近期声学领域前沿论文(No. 3)
1. Multi-Geometry Spatial Acoustic Modeling for Distant Speech Recognition, Amazon Inc.
远场语音识别是一个比较复杂的问题,因为它不仅要解决噪声的干扰,还要避免说话人的声音通过室内物体的反射或散射所产生的回声的影响.一个完整的远场语音识别(DSR)通常包含语音活性检测、声源定位、解混响、波束形成和声学模型这些模块,要想提升性能就得联合这些模块进行同时优化.文中研究背景中提到,
However, conventional microphone array techniques degrade speech enhancement performance when there is an array geometry mismatch between design and test conditions.
笔者有一个困惑,麦克风阵列的设计与测试环境中为什么会有很大差异呢?这个会是降低性能的主要因素吗?
作者提出了结合空间滤波的声学模型,其包含多种类型的几何阵列,并运用神经网络来对这些空间滤波器进行编码就可以进行实时处理流式音频数据,这里的意思是不需要等到目标信号全部传过来再计算统计信息了.作者实验表明,双通道的的声学模型在麦克风排列匹配和不匹配的条件下分别可以将词错误率减少13.4%和12.7%,并且,该双通道模型相比于传统的七通道麦克风阵列模型在词错误率上降低了7%.
作者的模型一共包含信号预处理、多通道输入前馈式神经网络(MCDNN)、特征提取前馈式神经网络(FEDNN)、分类网络(LSTM)这四个模块,首先,每个通道的信号经过频域变换得到DFT系数,将所有通道的系数拼接起来传进MCDNN,MCDNN的输出再被送到FEDNN中,其中FEDNN包含一个仿射变换以及ReLU和取Log模块,FEDNN的输出再被传递到LSTM,最后LSTM的输出经过一个仿射变换和Softmax函数输出分类结果.这个网络的特点是完全自我学习,不需要额外的麦克风自我校正或是清晰语音重建等措施.
2. A Vocoder Based Method For Singing Voice Extraction, Universitat Pompeu Fabra
音乐的人声抽取是一个很有价值的研究方向,即如何从带有和声或乐器伴奏中分离出人声,这个可以应用到歌手识别、歌词转写、歌声转换、混音等任务中.传统的方法有主成分分析(PCA)、独立成分分析(ICA)以及非负矩阵分解(NMF),这些方法往往比较慢,并且在分离过程中容易产生新的微扰.
作者在本文中尝试结合深度学习算法对歌声进行重新合成,通过神经网络来从混合音乐中提取出可以放到world中单独合成人声的特征参数,并且这些参数还可以用来进行歌词提取或音频变换.作者使用了混合音频的频谱作为网络的输入,使用了k个卷积block,其中运用了skip、residual connection以及gated dilated,该网络结构灵感取自于wavenet,不过这里不是自回归的,并且把每个频率仓当成不同的通道,每个卷积层都包含一个时间维度的一维卷积.实验数据集用的是iKala,一共包含25230秒的人声和伴奏,以及手动标记的MIDI版本的音符.
文中作者将此模型与另外两个开源模型DeepConvSep以及FASST进行了比较,其中DeepConvSep是利用卷积神经网络来预测频谱Mask的,之所以选择这个算法的原因是它在MIREX2016声源分离挑战赛表现最好,并且在SiSEC2016挑战赛也很有竞争力;而FASST算法是基于非负矩阵分解,已经被用来作为声源分离任务的基准算法了.作者采用了主观评价和客观评价两套方案,主观评价指的是通过邀请实验者来听几组音频,分别根据Intelligibility,Interference,以及Audio Quality来评分,评分结果表明本文模型在Interferene方面要好于DeepConvSep,但是在Intelligibility以及Audio Quality方面要弱于DeepConvSeq,不过相比于基准模型FASST,是全面超越了;而客观评价指的是使用MCD和SIR两个指标来评估,下面先分别简要介绍一下这两个指标:MCD指的是Mel-cepstrum distortion,中文翻译是梅尔倒谱失真,其单位一般为分贝,顾名思义,该值越大,说明失真程度越大,也就是模型越不好,该指标普遍被用于语音合成的客观评估中.
SIR指的是Signal-to-interference ratio,也就是信噪比.
查询了一下,SIR的计算公式如下:
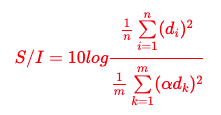
其中,是目标信号的采样幅度,是干扰信号的采样幅度,是设置信噪比的系数.
客观评估结果表明,本文模型在SIR方面超越了DeepConvSep和FASST,但是在MCD指标上标准差较大,虽然均值和最小值都超越了DeepConvSep和FASST.由此看到,在声源分离领域,DeepConvSep还是处在先进水平,本文的改进思路也有很多,例如将world合成器替换成wavenet神经网络合成器,以及将非自回归型的神经网络替换成自回归型.本文的合成效果demo在:https://pc2752.github.io/singing_voice_sep/ .
3. Voice command generation using Progressive Wavegans, Universitat Pompeu Fabra
语音合成技术经历过拼接技术、参数语音合成技术、端对端的神经网络技术三个阶段,就拼接技术而言,它从提前录好的数据库中去找音素单元然后进行拼接,缺点是音素边界不像人说话那么自然;参数语音合成技术一般运用HMM或NN对声学特征以及时长特征进行建模,这类系统工程处理高度复杂,优点是可以产生传给合成器的平滑特征,但往往由于过度平滑或时长模型以及声学模型不够准确,导致声音听起来非常低沉韵律不够自然;以谷歌的wavenet/tacotron为代表的端对端的神经网络技术是语音合成领域目前最前沿的技术,它抛弃了复杂的特征处理工程以及参数合成器的限制,直接通过神经网络来生成原始的音频.
GAN是一种基于对抗思想的神经网络框架,以生成器和判别器达到零和作为模型优化的目标,尽管GAN在图像领域已经被应用地非常完美,但是在语音合成领域,waveGAN还是远远没有达到人声的那种自然效果,本文作者做的工作是对waveGAN的一个延伸,最终在自然度上超越了原始的waveGAN的效果.接下来我从WGAN讲起,然后到waveGAN,最后再介绍作者在waveGAN上做的创新.
WGAN全称为Wasserstein GAN,其出现的背景是,在训练GAN的时候,容易出现两个问题,分别是mode collapse和gradient diminishing.在原始GAN中,我们的损失函数用的是JS Divergence,JS Divergence有一个致命的缺点就是,当生成器的分布与真实点的分布没有任何交集的时候,JS Divergence会变成一个固定的常数,也就是说,这个时候无论你怎么去训练,两个分布始终无法靠近,换句话说,判别器已经提前达到最优值了,生成器再也接收不到任何优化的信号,这就是所谓的gradient diminishing;而mode collapse是指生成器每次只能学习到目标分布的一小部分,当判别器优化了一步之后,生成器的分布又变到目标分布的另外一小部分了,这种情况很有可能循环往复.
其实在GAN中,不一定非得用JS Divergence来衡量两个分布的逼近程度,任意一种Divergence都可以,于是有人提出了使用Earth Mover Distance来衡量两个分布,Earth Mover听起来像推土机,它的意思可以比喻成对于分布P是一个土堆,目标分布Q是一个土堆,如何把P土堆挪成Q土堆并且所耗距离最小.那么这种距离如何用数学表达式衡量呢?推导过程很复杂,结论如下,要找到一个符合特定条件的判别器,使得V(G,D)达到最大:
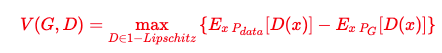
这种特定的判别器需要满足一维Lipschitz函数,Lipschitz函数又称为利普希茨连续条件(Lipschitz continuity),以德国数学家鲁道夫·利普希茨命名.利普希茨连续函数限制了函数改变的速度,因为符合利普希茨条件的函数的斜率,必小于一个称为利普希茨常数的实数.Lipschitz函数可以写成如下形式:
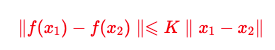
当这里的K取值为1的时候,就是上面的1-Lipschitz函数,不过问题来了,对判别器加了这个约束,如何在训练的时候体现出来呢?原始论文中采取了weight clipping技巧,即把参数w限制在[-c, c]中间;后来有人提出了WGAN-GP,它的论点是如果一个函数是1-Lipschitz函数,等价于它所有对x的梯度的绝对值都不大于1,这句话表现到损失函数上就是加了一个惩罚项,并且实验中发现梯度的绝对值越接近1收敛越快,最终损失函数形式如下:
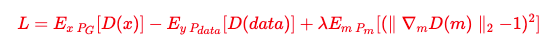
其中,m分布是介于生成分布与目标分布之间的,
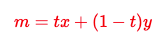
运用这种损失函数即可解决GAN在训练过程中的停滞的问题,而下面要介绍的waveGAN要优化的损失函数就是上面的WGAN-GP.
waveGAN是一种基于DCGAN(Deep Convolutional GAN)提出来的结构,尝试将GAN框架运用到语音合成任务上.网络在给定100维度的均匀噪声的基础上,通过不断迭代进行反卷积上采样,最终得到高分辨的16384维度的音频文件(稍微比采样率16000Hz的一秒钟音频长一点点).判别器则负责接受一个音频文件之后,通过不断的卷积操作,最终得到一个标量输出.
本文作者在原始的waveGAN基础上做了以下几点改进:
由于speech command dataset数据集在命令前后包含不少静音,为了避免GAN处理这个静音,作者从能量角度来做了一个阈值限制;笔者这里有一个疑问,为什么静音部分会不利于GAN处理?
作者并非提供随机噪声给生成器作为输入,而是使用一个非目标音频经过一个卷积-反卷积构成的自动编码器所得到的表征向量作为生成器的输入,这样可以提供跟输出具有类似结构的条件;
加了残差连接,在卷积-反卷积所构成的自动编码器中,在每一个对应的卷积与反卷积层之间建立一个捷径连接,这样既可以有效缓解梯度消失的问题,同时还起到了语音增强的效果;
使用了渐进式的细化训练方案,即首先让一个GAN产生一些样本,再将这些样本作为第二个GAN的输入来产生最终的音频,这样第二个GAN相当于起到了语音增强的作用;
实验表明本文的模型生成的音频要比原始的waveGAN更加接近真人的水平.同时作者也表示,该结构仍然存在一定的不稳定性,并且由于增加了渐进式的GAN,导致训练时间比较长.作者这里的渐进式跟我在看文章之前想象的完全不一样,我的想法是先产生8k Hz,再产生16k Hz,再产生24k Hz音频,这也是一种渐进式训练的思路.


