深度学习 | 利用词嵌入对文本进行情感分析
词嵌入(word embedding)是一种词的类型表示,具有相似意义的词具有相似的表示,是将词汇映射到实数向量的方法总称。词嵌入是自然语言处理的重要突破之一。下面将围绕什么是词嵌入、三种词嵌入的主要算法展开讲解,并通过案例具体讲解如何利用词嵌入进行文本的情感分析。
什么是词嵌入?
词嵌入实际上是一类技术,单个词在预定义的向量空间中被表示为实数向量,每个单词都映射到一个向量。举个例子,比如在一个文本中包含“猫”“狗”“爱情”等若干单词,而这若干单词映射到向量空间中,“猫”对应的向量为(0.1 0.2 0.3),“狗”对应的向量为(0.2 0.2 0.4),“爱情”对应的映射为(-0.4 -0.5 -0.2)(本数据仅为示意)。像这种将文本X{x1,x2,x3,x4,x5……xn}映射到多维向量空间Y{y1,y2,y3,y4,y5……yn },这个映射的过程就叫做词嵌入。
之所以希望把每个单词都变成一个向量,目的还是为了方便计算,比如“猫”,“狗”,“爱情”三个词。对于我们人而言,我们可以知道“猫”和“狗”表示的都是动物,而“爱情”是表示的一种情感,但是对于机器而言,这三个词都是用0,1表示成二进制的字符串而已,无法对其进行计算。而通过词嵌入这种方式将单词转变为词向量,机器便可对单词进行计算,通过计算不同词向量之间夹角余弦值cosine而得出单词之间的相似性。
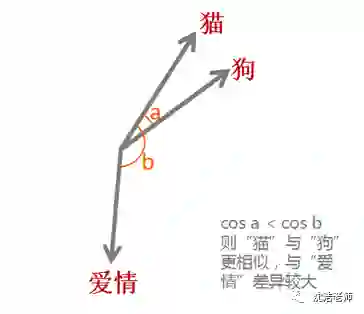
此外,词嵌入还可以做类比,比如:v(“国王”)-v(“男人”)+v(“女人”)≈v(“女王”),v(“中国”)+v(“首都”)≈v(“北京”),当然还可以进行算法推理。有了这些运算,机器也可以像人一样“理解”词汇的意思了。
词嵌入主要算法
那么如何进行词嵌入呢?目前主要有三种算法:
Embedding Layer
由于缺乏更好的名称,Embedding Layer是与特定自然语言处理上的神经网络模型联合学习的单词嵌入。该嵌入方法将清理好的文本中的单词进行one hot编码(热编码),向量空间的大小或维度被指定为模型的一部分,例如50、100或300维。向量以小的随机数进行初始化。Embedding Layer用于神经网络的前端,并采用反向传播算法进行监督。
被编码过的词映射成词向量,如果使用多层感知器模型MLP,则在将词向量输入到模型之前被级联。如果使用循环神经网络RNN,则可以将每个单词作为序列中的一个输入。
这种学习嵌入层的方法需要大量的培训数据,可能很慢,但是可以学习训练出既针对特定文本数据又针对NLP的嵌入模型。
Word2Vec(Word to Vector)/ Doc2Vec(Document to Vector)
Word2Vec是由Tomas Mikolov 等人在《Efficient Estimation of Word Representation in Vector Space》一文中提出,是一种用于有效学习从文本语料库嵌入的独立词语的统计方法。其核心思想就是基于上下文,先用向量代表各个词,然后通过一个预测目标函数学习这些向量的参数。Word2Vec 的网络主体是一种单隐层前馈神经网络,网络的输入和输出均为词向量,其主要训练的是图中的红圈部分。
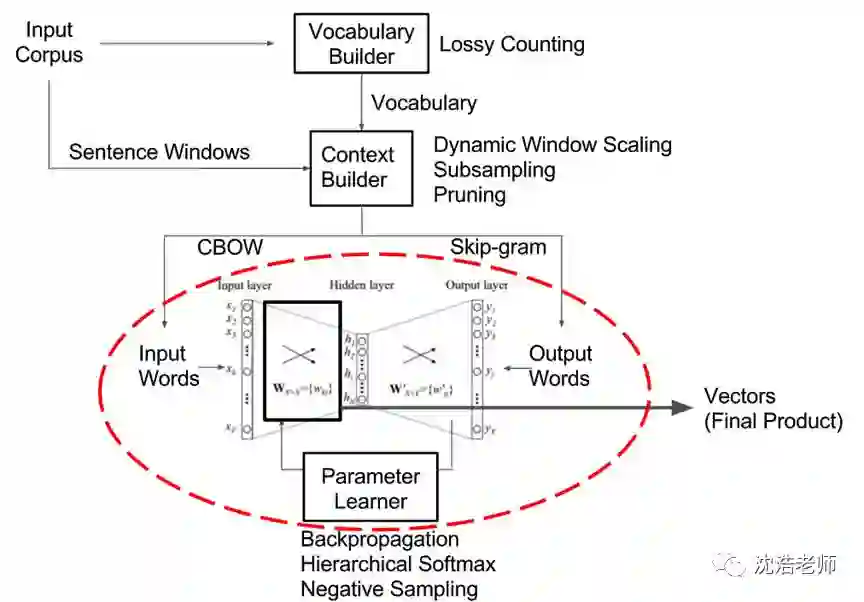
该算法给出了两种训练模型,CBOW (Continuous Bag-of-Words Model) 和 Skip-gram (Continuous Skip-gram Model)。CBOW将一个词所在的上下文中的词作为输入,而那个词本身作为输出,也就是说,看到一个上下文,希望大概能猜出这个词和它的意思。通过在一个大的语料库训练,得到一个从输入层到隐含层的权重模型;而Skip-gram它的做法是,将一个词所在的上下文中的词作为输出,而那个词本身作为输入,也就是说,给出一个词,希望预测可能出现的上下文的词,2-gram比较常用。
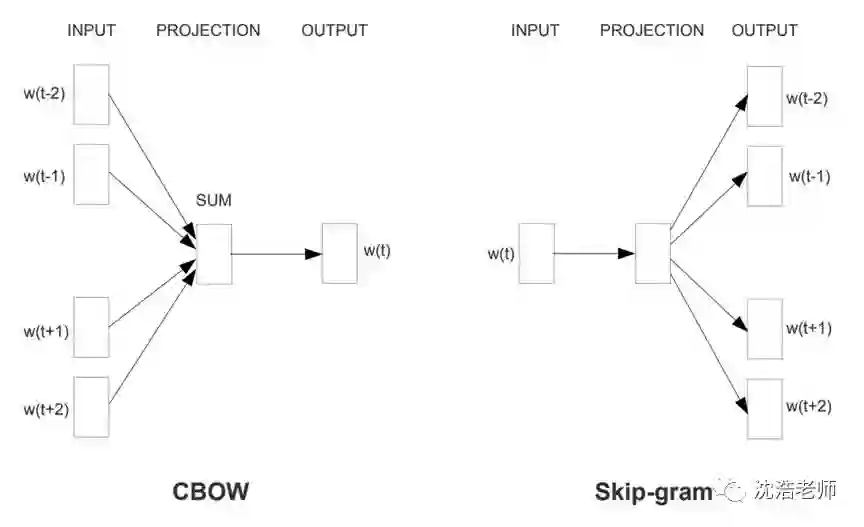
通过在一个大的语料库训练,得到一个从输入层到隐含层的权重模型。给定xx预测xxx的模型的输入都是词的向量,然后通过中间各种深度学习DL的CNN或RNN模型预测下一个词的概率。通过优化目标函数,最后得到这些词汇向量的值。Word2Vec虽然取得了很好的效果,但模型上仍然存在明显的缺陷,比如没有考虑词序,再比如没有考虑全局的统计信息。
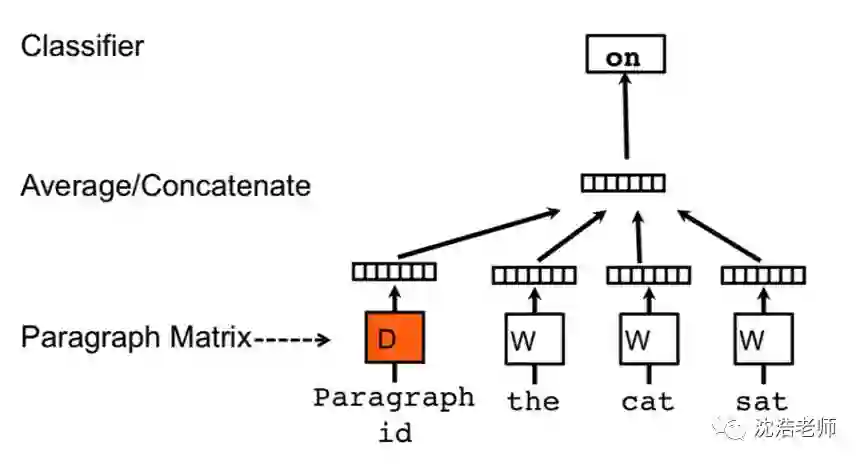
Doc2Vec与Word2Vec的CBOW模型类似,也是基于上下文训练词向量,不同的是,Word2Vec只是简单地将一个单词转换为一个向量,而Doc2Vec不仅可以做到这一点,还可以将一个句子或是一个段落中的所有单词汇成一个向量,为了做到这一点,它只是将一个句子标签视为一个特殊的词,并且在这个特殊的词上做了一些处理,因此,这个特殊的词是一个句子的标签。如图所示,词向量作为矩阵W中的列被捕获,而段落向量作为矩阵D中的列被捕获。
GloVe(Global Vectors for Word Representation)
GloVe是Pennington等人开发的用于有效学习词向量的算法,结合了LSA矩阵分解技术的全局统计与word2vec中的基于局部语境学习。
LSA全称Latent semantic analysis,中文意思是隐含语义分析,LSA算是主体模型topic model的一种,对于LSA的直观认识就是文章里有词语,而词语是由不同的主题生成的,比如一篇文章包含词语:计算机,另一篇文章包含词语:电脑,在一般的向量空间来看,这两篇文章不相关,但是在LSA看来,这两个词属于同一个主题,所以两篇文章也是相关的。该模型不依赖本地上下文,是对全局字词同现矩阵的非零项进行训练,其中列出了给定语料库中单词在彼此间共同出现的频率。
从本质上说,GloVe是具有加权最小二乘法目标的对数双线性模型。字词共现概率的比率又编码成某种形式的潜在可能意义。例如,以下是基于60亿词汇语料库的各种关于冰和蒸汽的词的共现概率:

如上表所示,“ice(冰)”与“solid(固体)”共现的可能性比“gas(气体)”大,“steam(蒸汽)”与“gas(气体)”共现的可能性比“solid(固体)”大,从而很轻易地可以区别出二者区别。而“ice(冰)”和“steam(蒸汽)”都与“water(水)”的共现概率较大,都与“fashion(时尚)”共现概率很小,因此无法区别“ice”和“steam”。只有在可能性的比率中(图表第三行),才会将像“water”和“fashion”这样的非区别性词汇(non-discriminative)的噪音相抵消,可能性比率越大(远大于1)的词与“ice”特性相关联,可能性比率越小(远小于1)则与“steam”的特性相关联。以这种方式,可能性比率编码了许多粗略形式的意义,这些意义与热力学相位的抽象概念相关联。
GloVe的训练目标是学习词向量,使得它们的点积等于“共现概率”的对数,由于比率的对数等于对数差,这个目标将共现概率的比率与词向量空间中的向量相关联,由于这些比率可以编码某种形式的意义,所以该信息也被编码为向量差异。所以所得到的词向量在单词类比任务上执行的很好。
词嵌入应用案例
当您在自然语言处理项目中使用词嵌入时,您可以选择自主学习词嵌入,当然这需要大量的数百万或数十亿文本数据,以确保有用的嵌入被学习。您也可以选择采用开源的预先训练好的词嵌入模型,研究人员通常会免费提供预先训练的词嵌入,例如word2vec和GloVe词嵌入都可以免费下载。
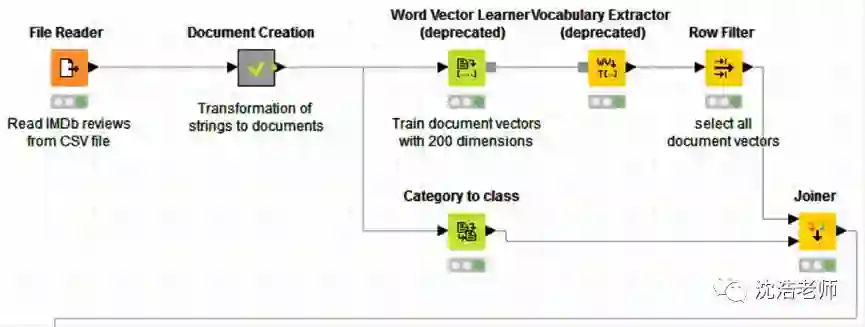
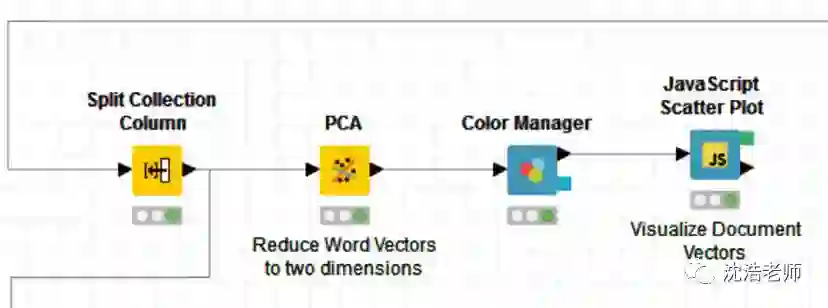
下面我们具体来看一下如何在KNIME中利用词嵌入进行情感分析,整体流程如下图所示:
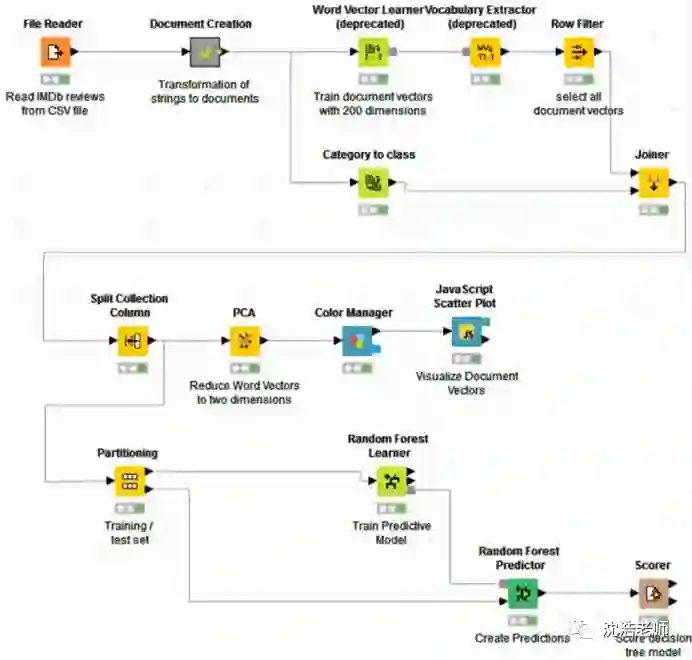
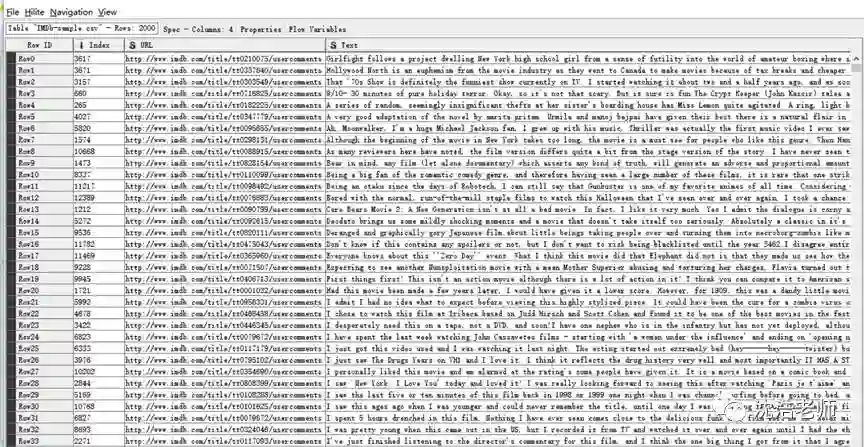
首先,我们从IMDb网站上获取关于《Girlfight》这部影片的2000条评论,储存为.CSV格式的文件,利用File Reader这个节点把文本读入。
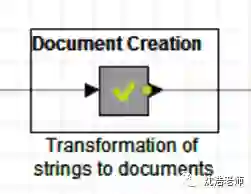
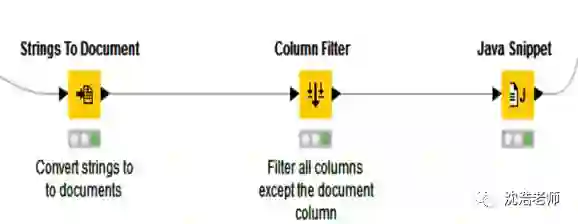
然后我们要将文件中的字符串转化成文档,把文件中除了文档的列都过滤掉,在结构图中是Document Creation这个节点,这是一个节点合集,点开包含三个子节点:
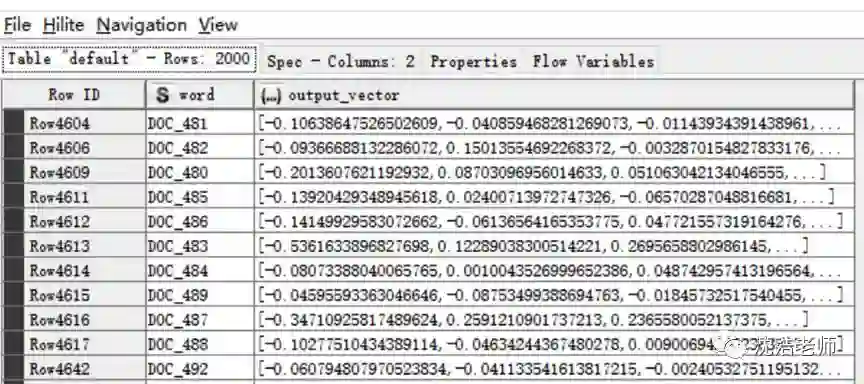
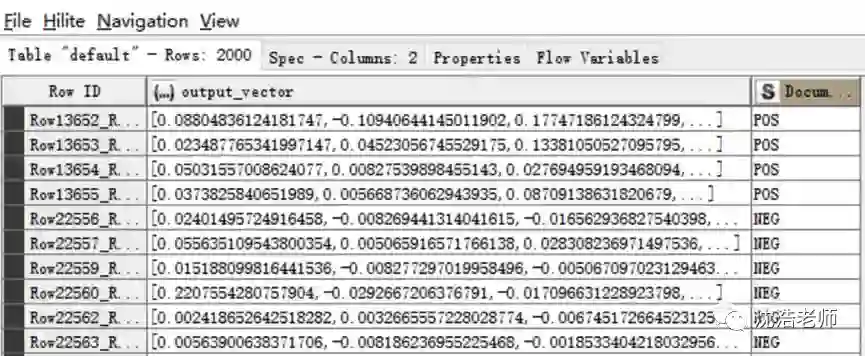
接下来是进行文本的词向量训练,我们预设置词向量维度为200维,并通过上文所介绍的Doc2Vec算法将2000条评论文本转换成2000个向量数值,获得如下图所示的2000个词向量:
另一方面,在进行词向量训练的同时导入预先设定的情感分类标签:
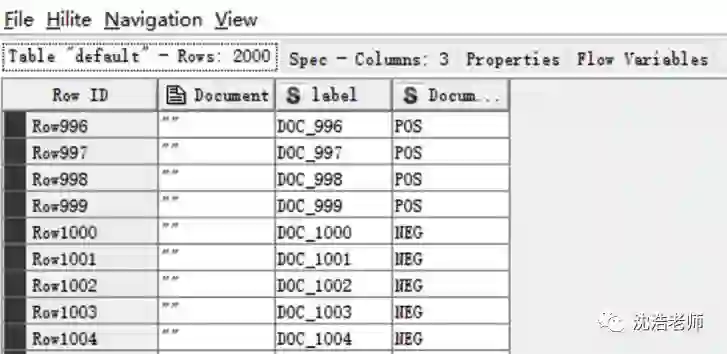
然后,在Joiner节点处,带有”POS”或”NEG”标签的情感词典与训练好的2000条词向量进行匹配,使得2000条词向量分别贴上”POS”或”NEG”标签,这样就获得了2000条词向量的标签数据,以便后面训练情感分析模型。
接下来,由于200维的向量数据量太大,通过主成分分析PCA算法将200维的数据进行降维处理转化为二维向量,以便对其分类效果进行可视化,通过颜色标记,最终2000条评论的情感分析情况如图所示:
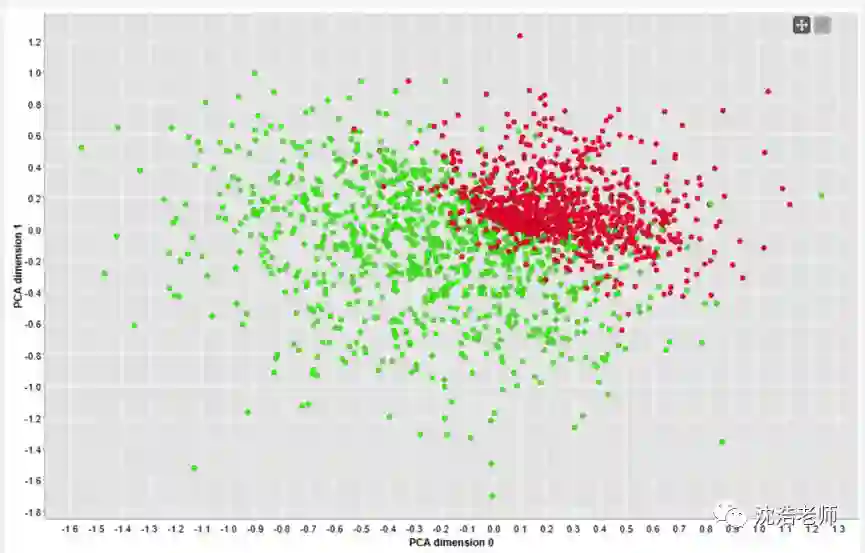
从图上看,POS和NEG的情感正负标签很明显,分类比较理想。
然后,我们开始训练模型。先将数据进行分区,训练集和测试集,七三开分为两部分,一部分是训练数据,一部分是检验数据。
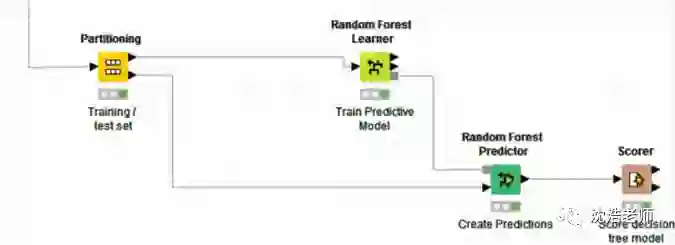
训练模型为Random Forest模型,顾名思义,就是用随机的方式建立一个“森林”,“森林”里面有很多的决策树组成,随机森林的每一颗决策树之间是没有关联的。在得到森林之后,当有一个新的输入样本进入的时候,就让森林中的每一颗决策树分别进行一下判断,看看这个样本该属于哪一类(对于分类算法),然后看看哪一类被选择最多,就预测这个样本为那一类。最终训练出来的Random Forest模型如下图所示:
最后,通过检测数据的测试,我们得出该模型的精度为95.5%,由此可见拟合的模型较为精确:

通过这个案例的练习,我们可以更好的理解词嵌入技术和算法对自然语言处理NLP的新思路,也是深度学习技术的革命性体现。
沈浩老师
大数据挖掘与社会计算实验室主任
中国市场研究行业协会会长




欢迎关注:灵动数艺
——数艺智训




