敏感的,反之则是位置不敏感的。
用更清晰的数学语言来解释。设模型为函数 ,其中输入为一个词序列 ,输出结果为向量 。对 的任意置换,都有
则模型 是关于位置不敏感的。
在我们常用的文本模型中,RNN和textCNN都是关于位置敏感的,使用它们对文本数据建模时,模型结构天然考虑了文本中词与词之间的顺序关系。而以attention为核心的transformer则是位置不敏感的,使用这一类位置不敏感的模型的时候需要额外加入positional encoding引入文本中词与词的顺序关系。
What
对于transformer模型的positional encoding有两种主流方式:
绝对位置编码
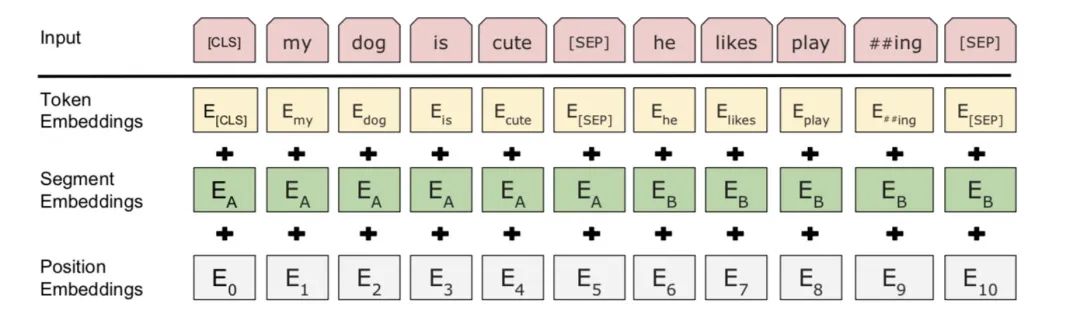
现在普遍使用的一种方法Learned Positional Embedding编码绝对位置,相对简单也很容易理解。直接对不同的位置随机初始化一个postion embedding,加到word embedding上输入模型,作为参数进行训练。
相对位置编码
使用绝对位置编码,不同位置对应的positional embedding固然不同,但是位置1和位置2的距离比位置3和位置10的距离更近,位置1和位置2与位置3和位置4都只相差1,这些关于位置的相对含义模型能够通过绝对位置编码get到吗?使用Learned Positional Embedding编码,位置之间没有约束关系,我们只能期待它隐式地学到,是否有更合理的方法能够显示的让模型理解位置的相对关系呢?
所以就有了另一种更直观地方法——相对位置编码。下面介绍两种编码相对位置的方法:Sinusoidal Position Encoding和Complex embedding。
Sinusoidal Position Encoding
使用正余弦函数表示绝对位置,通过两者乘积得到相对位置:
这样设计的好处是位置 的psotional encoding可以被位置 线性表示,反应其相对位置关系。
Sinusoidal Position Encoding虽然看起来很复杂,但是证明 可以被 线性表示,只需要用到高中的正弦余弦公式:(注意:长公式可以左右滑动噢!)
对于位置 的positional encoding
其中
将公式(5)(6)稍作调整,就有
注意啦, 和 相对距离 是常数,所以有
其中为常数。
所以 可以被 线性表示。
计算 和 的内积,有
其中 .
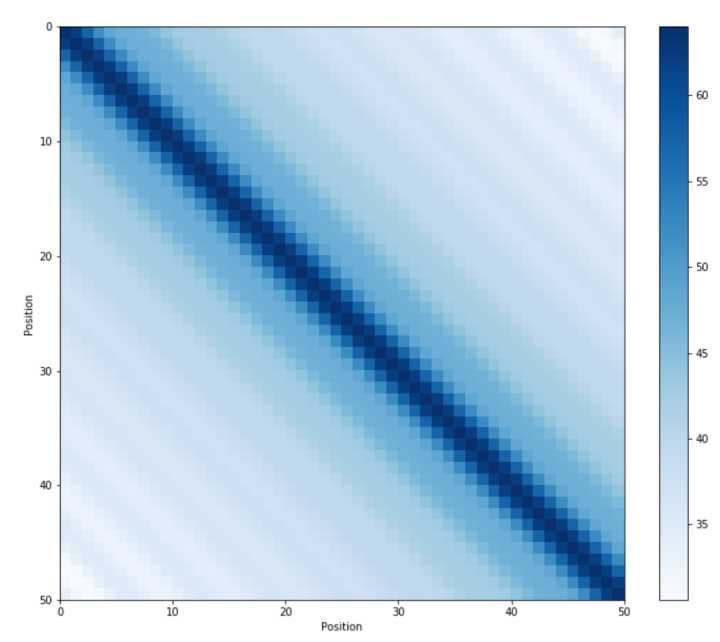
和 的内积会随着相对位置的递增而减小,从而表征位置的相对距离。但是不难发现,由于距离的对称性,Sinusoidal Position Encoding虽然能够反映相对位置的距离关系,但是无法区分方向/(ㄒoㄒ)/~~
更加直观的对其可视化[1],可以看到图像关于 对称,无法区分前后关系。
Complex embedding
为了更好的让模型捕获更精确的相对位置关系,比如相邻,前序(precedence)等,ICLR 2020发表的文章《Encoding Word Oder In Complex Embeddings》使用了复数域的连续函数来编码词在不同位置的表示。
不管是Learned Postional Embdedding还是Sinusoidal Position Encoding,某个词 在 位置上的表示为其word embedding加上对应位置的embedding,即:
同word embedding 都是从整数域 到实数域 的一个映射。
对于word embedding来说,这样的设计是合理的。因为不同词的index是独立的,仅和我们具体使用的词典怎么排序有关系,某个词是否在另外一个词前面或者相邻没有任何的信息。但是位置的index并不是满足独立的假设,其顺序关系对文本的正确理解有非常重要的影响。
所以,为了解决pos index的依赖问题(position-insensitive problem),文章使用了关于位置的连续函数来表征词 在 的表示,即:
把公式(13)展开有
其中是关于位置 在复数域上的函数。
为了让上述函数更好的表征位置的相对信息,要求函数 满足以下两个性质:
-
Position-free offset transformation
存在一个函数 使得
其中在不影响理解的情况下,我们把 简写成 。也就是说,词 在pos或者pos+k的表示可以由只和相对位置k有关的一个变换得到,而与具体这个词无关。
-
Boundedness
要求函数 有界。非常合理的一个限制。
最后,论文证明了在复数域上满足这个两个条件的函数一定为下面这样的形式:
将其改写成指数的形式,则为
其中, 为振幅, 为角频率, 为初相,都是需要学习的参数~~
将式(17)代入(14)有
要表征词 在pos上的embedding,需要学习的参数有 , 以及 。以此类推,要表示词表中所有的词,那么需要学习的参数量为😮.由于参数量较大,论文后续还提出了一些减小参数量的方法,有兴趣的同学可以看具体查阅原文哦~~~
How
以上三种positional encoding都不同程度、各有侧重的编码了文本数据中的顺序关系,那么到底哪个更好?我们在平时使用的时候应该如何选择呢?
结果导向的话,肯定是哪种方法效果好选哪种啦~~在《Attention is all you need》[2]里面提到,Learned Positional Embedding和Sinusoidal Position Encoding两种方式的效果没有明显的差别。在论文[3],实验结果表明使用Complex embedding相较前两种方法有较明显的提升。(不过介于这个方法还比较新,大家可以多多尝试对比)。

从方法的可理解性上,相比相对位置编码的两种方法,Learned Positional Embedding更加的简单直接,易于理解。从参数维度上,使用Sinusoidal Position Encoding不会引入额外参数,Learned Positional Embedding增加的参数量会随 线性增长,而Complex Embedding在不做优化的情况下,会增加三倍word embedding的参数量。在可扩展性上,Learned Positional Embedding可扩展性较差,只能表征在 以内的位置,而另外两种方法没有这样的限制,可扩展性更强。
讲了这么多,相信大家对positional encoding已经有了充分的理解~~至于到底应该如何选择,还是需要基于大家对方法的理解实际问题实际分析哦🙃
[3] Complex Embeddings: https://openreview.net/pdf?id=Hke-WTVtwr




