近期有哪些值得读的QA论文?| 专题论文解读

作者丨徐阿衡
学校丨卡耐基梅隆大学硕士
研究方向丨QA系统
知乎专栏丨徐阿衡-自然语言处理
FastQA

■ 论文 | Making Neural QA as Simple as Possible but not Simpler
■ 链接 | https://www.paperweekly.site/papers/835
■ 作者 | Dirk Weissenborn / Georg Wiese / Laura Seiffe
阅读理解系列的框架很多大同小异,但这篇 paper 真心觉得精彩,虽然并不是最新最 state-of-art。
现在大多数的阅读理解系统都是 top-down 的形式构建的,也就是说一开始就提出了一个很复杂的结构(一般经典的就是 emedding-, encoding-, interaction-, answer-layer),然后通过 ablation study,不断的减少一些模块配置来验证想法,大多数的创新点都在 interaction 层。
而这篇 paper 提供了抽取式 QA 基于神经网络的两个 baseline,BoW- 和 RNN-based nerual QA (FastQA) ,创新的以 bottom-up 的方式分析了框架复杂性以及主流 interaction layer 的作用。
一个基本认识,构建好的 QA 系统必不可少的两个要素是:
1. 在处理 context 时对 question words 的意识;
2. 有一个超越简单的 bag-of-words modeling 的函数,像是 RNN。
另外,作者还发现了很多看似复杂的问题其实通过简单的 context/type matching heruistic 就可以解出来了,过程是选择满足条件的 answer spans:
1. 与 question 对应的 answer type 匹配,比如说问 when 就回答 time;
2. 与重要的 question words 位置上临近,如下图的 St. Kazimierz Church。

FastQA 的表现对额外的复杂度,尤其是 interaction 的复杂交互,提出了质疑。
A BoW Neural QA System
比照传统思路来构建。
1. Embedding
词向量和字向量的拼接,字向量用 CNN 进行训练,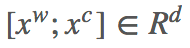
2. Type matching
抽取 question words 得到 lexical answer type (LAT)。抽哪些?
who, when, why, how, how many, etc.
what, which 后面的第一个名词短语,如 what year did…
将 LAT 的第一个和最后一个单词的 embedding,以及 LAT 所有单词的平均的 embedding 拼接起来,再通过全连接层和 tanh 做一个非线性变换得到 ẑ 。
用同样方法对每个 potential answer span (s, e) 做编码。所有 span,最长为 10 个单词,同样把 span 里第一个和最后一个单词的 embedding 和所有单词的 embedding 进行拼接,又因为 potential answer span 周围的单词会对 answer span type 提供线索(比如上文提到的 St. Kazimierz Church),所以额外的拼接了 span 往左、往右 5 个单词的平均 embedding,这样一共就是 5 个 embedding,接 FC 层和 tanh 非线性变换,得到 x̂s,e。
最后,拼接 LAT 和 span 的表示,[ẑ;x̂s,e;ẑ☉x̂s,e],用一个前馈网络计算每个 span (s,e) 和 LAT 的分数 gtype (s,e)。
3. Context Matching
引入两个 word-in-question 特征,对 context 中的每个单词 x_j:
binary
,如果 x_j 出现在了 question 中,就为 1,否则为 0。
weighted
计算 qi 和 xj 的词向量相似性。
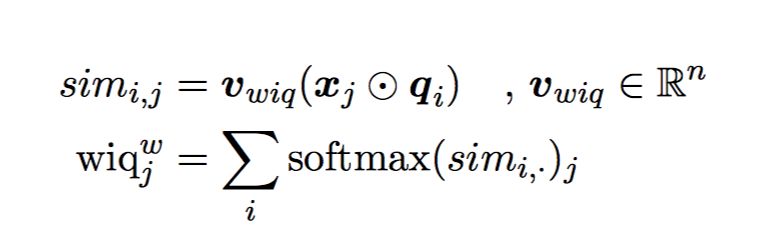
Softmax 保证了 infrequent occurrences of words are weighted more heavily.
对每个 answer span(s,e),计算往左、往右 5/10/20 token-windows 内和
的平均分数,也就是计算 2(kind of features) 3(windows) 2(left/right)=12个分数的加权和得到 context-matching score
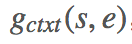
4. Answer span scoring
最后每个 span(s,e) 的分数就是 type matching score 和 context matching score 的和。
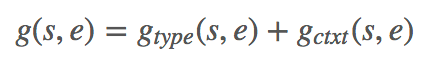
最小化 softmax-cross-entropy loss 进行训练。
FastQA
上面的方法中语义特征完全被缩减成了 answer-type 和 word-in-question features,另外 answer span 也受到了长度限制,对语义的捕捉很弱。
BiRNN 在识别 NER 上面非常有优势,context matching 也可以通过给 BiRNN 喂 wiq-features 得到,answer-type 会间接由网络学习得到。
模型相对简单,就三层 embedding-, encoding-, answer layer。

1. Embedding:和 BoW baseline 相同;
2. Encoding:为了让 question 和 context embedding 可以交互,先映射到 n 维向量,再过一个 highway layer。
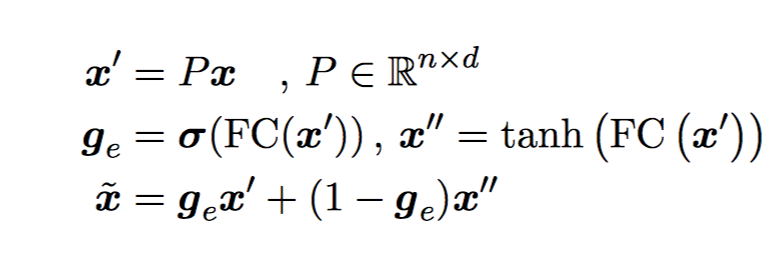
然后加上 wiq features。
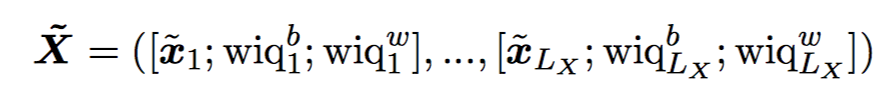
再一起过一个 BiRNN,输出再做个 projection。
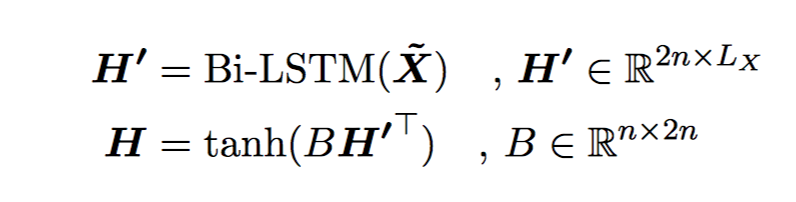
初始化 project matrix B 为 [In;In],In 是 n 维的 identity matrix,H 是 forawrd 和 backward LSTM 的输出的加和。
question 和 context 的参数共享,question 对应的两个 wiq 特征设为 1。projection matrix B 不共享。
3. Answer layer
context x H=[h1,…,hLX]
question Q Z=[Z1,…ZLQ]
对 Z 做一个变换,同样是 context-independent:
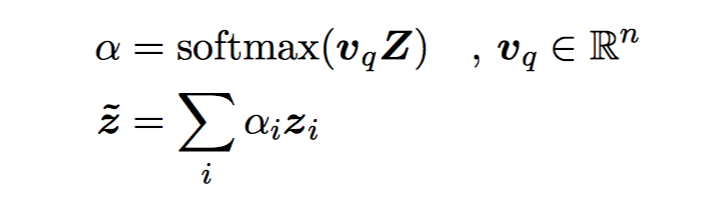
answer 的开始位置的概率 ps 由 2 个前馈网络加一个 ReLU 激活得到。
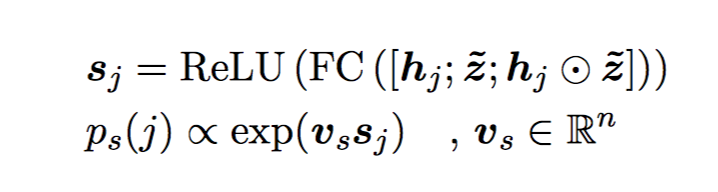
结束位置:
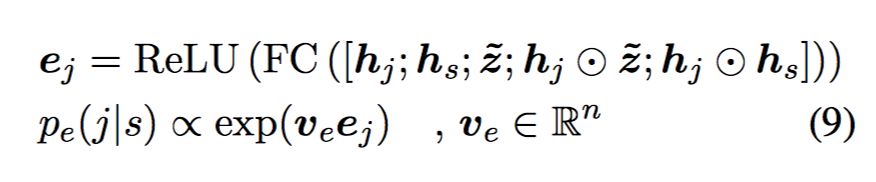
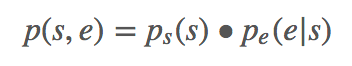
最小化 p(s,e) 的交叉熵来训练。在预测的时候,可以用 beam-search。
FastQA Extended
相当于主流模型的 interaction layer。对当前的 context state,考虑和剩下的 context(intra)或者和 question(inter)做注意力计算,将其余 context/question 的信息融入当前 context。
Intra-fustion: between passages of the context
Inter-fusion: between question and context
实验结果
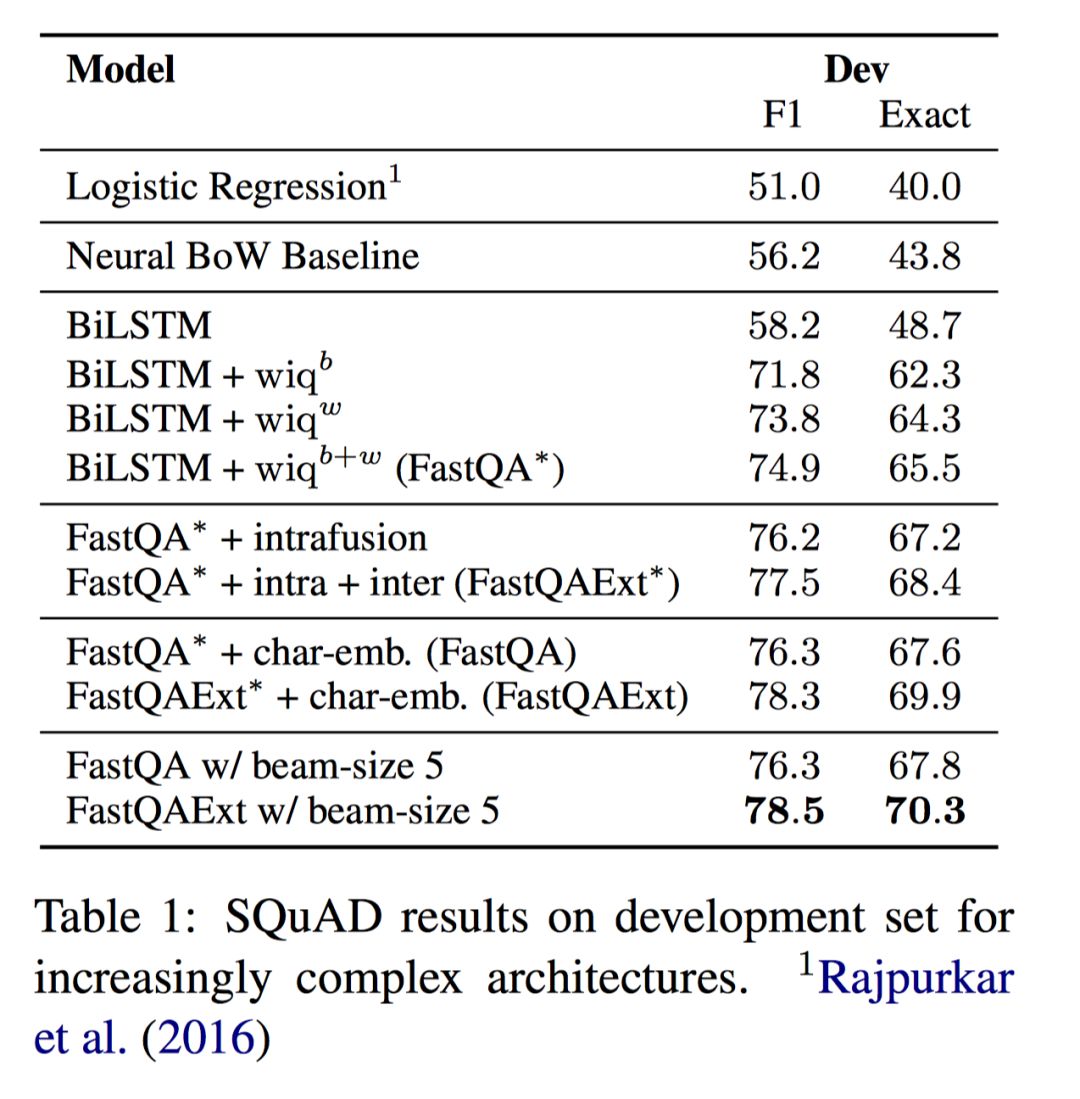
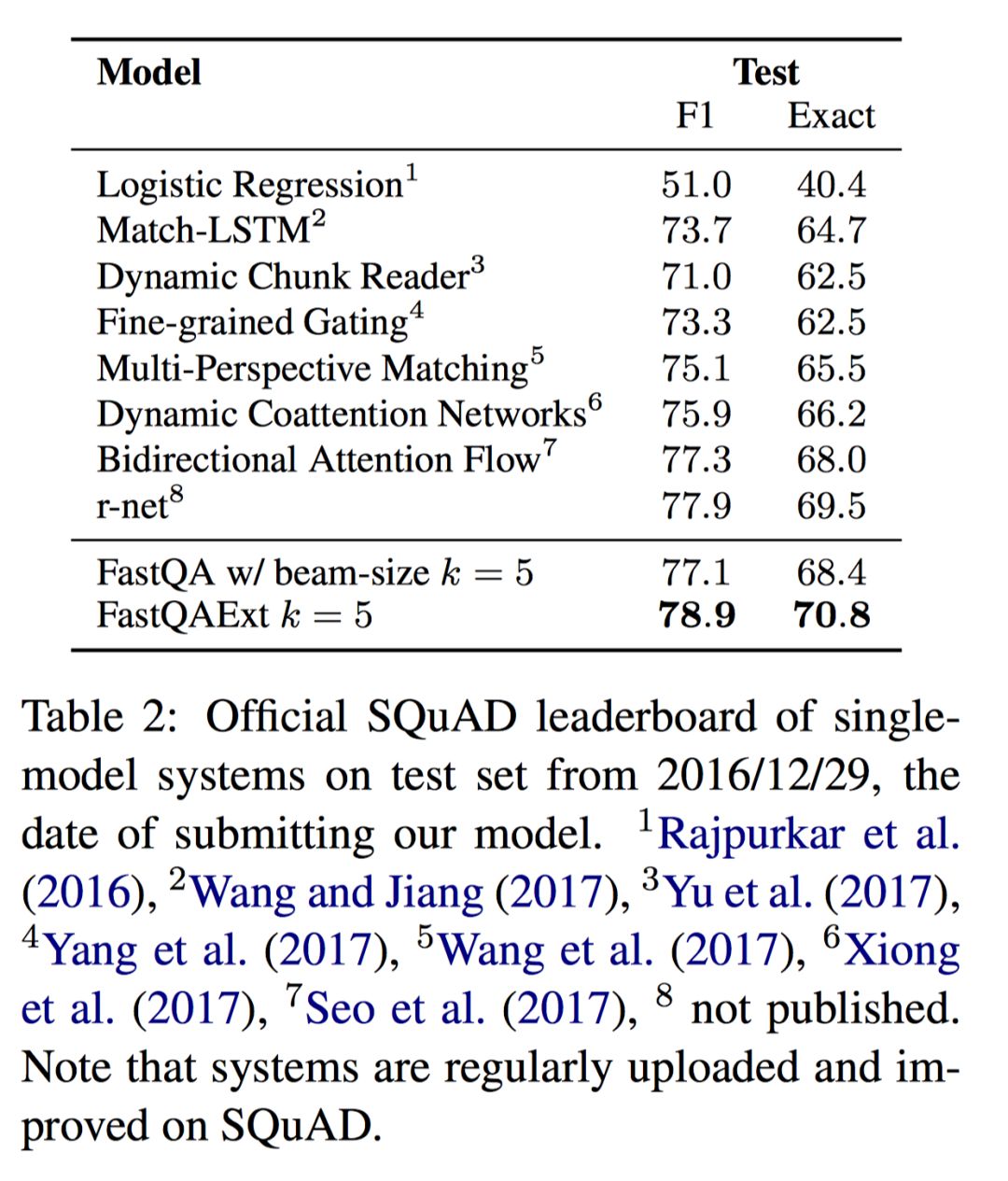
一些小结论:
1. 简单的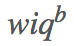
2. Beam-search 可以微弱提升结果,因为最可能的开始位置不一定是最好的 answer span;
3. 额外的 character embedding 对结果有显著提升;
4. 进一步的 fusion 对结果也有帮助,但并没有那么显著。
讨论:Do we need additional interaction?
对比试验,FastQA 与 FastQAExt 和 DCN 相比,快两倍,而且少 2-4 倍的显存。分析了结果发现 FastQAExt 泛化能力更强些,但并没有 systematic advantage,并不会对某类问题(主要分析了推理)有一致性的提升。
Qualitative Analysis
对 FastQA 的错误结果进行了一些分析,大部分的错误来自:
1. 缺乏对句法结构的理解;
2. 不同词位相似语义的词的细粒度语义之间的区分。
其他很多的错误也是来自人工标注偏好。
举了一些典型的错误例子,像例 1是缺乏对某些答案类型的细化理解。例 2 缺乏指代消解和上下文缩略语的认识,例 3 模型有时难以捕捉基本的句法结构,尤其是对于重要的分隔符如标点符号和连词被忽略的嵌套句子。

现有 top-down 模型用到实际业务当中通常需要为了 fit 进显存或者是满足一定的响应时间而进行模型的各种简化,FastQA 在显存占用和响应速度上有着绝对优势,感觉还是非常有意义的。
GDAN

■ 论文 | Semi-Supervised QA with Generative Domain-Adaptive Nets
■ 链接 | https://www.paperweekly.site/papers/576
■ 作者 | Zhilin Yang / Junjie Hu / Ruslan Salakhutdinov / William W. Cohen
GDAN,Question Generation 和 Question Answering 相结合,利用少量的有标注的 QA 对 + 大量的无标注的 QA 对来训练 QA 模型。
Introduction
看到这篇论文,看到来自 CMU,就忍不住推测作者估计是 LTI 的,估计还上过 411/611/711,毕竟 idea 和 final project 太像了。
回顾下 CMU 11411/611/711 的 final project,项目是阅读理解,分为 Asking System 和 Answering System 两个子系统。17年初的时候,Alan 鼓励用课上学到的东西 & 隐晦的不鼓励用 DL,anyway 那时候也并没有看到用 DL 做 QG 的 paper,网上唯几和 QG 相关的 paper 都是 CMU 的,估计和这门课相辅相成。
611 的 asking system 和 answering system 都没有标注,只是纯粹的 wiki 文本,asking system 基于 document 产生 question 以及 answer,answering system 根据 question 和 document 产生 answer。
因为没有标注,所以两个系统其实是相互补充相互促进的。如果产生的 question 太简单,和原文太过相近,那么 answering system 的泛化能力有可能就很差,而如果 question 太难,answering system 也就学很难学习很难训练。
评价产生的 question 的好坏的标准除了流畅、符合语法等基于 question 本身的特点外,我们还希望好的问题能找到答案,这些逻辑在这篇论文中都有所体现。
回到 paper,主要思想其实就是用少量的有标注的 QA 对 + 大量的无标注的 QA 对来训练 QA 模型。主要做法是,给部分 unlabelled text,用 tagger 抽一些答案,训练 generative model 来生成对应的问题,然后补充训练集,再训练 QA model。实际是用改进的 GAN 方法来构建一个半监督问答模型。
Model Architecture
Generative Model - seq2seq with attention and copy
对 P(q|p,a) 进行建模。输入是 unlabelled text p 和从中抽取的答案 a,输出是 q,或者说 (q, p, a)。答案 a 的抽取依赖 POS tagger + constituency parser + NER tagger。生成模型这里用的是 seq2seq model (Sutskever et al., 2014) + copy mechanism (Gu et al., 2016; Gulcehre et al., 2016)。
Encoder 用一个 GRU 把 paragraph 编码成 sequence of hidden states H。注意论文在 paragraph token 的词向量上加了额外的一维特征来表示这个词是否在答案中出现,如果出现就为 1,否则为 0。
Decoder 用另一个 GRU + Attention 对 H 进行解码,在每一个时刻,生成/复制单词的概率是:
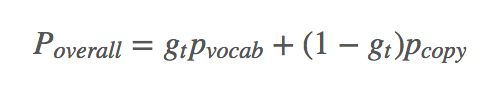
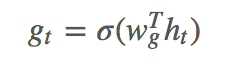
具体细节不多说了,相关可以看 Copy or Generate。
生成模型 G 产生的 (q, p, a) 作为判别模型的输入。
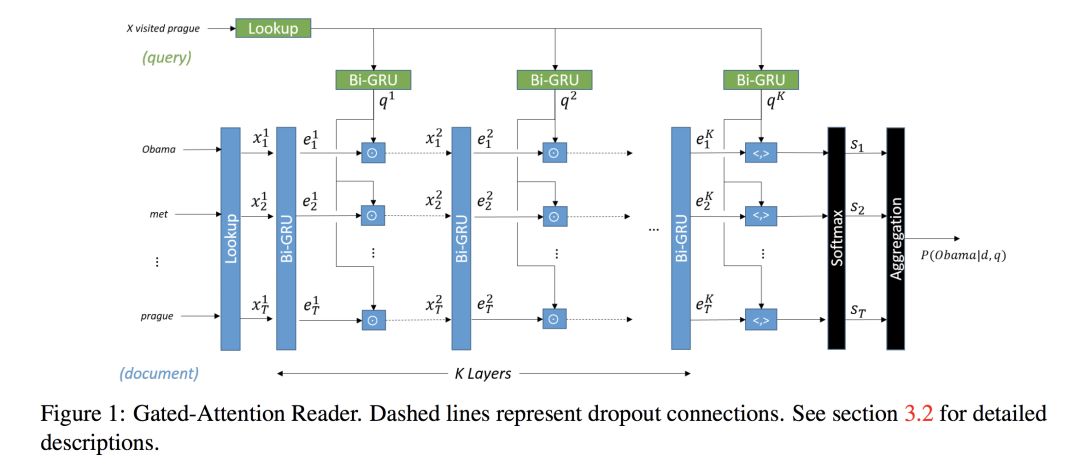
Discriminative Model - gated-attention reader
对 P(a|p,q) 进行建模。输入是人为标注数据 L 以及模型产生的数据 U,由于 L 和 U 来自不同分布,所以引入了 domain tag 来区分两类数据,“true”来表示人为标记数据 L,“gen”标签来表示模型生成数据 U(Johnson et al., 2016; Chu et al., 2017)。在测试时,只加入 d_true。
论文这里用了 GA (gated-attention) Reader 作为基本结构,也是 CMU 出的模型,当然事实上别的模型也可以。
模型很简单,embedding 层用词向量,encoder 层用双向 GRU 分别得到 Hq 和,context-query attention 层用 gated attention (
, Hq 做 element-wise 乘法)做下一层网络的输入,重复进入 encoder 和 attention 层进行编码和乘法(共 k 层),最后将 p, q 做內积(inner product)得到一个最终向量输入 output 层,output 层用两个 softmax 分别预测答案在段落中的起始和结束位置。
Loss function
整体的目标函数:
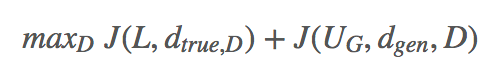
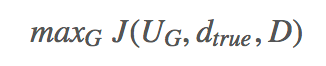
Training Algorithm
主要要解决下面两个问题:
Issue 1: discrepancy between datasets
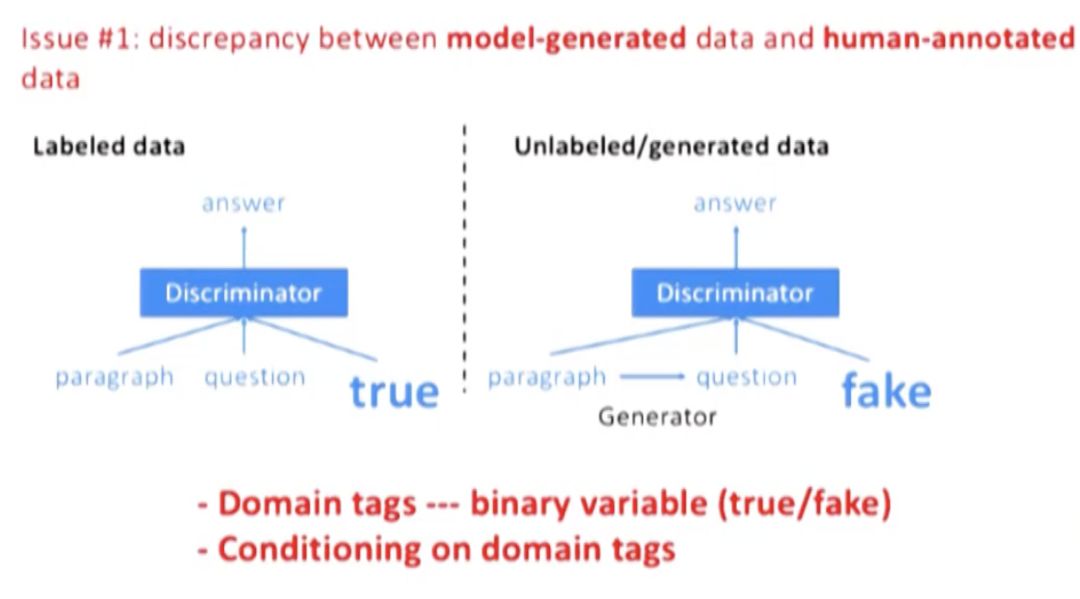
如上,判别模型很容易在 U 上 overfit,所以才用了 domain tag 做区分。
Issue 2: jointly train G and D
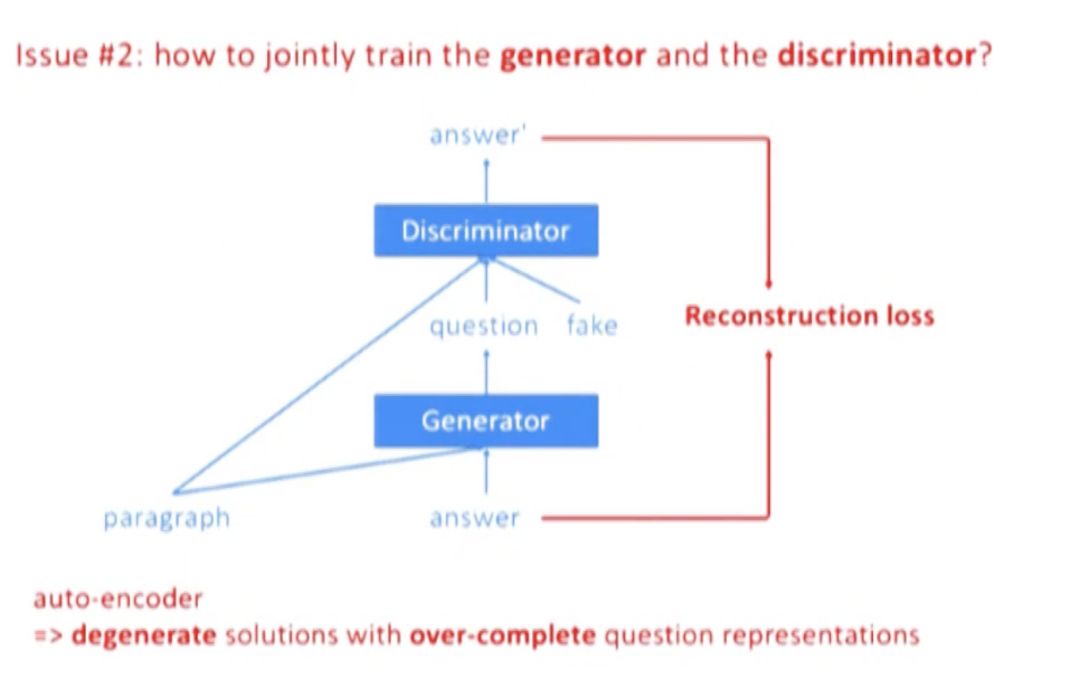
如上,如果用 auto-encoder,容易让 question 和 answer 的表达非常接近,question 甚至可能完全 copy answer,所以这里用了判别模型。
Intuitively, the goal of G is to generate “useful” questions where the usefulness is measured by the probability that the generated questions can be answered correctly by D
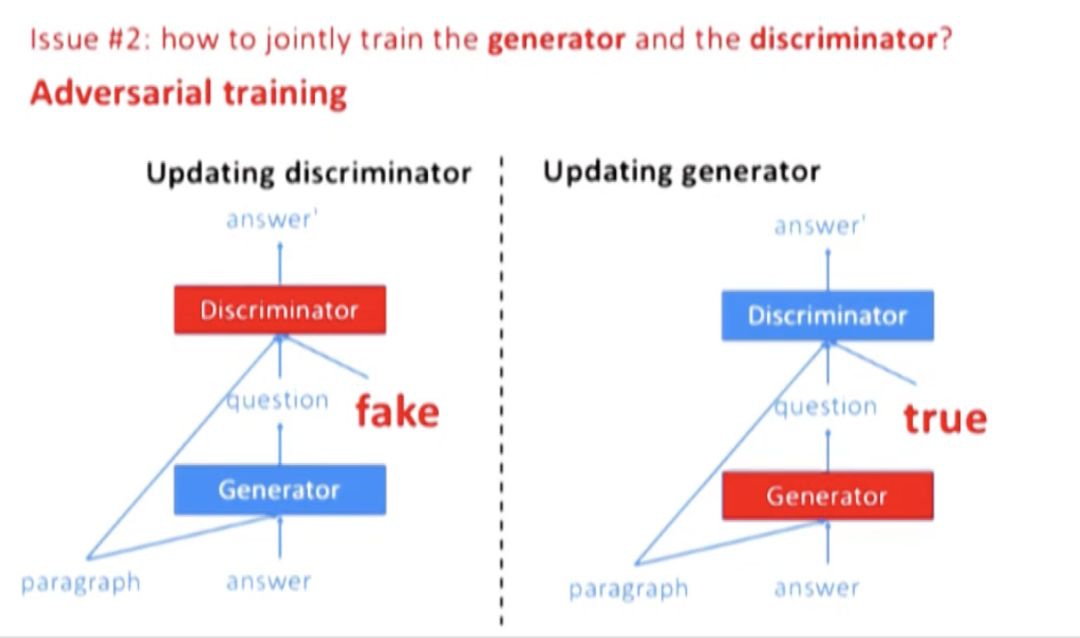
Algorithm
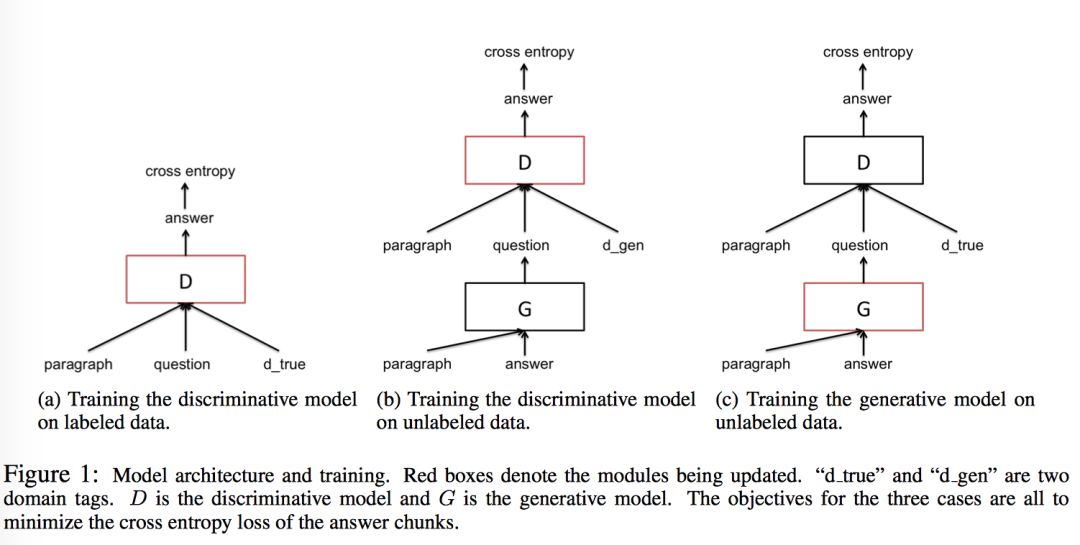
分两个阶段:
第一阶段:固定 G,利用 d_true 和 d_gen,用 SGD 来更新 D。在 L 上计算 MLE 来完成 G 的初始化,对 D 进行随机初始化。
第二阶段:固定 D,利用 d_true,用 RL 和 SGD 更新 G。由于 G 的输出是不可导的,所以用到了 reinforce algorithm。action space 是长度为 T’ 的所有可能的 questions,reward 是 J (UG,dtrue,D)。

Summary
QANet 那篇论文中提到了另一篇 Question Generation 的论文:
Zhou et al. (2017) improved the diversity of the SQuAD data by generating more questions. However, as reported by Wang et al. (2017), their method did not help improve the performance.
相信 GDAN 在一定程度上一定能缓解 QA 中标注数据稀少的问题,但是能否在数据较为充足,模型较为优势的情况下提升 performance,估计难说,下次尝试后再来填这个坑了。Anyway,看到了曾经思考过的问题有人做出了实践还是万分开心的。
QANet

■ 论文 | QANet - Combining Local Convolution with Global Self-Attention for Reading Comprehension
■ 链接 | https://www.paperweekly.site/papers/1901
■ 源码 | https://github.com/NLPLearn/QANet
CMU 和 Google Brain 新出的文章,SQuAD 目前的并列第一,两大特点:
1. 模型方面创新的用 CNN+attention 来完成阅读理解任务。
在编码层放弃了 RNN,只采用 CNN 和 self-attention。CNN 捕捉文本的局部结构信息( local interactions),self-attention 捕捉全局关系( global interactions),在没有牺牲准确率的情况下,加速了训练(训练速度提升了 3x-13x,预测速度提升 4x-9x)。
2. 数据增强方面通过神经翻译模型(把英语翻译成外语(德语/法语)再翻译回英语)的方式来扩充训练语料,增加文本多样性。
其实目前多数 NLP 的任务都可以用 word vector + RNN + attention 的结构来取得不错的效果,虽然我挺偏好 CNN 并坚定相信 CNN 在 NLP 中的作用(捕捉局部相关性&方便并行),但多数情况下也是跟着主流走并没有完全舍弃过 RNN,这篇论文还是给了我们很多想象空间的。
Model Architecture
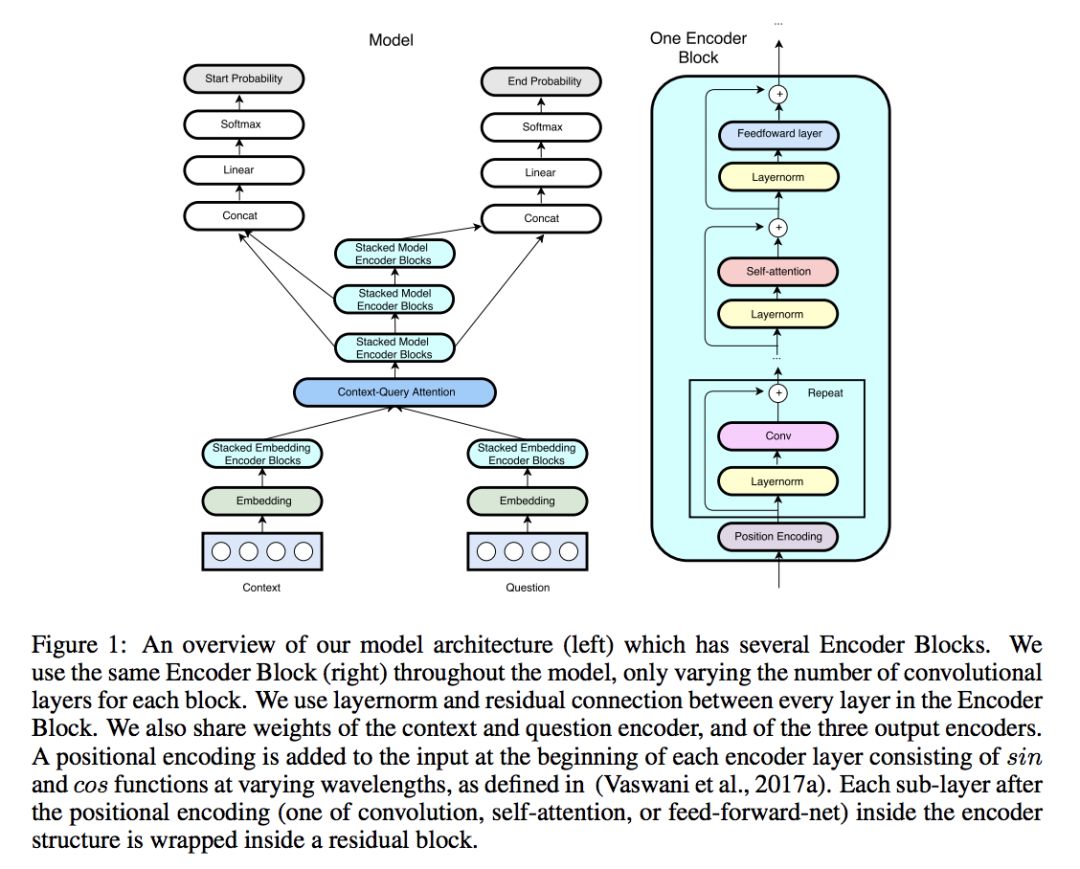
先看模型,在 BiDAF 基础上的一些改进,主要在 embedding encoder 层。还是阅读理解经典五层结构:
1. Input embedding layer
和其他模型差不多,word embedding + character embedding,预训练词向量,OOV 和字向量可训练,字向量用 CNN 训练。
单词 w 的表示由词向量和字向量的拼接 [xw;xc]∈Rp1+p2 然后经过两层 highway network 得到,这个和 BiDAF 相同。
2. Embedding encoder layer
重点是这一层上的改变,由几个基本 block 堆叠而成,每个 block 的结构是:
[convolution-layer x # + self-attention-layer + feed-forward-layer]
卷积用的 separable convolutions 而不是传统的 convolution,因为更加 memory efficient,泛化能力也更强。核心思想是将一个完整的卷积运算分解为 Depthwise Convolution 和 Pointwise Convolution 两步进行,两幅图简单过一下概念。
先做 depthwise conv, 卷积在二维平面进行,filter 数量等于上一次的 depth/channel,相当于对输入的每个 channel 独立进行卷积运算,然后就结束了,这里没有 ReLU。
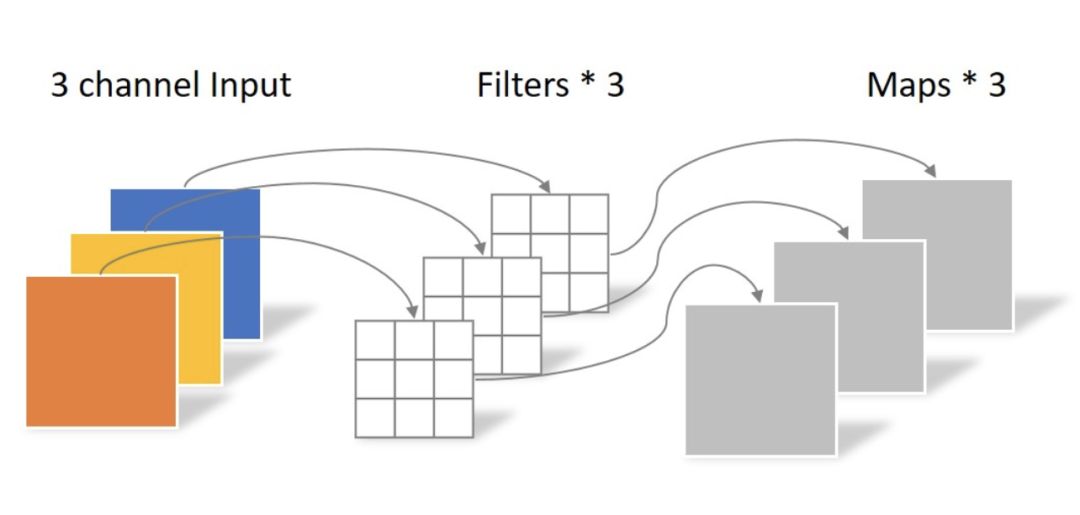
然后做 pointwsie conv,和常规卷积相似,卷积核尺寸是 1x1xM,M 为上一层的 depth,相当于将上一步depthwise conv 得到的 map 在深度上进行加权组合,生成新的 feature map。
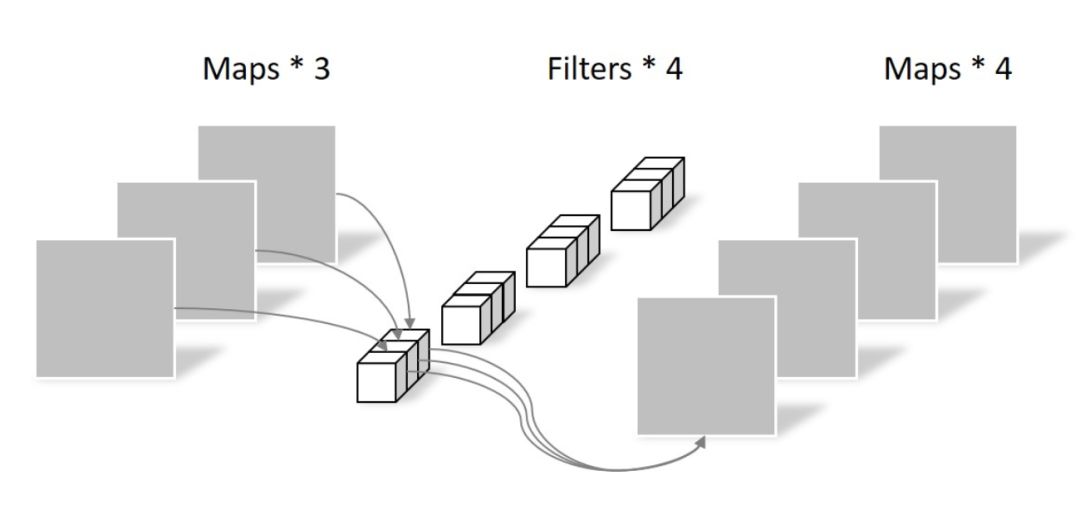
Self-attention-layer 用的是多头注意力机制(head=8),常用的也不多说了。
注意的是这里每个基本运算(conv/self-attention/ffn)之间是残差连接,对输入 x 和操作 f,输出是 f (layernorm(x))+x,也就是说某一层的输出能够直接跨越几层作为后面某一层的输入,有效避免了信息损失 4 个卷积层,1 个 encoding block。
3. Context-query attention layer
几乎所有 machine reading comprehension 模型都会有,而这里依旧用了 context-to-query 以及 query-to-context 两个方向的 attention,先计算相关性矩阵,再归一化计算 attention 分数,最后与原始矩阵相乘得到修正的向量矩阵。相似度函数这里用的:
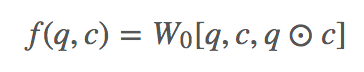
对行、列分别做归一化得到 S’ 和 S’’,最后 context-to-query attention 就是 A=S′QT,query-to-context attention 就是 B=S′S″TCT,用了 DCN attention 的策略。
4. Model encoder layer
和 BiDAF 差不多,不过这里依旧用 CNN 而不是 RNN。这一层的每个位置的输入是 [c, a, c⊙a, c⊙b],a, b 是 attention 矩阵 A,B 的行,参数和 embedding encoder layer 相同,除了 cnn 层数不一样,这里是每个 block 2 层卷积,一共 7 个 block。
5. Output layer
再次和 BiDAF 相同:
p1=softmax(W1[M0;M1]),p2=softmax(W2[M0;M2])
目标函数:
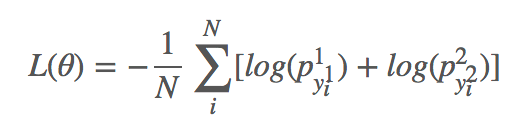
其中和
分别是第 i 个样本的 groundtruth 的开始和结束位置。
Data Augmentation
CNN 速度快所以有条件用更多的数据来训练啦,然后进一步增强模型的泛化能力啦。这里数据增强的基本 idea 就是通过 NMT 把数据从英文翻译成法文(English-to-French),另一个翻译模型再把法文翻回英文(French-to-English)。
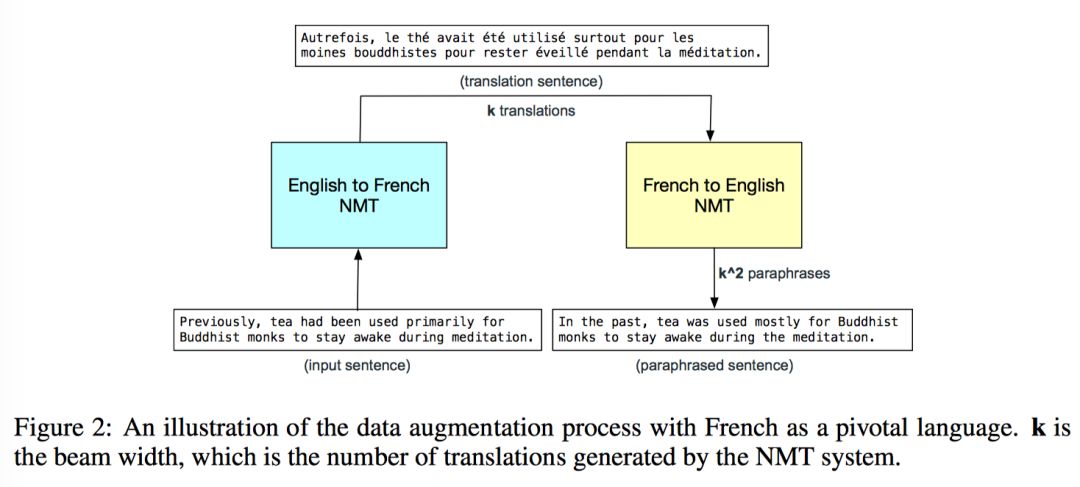
看图说话,对段落中每个句子先用 English-to-French 模型的 beam decoder 得到 k 个法语翻译,然后对每一条翻译,都再经过一个 reversed translation model 的 beam decoder,这最后就得到了 k^2 个改写的句子(paraphrases),然后从这 k^2 个句子中随机选一个。
具体到 SQuAD 任务就是 (d,q,a) -> (d’, q, a’),问题不变,对文档 d 翻译改写,由于改写后原始答案 a 现在可能已经不在改写后的段落 d’ 里了,所以需要从改写后的段落 d’ 里抽取新的答案 a’,采用的方法是计算 s’ 里每个单词和原始答案里 start/end words 之间的 character-level 2-gram score,分数最高的单词就被选择为新答案 a’ 的 start/end word。
这个方法还可以从 quality 和 diversity 改进,quality 方面用更好的翻译模型,diversity 方面可以考虑引入问题的改写,也可以使用其他的数据增广的方法(Raiman&Miller, 2017)。
实验结论是英文语料:法语语料:德语语料是 3:1:1 的比例时效果最好,EM 提升了 1.5,F1 提升了 1.1。
Question Generation

■ 论文 | Machine Comprehension by Text-to-Text Neural Question Generation
■ 链接 | https://www.paperweekly.site/papers/330
■ 作者 | Xingdi Yuan / Tong Wang / Caglar Gulcehre / Alessandro Sordoni / Philip Bachman / Sandeep Subramanian / Saizheng Zhang / Adam Trischler
QG 的应用还是挺广泛的,像是为 QA 任务产生训练数据、自动合成 FAQ 文档、自动辅导系统(automatic tutoring systems)等。
传统工作主要是利用句法树或者知识库,基于规则来产生问题。如基于语法(Heilman and Smith, 2010; Ali et al., 2010; Kumar et al., 2015),基于语义(Mannem et al., 2010; Lindberg et al., 2013),大多是利用规则操作句法树来形成问句。还有是基于模板(templates),定好 slot,然后从文档中找到实体来填充模板(Lindberg et al., 2013; Chali and Golestanirad, 2016)。
深度学习方面的工作不多,有意思的有下面几篇:
1. Generating factoid questions with recurrent neural networks: The 30m factoid question-answer corpus
将 KB 三元组转化为问句
2. Generating natural questions about an image
从图片生成问题
3. Semi-supervised QA with generative domain-adaptive nets
用 domain-adaptive networks 的方法做 QA 的数据增强
神经网络做 QG 基本套路还是 encoder-decoder 模型,对 P(q|d) 或者 P(q|d, a) 进行建模。像是 17年 ACL 的 paper Learning to Ask: Neural Question Generation for Reading Comprehension,就是用一个基本的 attention-based seq2seq 模型对 P(q|d) 进行建模,并在 encoder 引入了句子和段落级的编码。
这一篇 Microsoft Maluuba 出的 paper 把 answer 作为先验知识,对 P(q|d, a) 进行建模。同时用监督学习和强化学习结合的方法来训练 QG,先用最大似然预训练一波,然后用 policy gradient 方法进行 fine-tune ,最大化能反映问题质量的一些 rewards。
Encoder-Decoder Model
基础架构是 encoder-decoder,加了 attention mechanism (Bahdanau et al. 2015)和 pointer-softmax coping mechanism (Gulcehre et al. 2016)。
Encoder
输入:
document D=(d1,…,dn)
answer A=(a1,…,am)
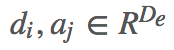
在文档词向量后面拼了个二维特征表示文档单词是否在答案中出现。然后过 Bi-LSTM 对文档表示进行编码得到 annotation vectors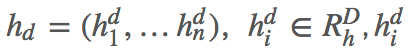
接着对 answer 编码。主要根据 answer 在 document 的位置找到对应的 annotation vector,然后把它和 answer 的词向量拼接起来也就是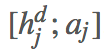
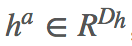
计算 decoder 的初始状态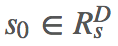
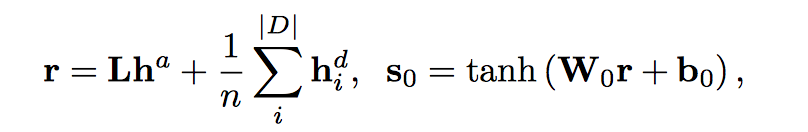
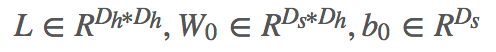
Decoder
解码器产生输出,输出单词从 pθ(yt|y<t,D,A) 分布中得到。
为了在问句中直接产生文档中的一些短语和实体,在 decoder 的时候采用了 pointer-softmax,也就是两个输出层,shortlist softmax 和 location softmax,shortlist softmax 就是传统的 softmax,产生 predefined output vocabulary,对应 copynet 中的 generate-mode,location softmax 则表示某个词在输入端的位置,对应 copynet 中的 copy-mode。
Decoder:
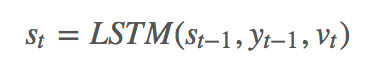
vt 是从 document 和 answer encoding 计算得到的 context vector,用了 attention 机制,atj 同时可以用作location softmax。
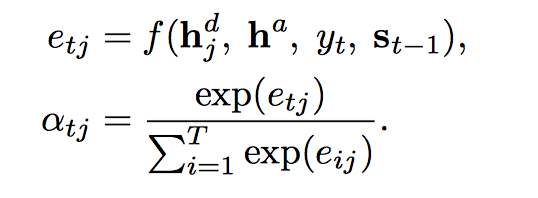
context vector:
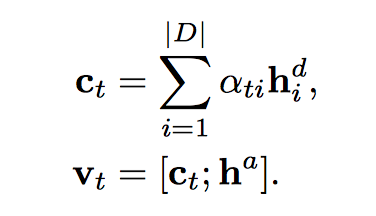
shortlist softmax vector ot 用了 deep output layer (Pascanu et al., 2013)。
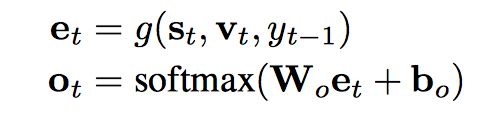
最后的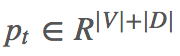
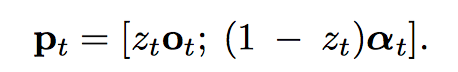
Training
三个 loss:
1. negative log-likelihood
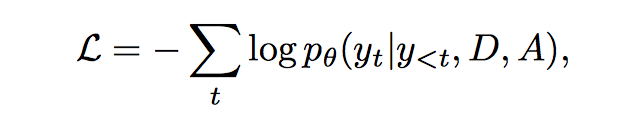
用了 teacher forcing,也就是 yt−1 不是从模型输出得到的,而是来自 source sequence。
2. not to generate answer words in question
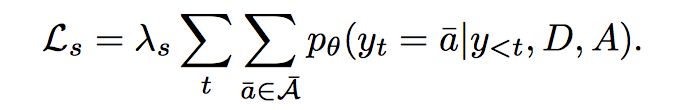
â 表示在 answer 中出现但没有在 groud-truth question 中出现的单词。
3. Variety
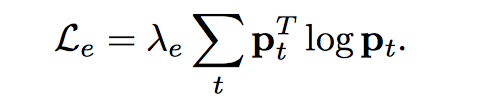
最大化信息熵来鼓励输出多样性。
Policy Gradient Optimization
Teacher forcing 会带来一个问题,训练阶段和测试阶段的结果会存在很大差异。在训练阶段,tearcher force 使得模型不能从错误中学习,因为最大化 groud-truth likelihood 并不能教模型给没有 groud-truth 的 example 分配概率。于是就有了 RL 方法。在预训练一波 maximum likelihood 之后,使用一些和问题质量相关的 rewards,来进行 policy gradient optimzation。
Rewards
1. Question answering
好的问题能被回复,把 model-generated question 喂给预训练好的 QA 系统(论文用的 MPCM 模型),然后用 QA 系统的 accuracy(比如 F1) 作为 reward。
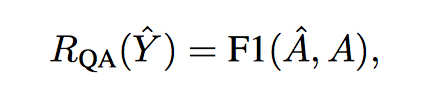
2. Fluency (PPL)
是否符合语法,过一个语言模型计算 perplexity。
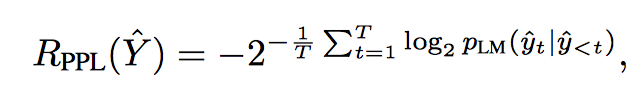
3. Combination
两者加权。
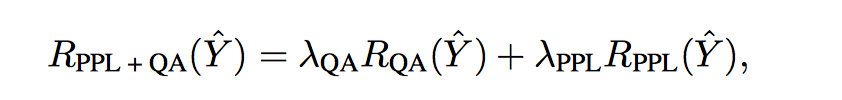
Reinforce
“loss”:
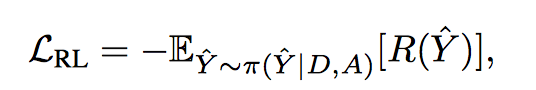
π 是要训练的 policy,是action 的概率分布,action space 就是 decoder output layer 的词汇表,可以通过 beam-search 采样选择 action,采样结果通过 decoder teacher-force 还原得到 state,计算 reward 进行梯度更新。
Policy gradient:
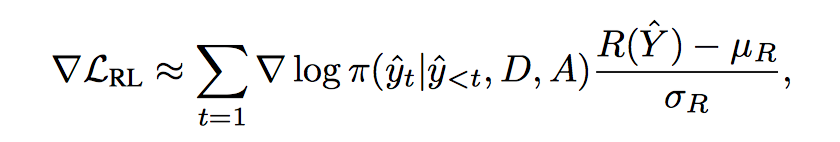
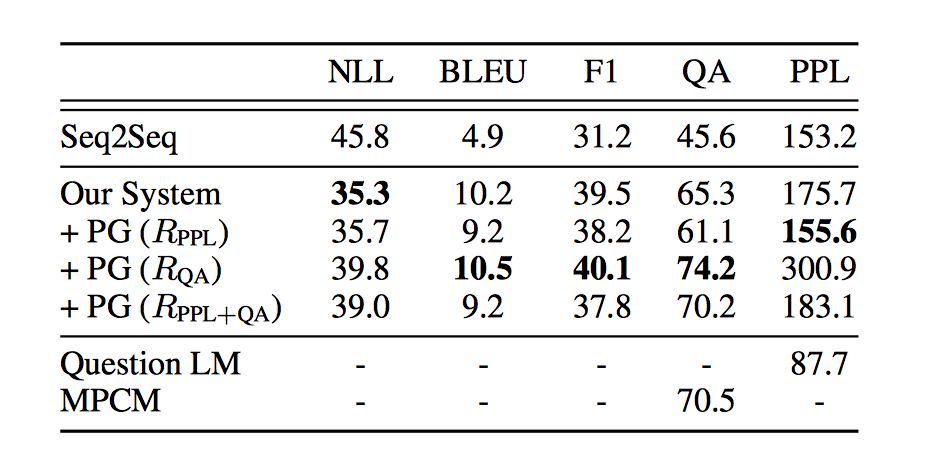
Evaluation
Baseline Seq2Seq 可以产生更符合语法更流畅的英文问题,但是语义可能更加模糊,这篇 paper 提出的系统可以产生更具体的问题,虽然没那么流畅。


点击以下标题查看更多文章:

▲ 戳我查看招募详情

关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。

▽ 点击 | 阅读原文 | 进入作者博客




