
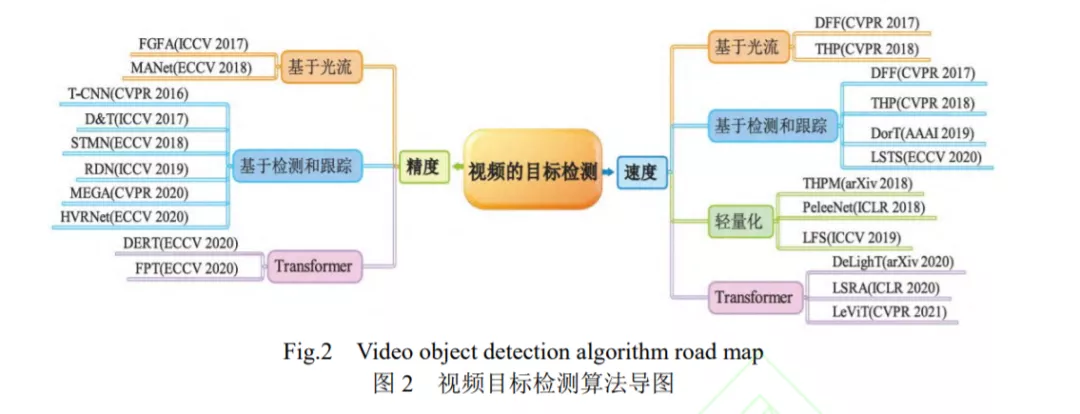
视频目标检测是为了解决每一个视频帧中出现的目标如何进行定位和识别的问题。相比于图像目标检测,视频具有高冗余度的特性,其中包含了大量的时空局部信息。随着深度卷积神经网络在静态图像目标检测领域的迅速普及,在性能上相较于传统方法显示出了非常大的优越性,并逐步在基于视频的目标检测任务上也发挥了应有的作用。但现有的视频目标检测算法仍然面临改进与优化主流目标检测算法的性能、保持视频序列的时空一致性、检测模型轻量化等关键技术的挑战。针对上述问题和挑战,本文在调研大量文献的基础上系统地对基于深度学习的视频目标检测算法进行了总结。从基于光流、检测等基础方法对这些算法进行了分类,从骨干网络、算法结构、数据集等角度细致探究了这些方法,结合在ImageNet VID等数据集上的实验结果,分析了该领域具有代表性算法的性能优势和劣势,以及算法之间存在的联系,对视频目标检测中待解决的问题与未来研究方向进行了阐述和展望。视频目标检测已成为众多的计算机视觉领域学者追逐的热点,将来会有更加高效,精度更高的算法被相继提出,其发展方向也会越来越好。
成为VIP会员查看完整内容
相关内容

Arxiv
0+阅读 · 2021年7月7日
相关VIP内容
相关资讯