初学者系列:基于Keras的Faster-RCNN的代码学习
【导读】目标检测(object detection),就是在给定的图片中精确找到物体所在位置,并标注出物体的类别。目前学术和工业界出现的目标检测算法分成3类:传统的目标检测算法,候选区域/框 + 深度学习分类,基于深度学习的回归方法。Faster R-CNN属于第二种,本文将介绍Faster R-CNN原理以及它的代码学习。


一、faster-rcnn介绍
原理如图:
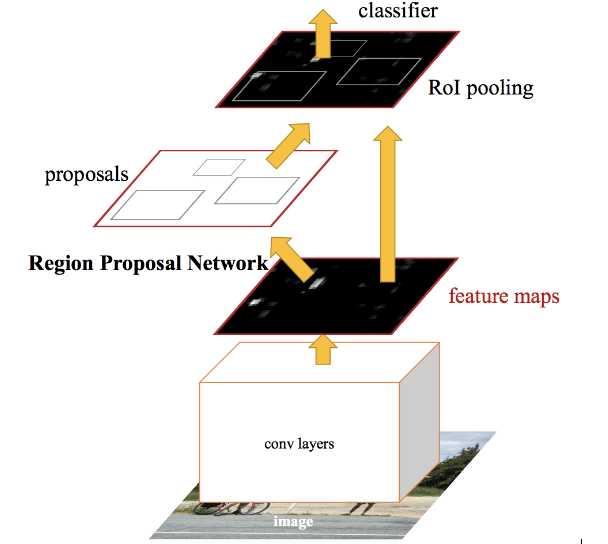
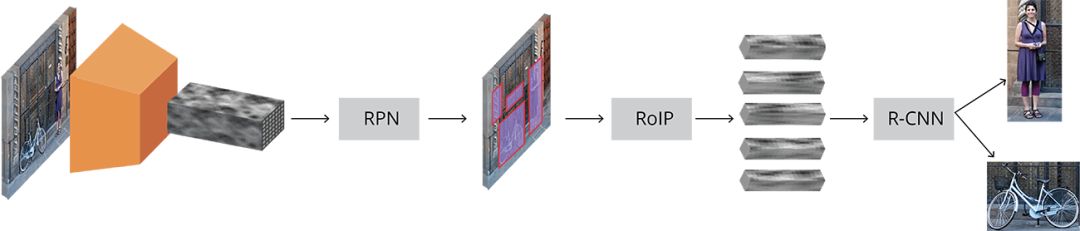
完整的faster_rcnn如下:
论文地址:
https://arxiv.org/abs/1506.01497
解读:可以看出原始图片,经过卷积层生成特征图,RPN用特征图输出推荐区域,RoIP将大小不同的推荐区域变成相同大小的区域,最后经过R-CNN分类,最终检测出了目标。所以,我们把faster rcnn分为4层:
feature extraction
proposal extraction
bounding box regression
classification
二、原理及代码讲解
Github地址:
https://github.com/you359/Keras-FasterRCNN
我们将从这个程序中的train_frcnn.py中介绍faster-rcnn的原理。笔者提醒:运行这个程序需要gpu支持。
2.1
Image 原始图片
程序的数据集用的是Pascal VOC数据集,数据集分为20类,包括背景为21类,可以从以下网址获取:
http://host.robots.ox.ac.uk/pascal/VOC/voc2012/VOCtrainval_11-May-2012.tar
解压放到项目根目录下,如图:
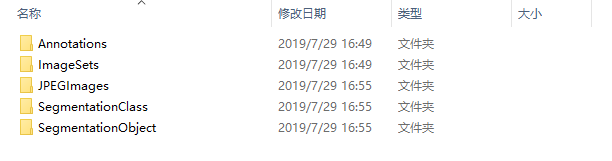
Annotations文件夹中存放的是xml格式的标签文件,每一个xml文件都对应于JPEGImages文件夹中的一张图片。
ImageSets存放的是训练集所要用到的图片文件名
JPEGImages存放的是所有图片。
SegmentationClass的每一张图片都对应JPEGImages里面的相应编号的图片。这里面的图片的像素颜色共有20种,对应20类物体比如所有的飞机都是红色的。
SegmentationObject里的图片是对每一类的不同Object进行颜色标注区分。比如,飞机类的不同Object会有不同的颜色
用命令行python train_frcnn.py -p ./VOCdevkit/
执行程序,具体其他参数,要从train_frcnn.py写的程序里了解,如图:
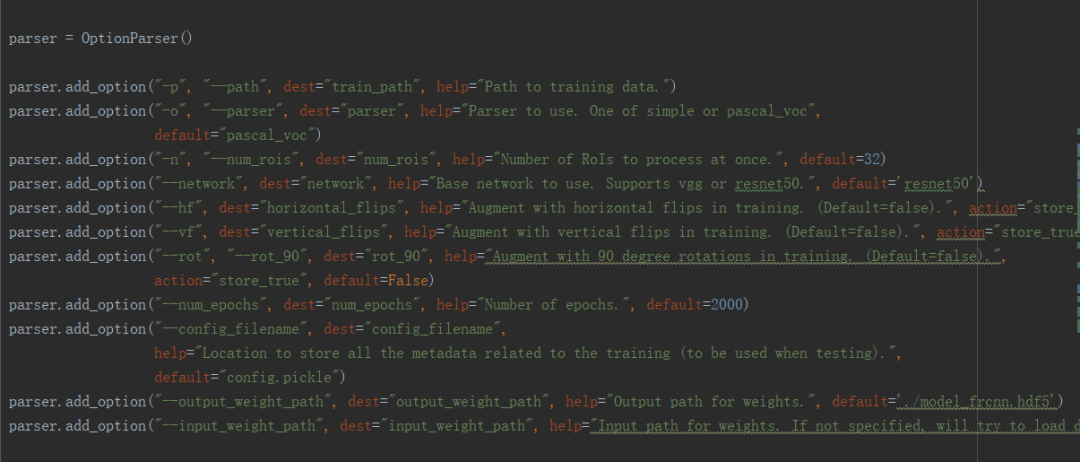
tain_frcnn.py中的一行代码,用
pascal_voc_parser.py中的get_data函数加载了数据集

定义数据生成器:
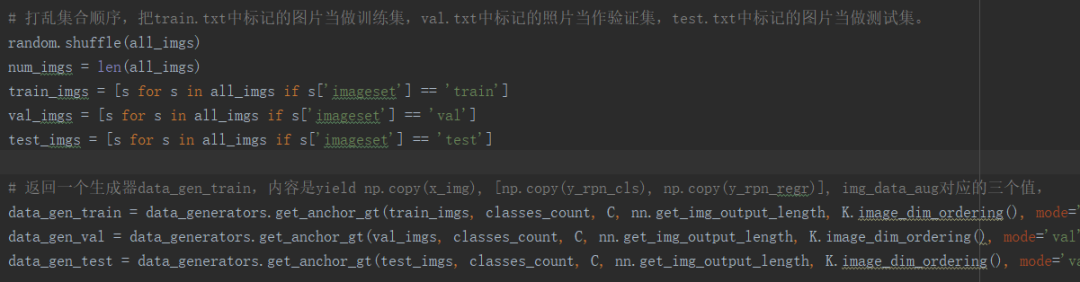
2.2
feature extraction
此层利用已经训练好的卷积层对图片进行特征提取。原理如图:

基础卷积的选择可以选择vgg16或者resnet50,本项目用的是resnet50,可以从config.py中看到,如图:
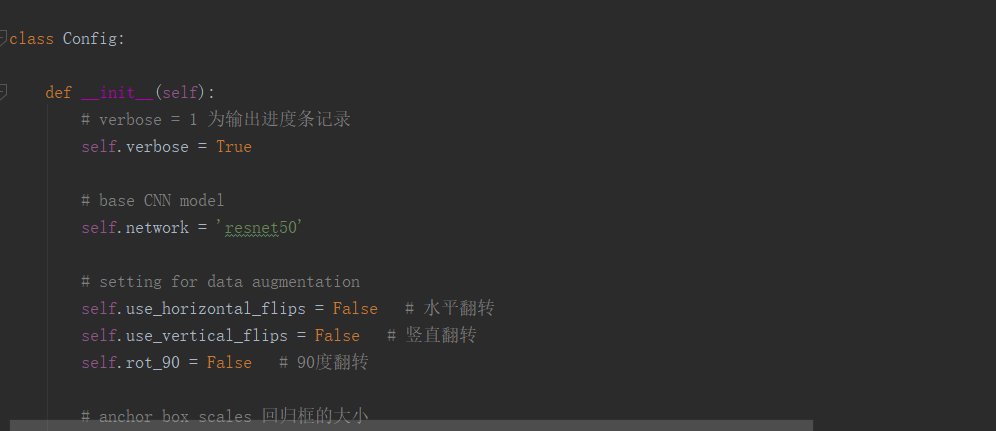
不过,你也可以通过命令行参数改,如图所示:
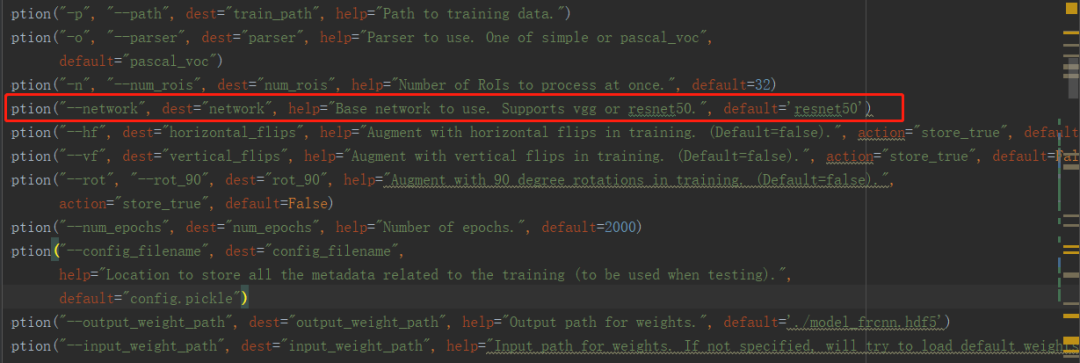
train_frcnn.py中用了一句来进行卷积
shared_layers=nn.nn_base(img_input,trainable=True)
而nn_base定义在vgg.py中,如图:
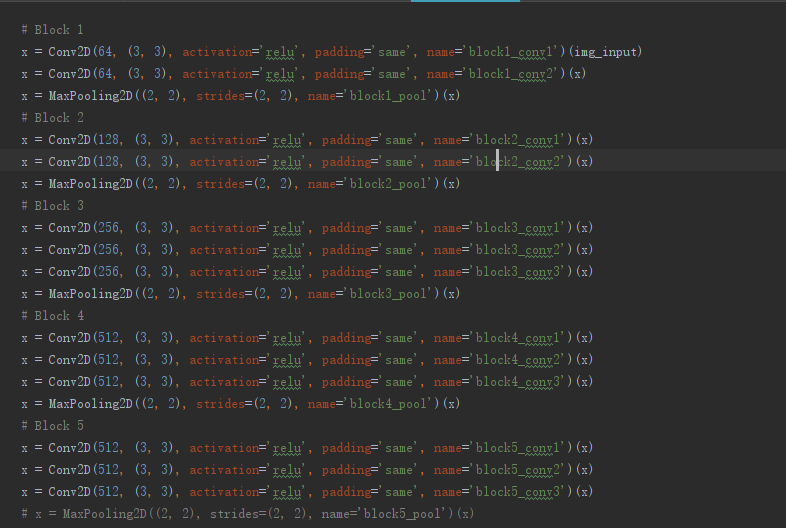
2.3
proposal extraction
RPN即Region Proposal Network,中文翻译成区域推荐网络。RPN基于fature maps生成proposals。如下:
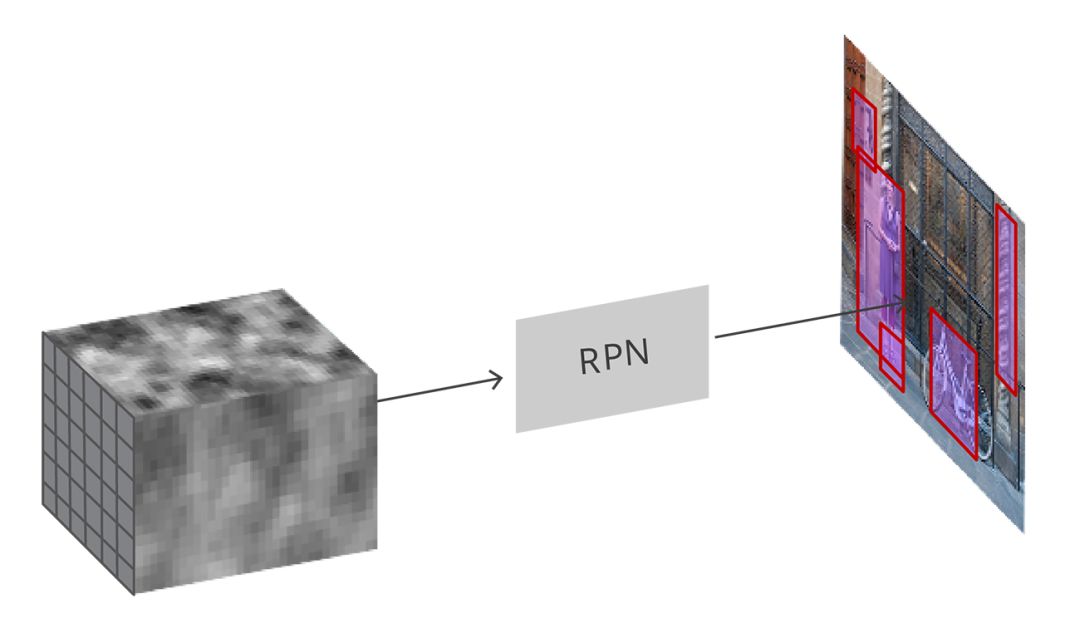
RPN是通过一个叫做锚点(anchor)的机制实现的。RPN对特征图上的每个点都生成一组锚点(9个),反推回原始图像,生成不同形状和大小的k个锚框(anchor box)。数学上,如果图片的尺寸是 w×h,那么特征图最终会缩小到尺寸为 w/r 和 h/r,其中 r 是次级采样率。如果我们在特征图上每个空间位置上都定义一个锚点,那么最终图片的锚点会相隔 r 个像素,在 VGG 中,r=16。原理如图:
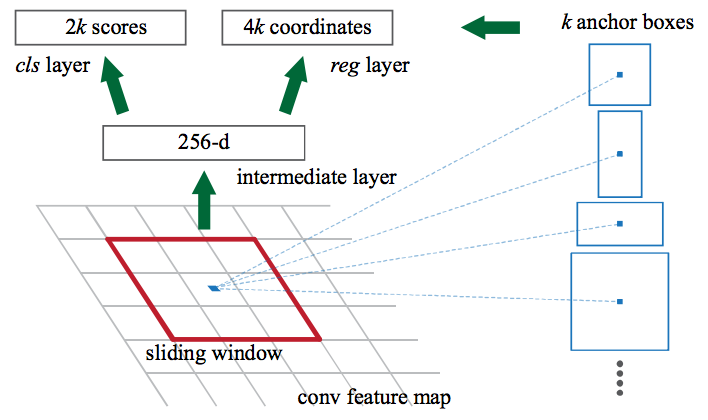
原始图片的锚点中心如下图:

之后,RPN 会对锚点进行分类和回归,生成proposals。这里的分类并不是分成数据集中21种类,而是通过求锚是对象的概率而留下或舍弃锚点;回归是用于调整锚点以更好地适合物体。
回到代码,train_frcnn.py使用rpn如下:
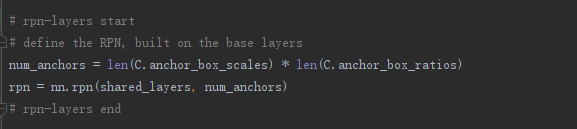
rpn在vgg.py中的实现如下:

通过rpn函数定义,我们可以看出,RPN 是用完全卷积的方式高效实现的,用基础网络返回的卷积特征图作为输入。然后分类,回归。
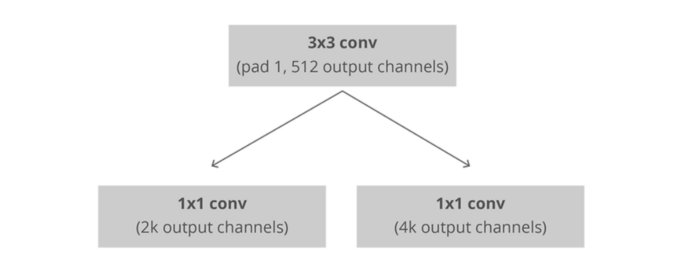
2.4
bounding box regression
此层用RoI池收集输入的feature maps和proposals(不同形状和大小的bounding box),综合这些信息后提取固定大小的proposals,送入后续全连接层判定目标分类,原理如下
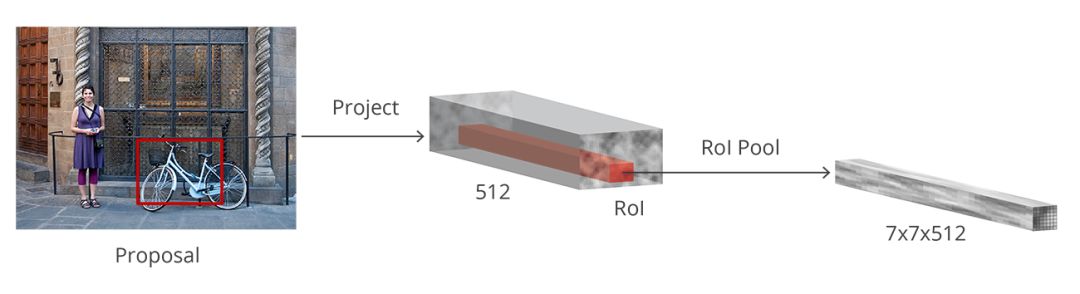
2.5
Classification
基于区域的卷积神经网络(R-CNN)是faster rcnn中的最后一步。在从图像中获取特征图之后,通过RPN得到proposals,再通过RoI池提取每个proposal的特征,我们最终需要使用这些特征进行分类。R-CNN使用全连接的层来输出每个可能的对象类的分数。原理如图:
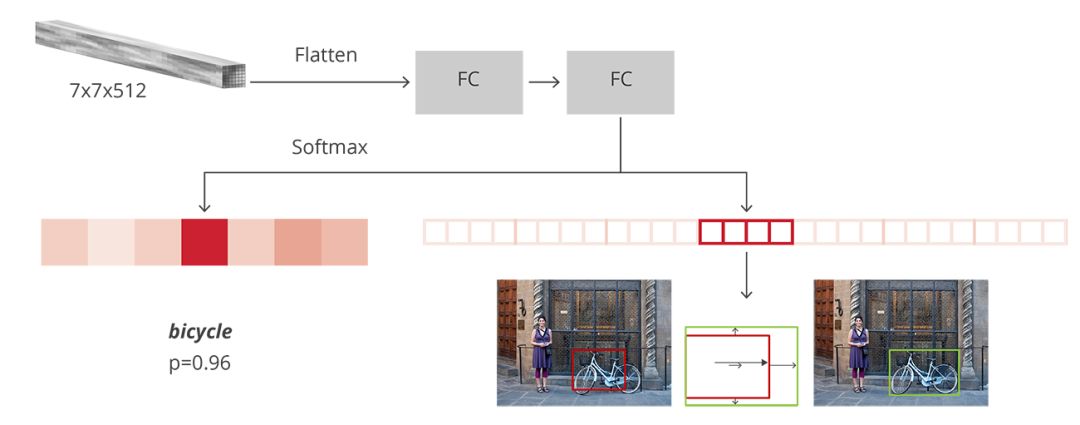
此项目将RoI池化层与分类层写在了一个classifier函数中,如下:
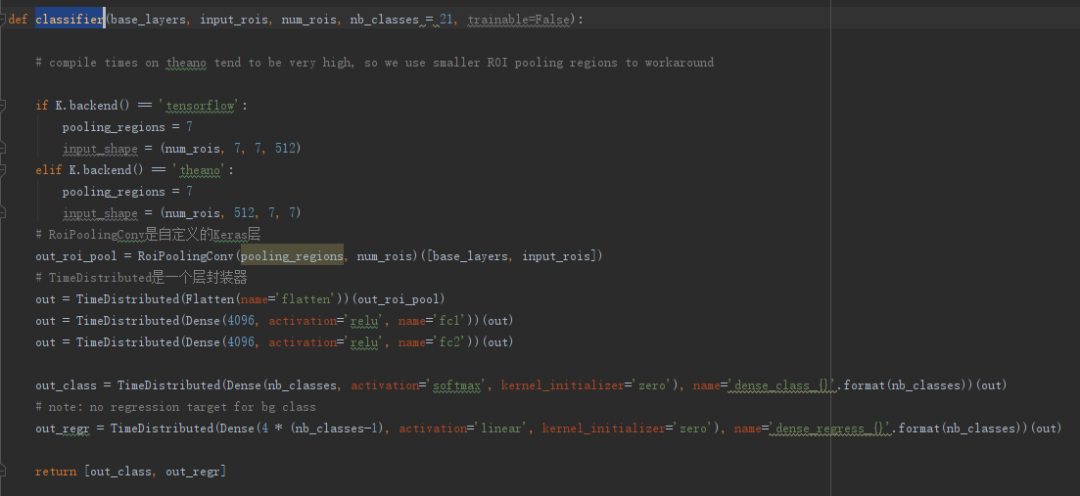
到此,faster rcnn模型结构便结束了,之后便是编译模型,训练模型,测试模型。
以上部分内容引用自
https://towardsdatascience.com/faster-r-cnn-object-detection-implemented-by-keras-for-custom-data-from-googles-open-images-125f62b9141a
三、总结
faster rcnn相比于fast rcnn,综合性能有较大提高,在检测速度方面尤为明显。不过我相信还会有更好更快的目标检测解决方案。此文只是faster rcnn入门级教程,想要知道具体细节,还需读者自己有兴趣再去调查。
-END-
专 · 知
专知,专业可信的人工智能知识分发,让认知协作更快更好!欢迎登录www.zhuanzhi.ai,注册登录专知,获取更多AI知识资料!

欢迎微信扫一扫加入专知人工智能知识星球群,获取最新AI专业干货知识教程视频资料和与专家交流咨询!

请加专知小助手微信(扫一扫如下二维码添加),加入专知人工智能主题群,咨询技术商务合作~

专知《深度学习:算法到实战》课程全部完成!550+位同学在学习,现在报名,限时优惠!网易云课堂人工智能畅销榜首位!

点击“阅读原文”,了解报名专知《深度学习:算法到实战》课程




