「紫禁之巅」四大图神经网络架构
近年来,人们对深度学习方法在图数据上的扩展越来越感兴趣。在深度学习的成功推动下,研究人员借鉴了卷积网络、循环网络和深度自动编码器的思想,定义和设计了用于处理图数据的神经网络结构。图神经网络的火热使得各大公司纷纷推出其针对图形结构数据的神经网络框架。下面分别介绍四大图神经网络框架。

东邪-Deep Graph Library(DGL)
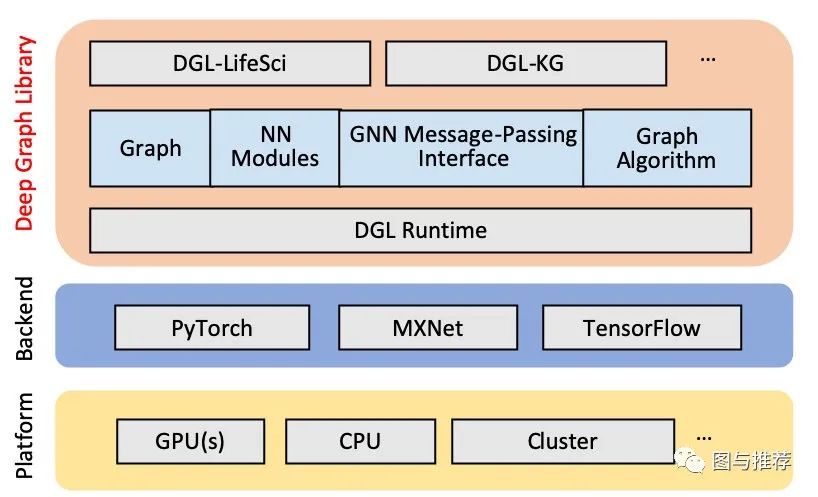
由New York University(NYU)和Amazon Web Services(AWS)联合推出的图神经网络框架。创立之初,本着避免重复造轮子的原则,DGL基于主流框架进行开发,即框架上的框架。目前,DGL已经支持PyTorch、MXNet和TensorFlow作为其后端。
消息传递是图计算的经典编程模型。DGL采用了基于「消息传递」的编程模型。通过message function和 reduce function,每个节点获得所有邻居节点的特征信息之和,并经过一个非线性函数得到该节点新的表示。
如今已发布至0.4版本的DGL更是全面上线对于异质图支持模块,复现并开源了相关异质图神经网络的代码,如HAN、Metapath2vec等。而其他两大框架尚未支持异质图相关的表示学习方法。此外,DGL也发布了训练知识图谱嵌入(Knowledge Graph Embedding)专用包DGL-KE,并在许多经典的图嵌入模型上进一步优化了性能。
西毒-PyTorch Geometric(PyG)

由德国多特蒙德工业大学研究者推出的基于PyTorch的几何深度学习扩展库。该库已获得Yann LeCun的点赞:“A fast & nice-looking PyTorch library for geometric deep learning。”
在其Github主页上展示的已实现的模型可谓琳琅满目,细数将近五十种。在简单的消息传递API之后,它将大多数近期提出的卷积层和池化层捆绑成一个统一的框架。与此同时,所有已实现方法都支持CPU和GPU计算,在遵循不变的数据流范式的基础上利用专门的CUDA内核实现高性能。此外,它还包含一个易于使用的 mini-batch 加载器、多 GPU 支持、大量通用基准数据集和常用转换等,既可以学习任意图形,也可以学习 3D 网格或点云。
PyG目前支持大量常见基准数据集,它们均可在第一次初始化时自动下载和处理。具体而言,PyG提供60多个 graph kernel 基准数据集 (Kersting et al., 2016),如 PROTEINS 或 IMDB-BINARY、引用网络数据集 Cora、CiteSeer。此外,PyG还提供嵌入式数据集,如MNIST超像素 (Monti et al., 2017)、COMA (Ranjan et al., 2018),以及 PCPNet 数据集 (Guerrero et al., 2018)。
所有面向用户的API(如数据加载路径、多GPU支持、数据增强或模型实例化)都借鉴了PyTorch的常用模式,以让用户尽可能地快速熟悉它们。这无疑对于PyTorch用户来说是极大利好。
南帝-Ant Graph machine Learning system(AGL)

由阿里的蚂蚁金服团队推出的大规模图机器学习系统。在具有六十亿节点、三千亿边的网络中,训练两层GAT耗费14小时,完成整个图的推断需要1.2小时。
上面提到的DGL与PyG均是在单机系统下处理工业规模级的图。该系统在单机情况下已经成功加速了GNN的训练,并且在实际产品场景中使用CPU集群得到了近乎线性的提升。
AGL使用了大规模并行框架(如MapReduce、Parameter Server)来设计其分布式组件,GraphFlat、GraphTrainer和GraphInfer。同样使用消息传递机制,在GraphFlat组件中,通过聚合K跳邻居的节点信息来生成目标节点的表示。通过邻居聚合,将大规模的图进行分解,每次导入一个或者批量的点来缓解内存的压力。由于聚合的邻居信息提供了充分的信息量,所以节点之间相互独立。即在GraphTrainer中,每一个worker只需处理自己的部分,所以不再需要额外的通信开销。除此之外,训练过程还包括许多优化来提高训练效率,如训练管道、网络剪枝、边的分割等。在推断阶段,GraphInfer提供了一种分层模型切片,利用MapReduce管道以从较低层推断到较高层。具体来说,第k层的Reduce阶段载入第k层的模型切片,合并上一层的聚合in-edge邻居的embedding从而生成第k层的embedding,然后将这些中间embedding通过out-edge传到目标节点,为下一Reduce阶段做好准备。
北丐-tf_geometric
受到PyG启发,为GNN创建了TensoFlow版本。同样使用消息传递机制,将会比普通矩阵运算更为高效、比稀疏矩阵更为友好。在其Github开源的demo中,可以看到GAE、GCN、GAT等主流的模型已经实现。与此同时,它还提供了面向对象和函数式API。该框架可能推出时间不长,内容略显单薄,也期待其能推出更多的功能与模型支持。
DGL与PyG对比
批处理
Mini-batch:
PyG 可自动创建单个(稀疏)分块对角邻接矩阵(block-diagonal adjacency matrix),并在节点维度中将特征矩阵级联起来,从而支持对多个(不同大小)图实例的小批量处理。
Auto-batching:
对于单一静态图,DGL 通过分析图结构能够高效地将可以并行的节点分组,然后调用用户自定义函数进行批处理,从而高效并行计算多个节点或者多条边。对于处理许多图的模型(比如 module graph),将多张图合并为一张大图的多个连通分量,从而将该类模型转化为了单一静态图。对于巨图模型(比如 knowledge graph),DGL 提供了高效的图采样接口,将巨图变为小图样本,从而转化为单一静态图。
规模
DGL提到在内存允许的实例下,单机能跑5亿节点、250亿边的情况。PyG尚未提到其在大型图的实现及其数据效率。
效率
PyG在推出之时与DGL进行了比较,根据其论文中给出的数据,也近乎是碾压了DGL。更有机器之心的报道《比DGL快14倍:PyTorch图神经网络库PyG上线了》,盖棺定论的说法有失偏颇,也颇有标题党的味道。当时被碾压的DGL是0.1版本,自然是无法与有许多内核的PyG比较。紧随其后,DGL写了自己的内核,在效率上得到了极大提升。如下图所示,根据DGL在小型基准数据集上与PyG的比较,在速率上相当,内存管理上DGL会略占优势。
| Dataset | Model | Accuracy | Time PyG DGL |
Memory PyG DGL |
|---|---|---|---|---|
| Cora | GCN GAT |
81.31 ± 0.88 83.98 ± 0.52 |
0.478 0.666 1.608 1.399 |
1.1 1.1 1.2 1.1 |
| CiteSeer | GCN GAT |
70.98 ± 0.68 69.96 ± 0.53 |
0.490 0.674 1.606 1.399 |
1.1 1.1 1.3 1.1 |
| PubMed | GCN GAT |
79.00 ± 0.41 77.65 ± 0.32 |
0.491 0.690 1.946 1.393 |
1.1 1.1 1.6 1.1 |
| GCN | 93.46 ± 0.06 | OOM 28.6 | OOM 11.7 | |
| Reddit-S | GCN | N/A | 29.12 9.44 | 15.7 3.6 |
灵活性
尽管PyG已实现近五十种模型,但因是PyTorch的扩展库,所以均是在PyTorch上实现。DGL在PyTorch、MXNet和TensorFlow已实现了三十多种模型,还实现了多种sampling方法,对于构建自己的模型更具灵活性。
相关链接
DGL:
主页:https://www.dgl.ai/
Github:https://github.com/dmlc/dgl
文档:https://docs.dgl.ai/
PyG:
Github:https://github.com/rusty1s/pytorch_geometric
文档:https://pytorch-geometric.readthedocs.io/
tf_geometric:
Github:https://github.com/CrawlScript/tf_geometric
文档:https://tf-geometric.readthedocs.io/


