基于深度学习的单视图三维重建算法学习路线

极市导读
作者从2018年开始接触基于深度学习的单视图三维重建算法,中间因为考研等原因休息了一年,毕业设计也是关于这方面的内容。在学习的过程中,踩过很多坑,也学到了很多东西。作者将学习路线记录如下,也算是对本科学习的一个总结。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
一 基础知识
1.英语:下面给出的论文是全英文,可以培养阅读能力,建议少用翻译软件。
2.高等数学:非常重要,例如梯度下降公式涉及求导。
3.线性代数:非常重要,例如图像就是以矩阵的形式表示。
4.算法分析与设计:要有基本的算法思想,例如怎么减少时间复杂度和空间复杂度。
5.Python:这个不用说,基础的语法要会。推荐小甲鱼的python视频,B站搜:小甲鱼,P54之后的可以不用看。书籍推荐《Python编程 从入门到实践》。
6.Pytorch:大部分三维重建算法都是利用pytorch实现,推荐莫烦的pytorch,B站搜:莫烦python。书籍推荐《深度学习框架PyTorch:入门与实践》。
二 进阶知识
1.Linux基本操作:大部分代码涉及到编译的过程,需要在Linux系统上面运行。同时这类算法的网络结构都比较大,代码基本上都是在服务器上面跑,需要了解如何使用服务器。书籍推荐《鸟哥的Linux私房菜》。
2.计算机图形学:主要是渲染相关知识,如何从三维模型得到二维图像是三维重建算法的一个重要问题,后面列举的论文基本上都涉及到这个过程。视频推荐B站:GAMES101,看评论就知道老师有多厉害,暂时只看到了P9,感兴趣的可以往后面看。
3.基于深度学习的最新三维重建算法综述:这篇论文对近几年三维重建相关工作做了详细的总结,例如网络结构、输入输出、数据集等。在阅读下面的论文之前,可以先看看这个,对所有的三维重建算法有一个大致的了解。论文链接:https://arxiv.org/pdf/1906.06543v3.pdf
4.数据集:后续算法使用了两个数据集,一个是ShapeNet,这个数据集很大,只有三维模型,需要经过渲染才能够得到二维图像。第二个是PASCAL3D+,这也是一个比较出名的数据集。
5.打开三维模型的软件:后续三维模型基本上都是使用网格的表示方法。可以用Windows系统自带的3D查看器和Print 3D,Linux系统需要安装meshlab,也可以使用python的vtk库进行查看。用text打开obj文件时,可以看到网格模型具体是怎么表示的。
6.三维重建涉及的一些基本概念:例如相机坐标系和世界坐标系、旋转矩阵、透视变换等,这些都需要慢慢了解。视频推荐B站:计算机视觉之三维重建篇,书籍推荐张广军老师的《机器视觉》。
三 学习路线
1.Neural 3D Mesh Renderer
论文地址:https://arxiv.org/pdf/1711.07566.pdf
代码地址:https://github.com/hiroharu-kato/neural_renderer
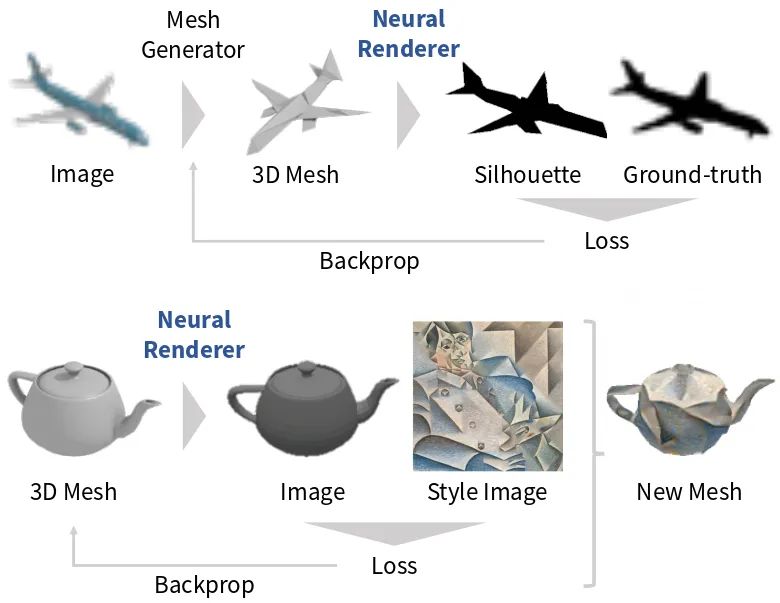
可以把它列为基于深度学习的单视图三维重建算法里程碑之作,后续很多算法都由此展开。标准的渲染过程中涉及光栅化这种离散操作,阻止了反向传播,这就不能使用深度学习的方法进行训练。因此这篇文章提出了一种可微的渲染方法,能够在特定的视角渲染三维模型得到二维图像。
2.Learning Category-Specific Mesh Reconstruction from Image Collections(CMR)
论文地址:https://arxiv.org/pdf/1803.07549.pdf
代码地址:https://github.com/akanazawa/cmr
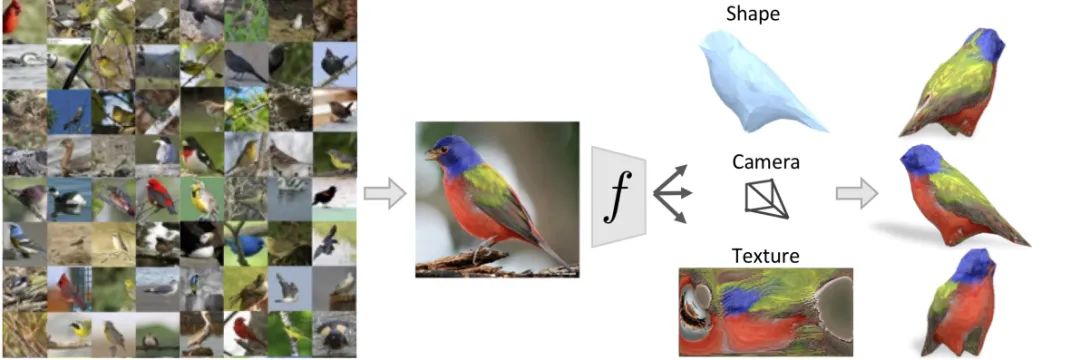
这篇文章是对上一个算法的应用,也算是这类算法更完整的实现。作者提出了一种从单个图像中恢复物体三维形状、相机和纹理的学习框架,输入的数据集需要标注关键点,但是不需要真实的3D数据集或者单个物体的多张图像进行监督,最后的输出是带有纹理的网格模型。
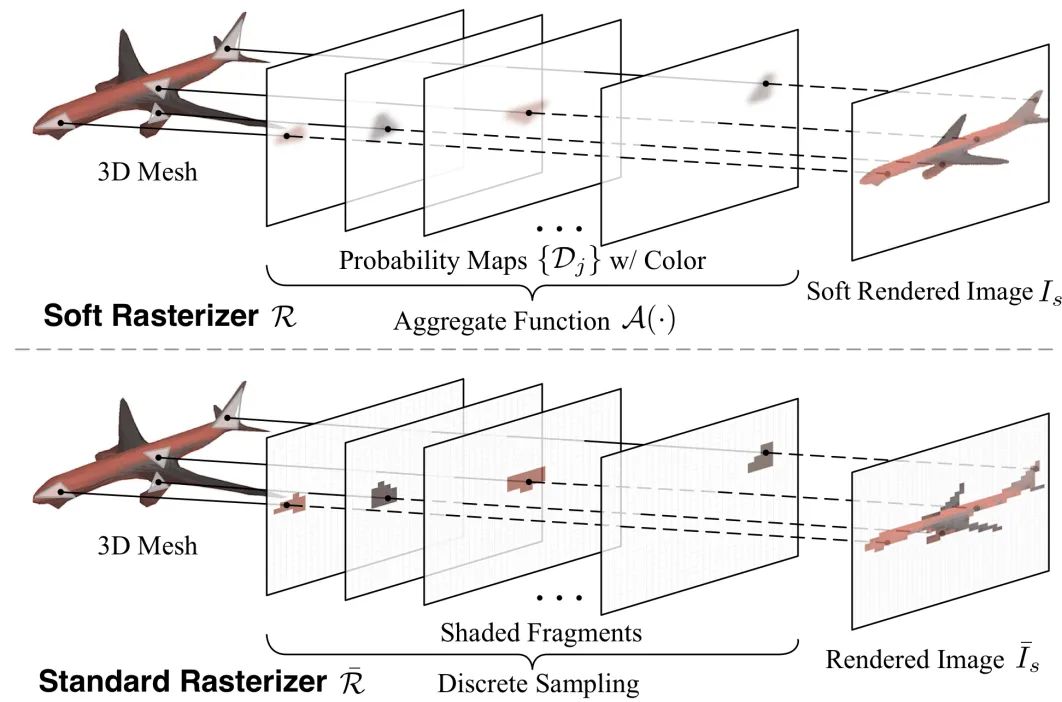
3.Soft Rasterizer: A Differentiable Renderer for Image-based 3D Reasoning
论文地址:https://arxiv.org/pdf/1904.01786.pdf
代码地址:https://github.com/ShichenLiu/SoftRas
4.Shape and Viewpoints without Keypoints(UCMR)
论文地址:https://arxiv.org/pdf/2007.10982.pdf
代码地址:https://github.com/shubham-goel/ucmr

这篇文章是对第二篇的改进,也是对第一、第三篇文章所提到的渲染器的综合应用。总的来说,数据集更加简单,只需要原始图像和掩膜即可,但是达到的效果更好。
四 后续论文推荐
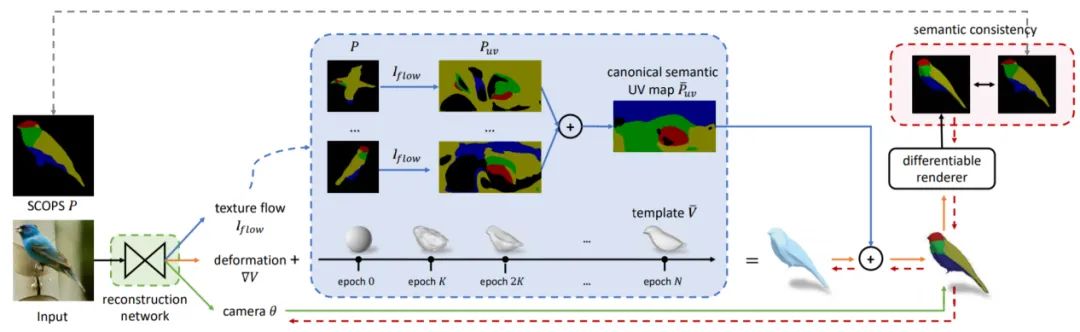
1.Self-supervised Single-view 3D Reconstruction via Semantic Consistency(UMR)
论文地址:https://arxiv.org/pdf/2003.06473.pdf
2.Using Adaptive Gradient for Texture Learning in Single-View 3D Reconstruction
论文地址:https://arxiv.org/pdf/2104.14169.pdf
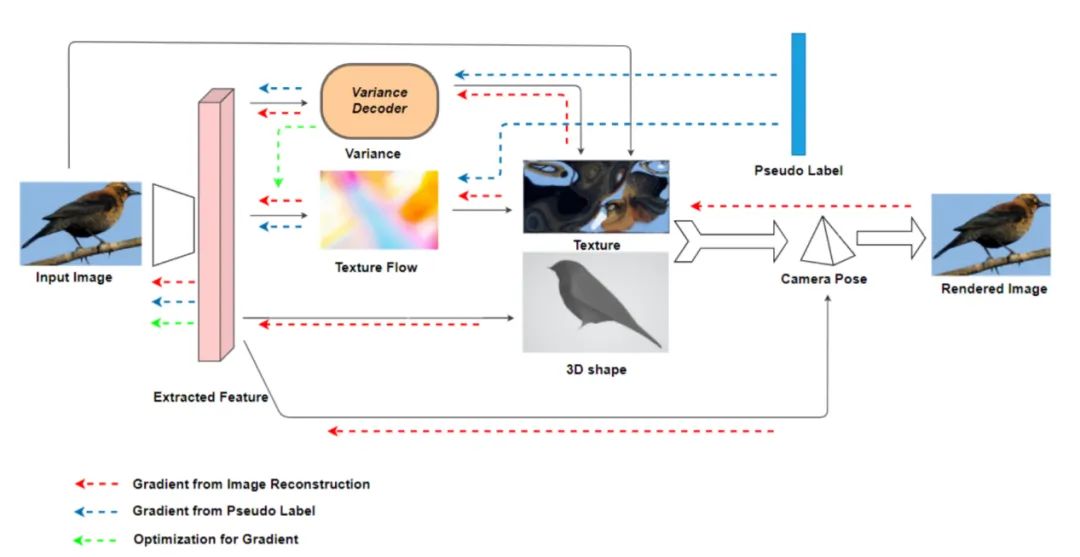
本文与另外三篇的重建效果对比如下表所示:
| Metric | Mask IOU | SSIM |
|---|---|---|
| CMR | 0.704 | 0.782 |
| UCMR | 0.6369 | 0.756 |
| UMR | 0.734 | 0.812 |
| Ours | 0.7691 | 0.8294 |
五 相关论文推荐
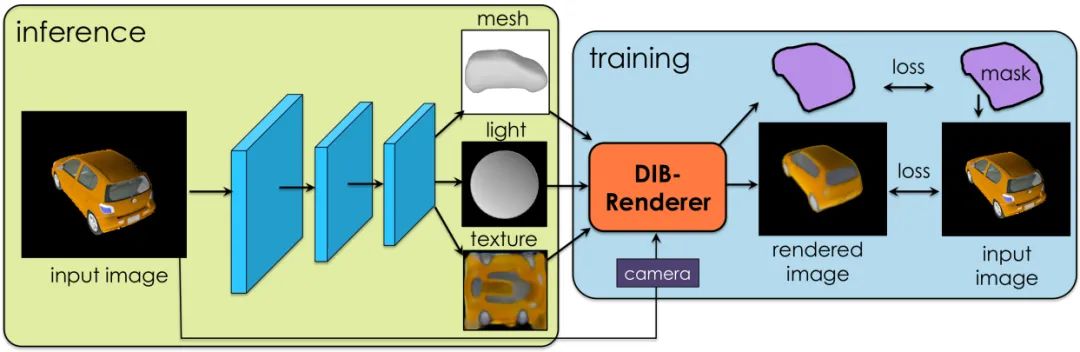
1.Learning to Predict 3D Objects with an Interpolation-based Differentiable Renderer
论文地址:https://nv-tlabs.github.io/DIB-R/files/diff_shader.pdf
代码地址:https://github.com/nv-tlabs/DIB-R
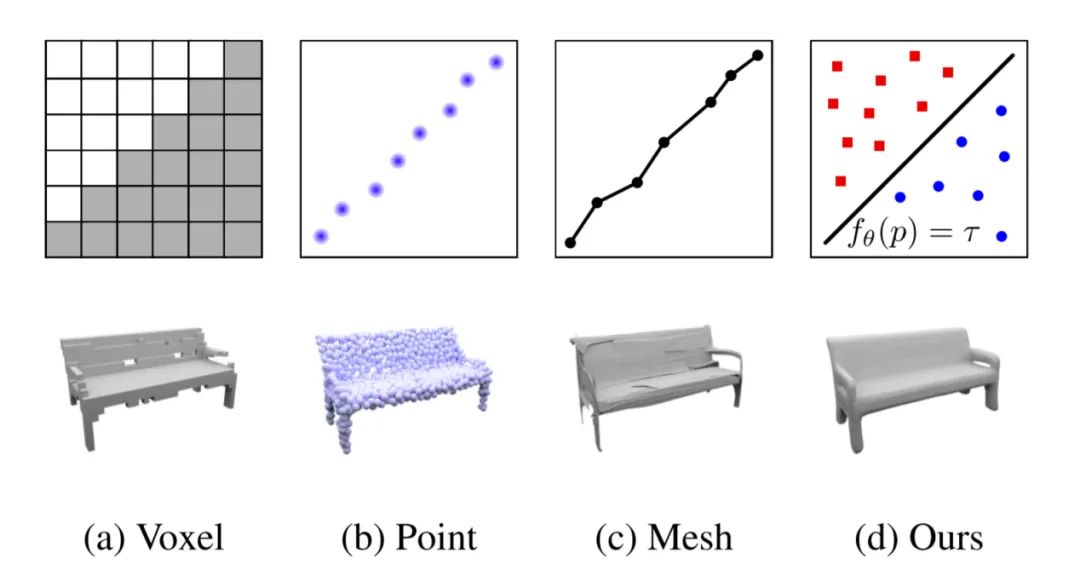
2.Occupancy Networks: Learning 3D Reconstruction in Function Space
论文地址:http://www.cvlibs.net/publications/Mescheder2019CVPR.pdf
代码地址:https://github.com/autonomousvision/occupancy_networks
如果觉得有用,就请分享到朋友圈吧!
公众号后台回复“transformer”获取最新Transformer综述论文下载~

# CV技术社群邀请函 #

备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~






