基于深度学习的目标检测算法剖析与实现【附PPT与视频资料】

关注文章公众号
回复"尤安升"获取PPT
视频资料可点击下方阅读原文在线观看
导言
目标检测是计算机视觉和数字图像处理的一个热门方向,广泛应用于机器人导航、智能视频监控、工业检测、航空航天等诸多领域,通过计算机视觉减少对人力资本的消耗,具有重要的现实意义。因此,目标检测也就成为了近年来理论和应用的研究热点,它是图像处理和计算机视觉学科的重要分支,也是智能监控系统的核心部分,同时目标检测也是泛身份识别领域的一个基础性的算法,对后续的人脸识别、步态识别、人群计数、实例分割等任务起着至关重要的作用。本文主要介绍基于深度学习的两种目标检测算法思路与具体实现细节,分别为One-Stage目标检测算法和Two-Stage目标检测算法。
作者简介
尤安升,北京大学智能科学系研二,本科就读于北京大学信科计算机系,有过多年计算机视觉开发经验,精通图像分类、图像分割、关键点定位以及目标检测,开源项目PyTorchCV作者。

相关介绍
1.1 什么是相关检测
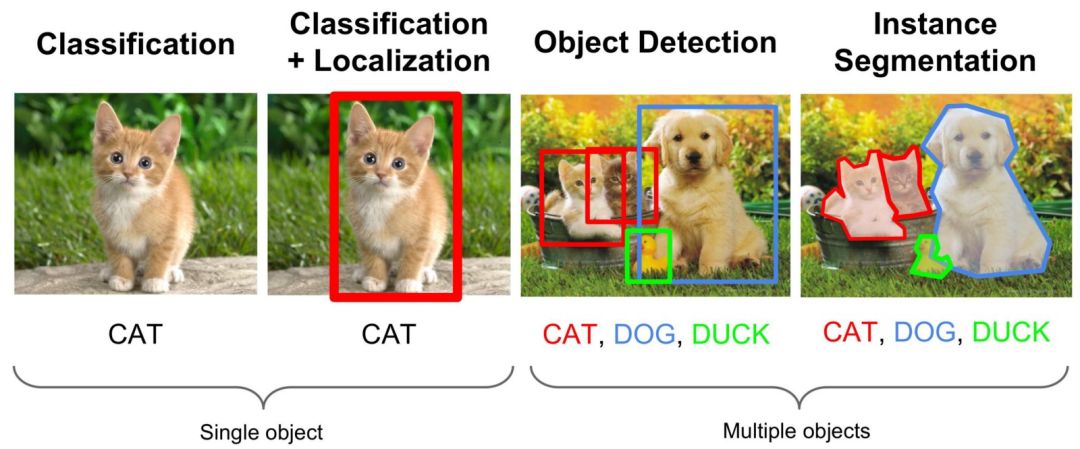
图1: 任务对比图
目标检测即找出图像中所有感兴趣的物体,包含物体定位和物体分类两个子任务,同时确定物体的类别和位置。
1.2 PyTorchCV
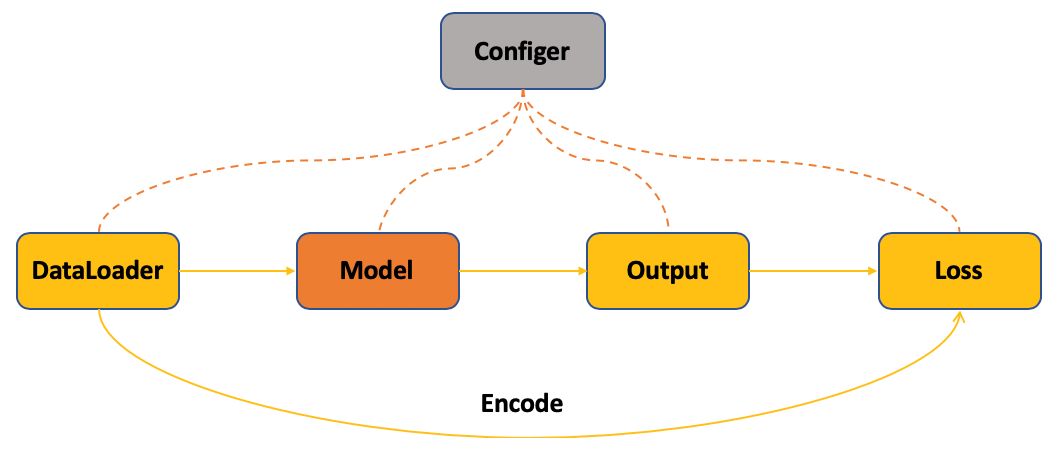
图2: PyTorchCV training过程抽象
训练过程主要包括数据读入、模型构建、模型输出以及计算损失值四个过程。其中PyTorchCV对每一种任务类型都定义了相应的数据格式,每一种方法都对应了一种数据读取类。需要注意的是在计算损失的时候需要将Ground Truth编码成和模型输出对应的格式,然后计算预测和目标的损失值。
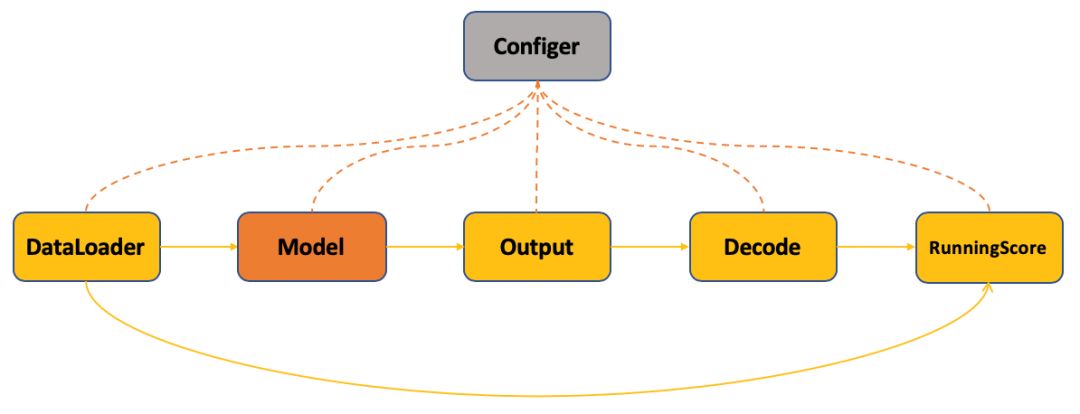
图3: PyTorchCV validation过程抽象
验证过程伴随着训练过程,其主要流程和训练过程相似,只是最后计算损失值变成了计算模型效果,即对模型输出进行解码,生成和Ground Truth格式相同的结果计算训练过程中的模型的效果。
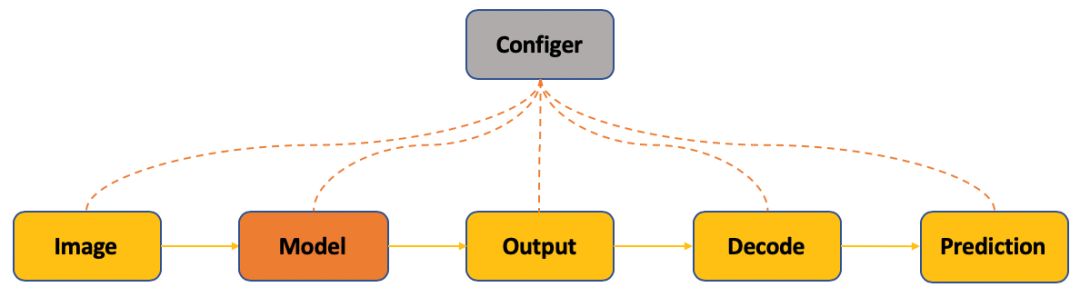
图4: PyTorchCV testing过程抽象
测试过程即图片作为输入,经过模型输出解码生成最后结果。其中解码过程即对模型的规则输出进行后处理生成我们需要的格式的结果。
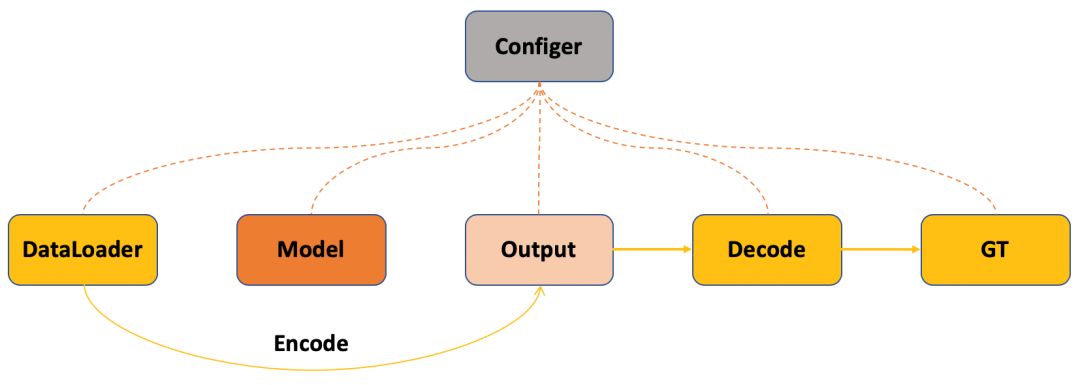
图5: PyTorchCV debug过程抽象
调试过程如图5所示,其中主要测试编码(Encode)和解码(Decode)过程的一致性,Ground Truth通过编码使其与网络输出的格式一样,这样原来用来解码网络输出的部分代码就可以用来解码Ground Truth通过编码之后的结果,如果解码过程能够还原Ground Truth,初步说明编码和解码过程在一定程度上是一致的和正确的。
目标检测算法分析
2.1 算法概述
目标检测任务可分为两个关键的子任务:目标分类和目标定位。目标分类任务负责判断输入图像或所选择图像区域(Proposals)中是否有感兴趣类别的物体出现,输出一系列带分数的标签表明感兴趣类别的物体出现在输入图像或所选择图像区域(Proposals)中的可能性。目标定位任务负责确定输入图像或所选择图像区域(Proposals)中感兴趣类别的物体的位置和范围,输出物体的包围盒、或物体中心、或物体的闭合边界等,通常使用方形包围盒,即Bounding Box用来表示物体的位置信息。
目前主流的目标检测算法主要是基于深度学习模型,大概可以分成两大类别:
(1)One-Stage目标检测算法,这类检测算法不需要Region Proposal阶段,可以通过一个Stage直接产生物体的类别概率和位置坐标值,比较典型的算法有YOLO、SSD和CornerNet;
(2)Two-Stage目标检测算法,这类检测算法将检测问题划分为两个阶段,第一个阶段首先产生候选区域(Region Proposals),包含目标大概的位置信息,然后第二个阶段对候选区域进行分类和位置精修,这类算法的典型代表有R-CNN,Fast R-CNN,Faster R-CNN等。目标检测模型的主要性能指标是检测准确度和速度,其中准确度主要考虑物体的定位以及分类准确度。一般情况下,Two-Stage算法在准确度上有优势,而One-Stage算法在速度上有优势。不过,随着研究的发展,两类算法都在两个方面做改进,均能在准确度以及速度上取得较好的结果。
2.2 One-Stage目标检测算法
One-Stage目标检测算法可以在一个stage直接产生物体的类别概率和位置坐标值,相比于Two-Stage的目标检测算法不需要Region Proposal阶段,整体流程较为简单。如下图所示,在Testing的时候输入图片通过CNN网络产生输出,解码(后处理)生成对应检测框即可;在Training的时候则需要将Ground Truth编码成CNN输出对应的格式以便计算对应损失loss。
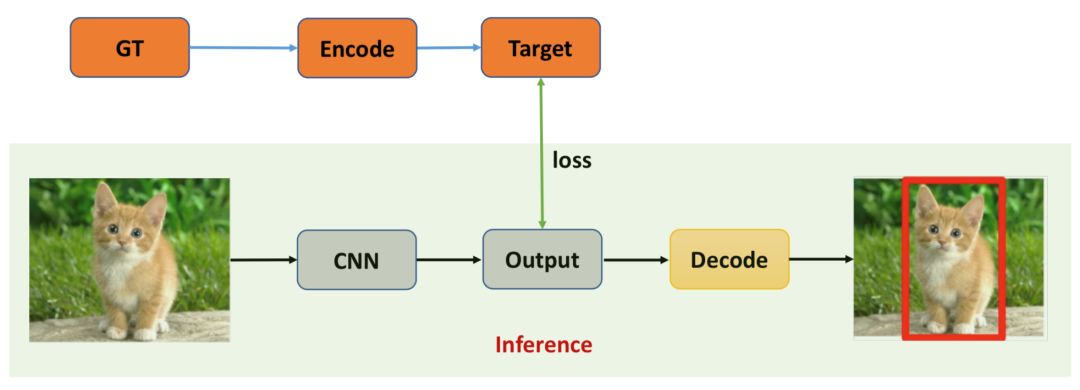
图6:One-Stage检测算法示意图
目前对于One-Stage算法的主要创新主要集中在如何设计更高效准确的CNN结构、如何更好地选择Anchors,如何构建网络回归目标以及如何设计损失函数上。

2.3 Two-Stage目标检测算法
Two-Stage目标检测算法本人认为可以看作是进行两次One-Stage检测,第一个Stage初步检测出物体位置,第二个Stage对第一个阶段的结果做进一步的精化,对每一个候选区域进行One-Stage检测。整体流程如下图所示,在Testing的时候输入图片经过卷积神经网络产生第一阶段输出,对输出进行解码处理生成候选区域,然后获取对应候选区域的特征表示(ROIs),然后对ROIs进一步精化产生第二阶段的输出,解码(后处理)生成最终结果,解码生成对应检测框即可;在Training的时候需要将Ground Truth编码成CNN输出对应的格式以便计算对应损失loss。
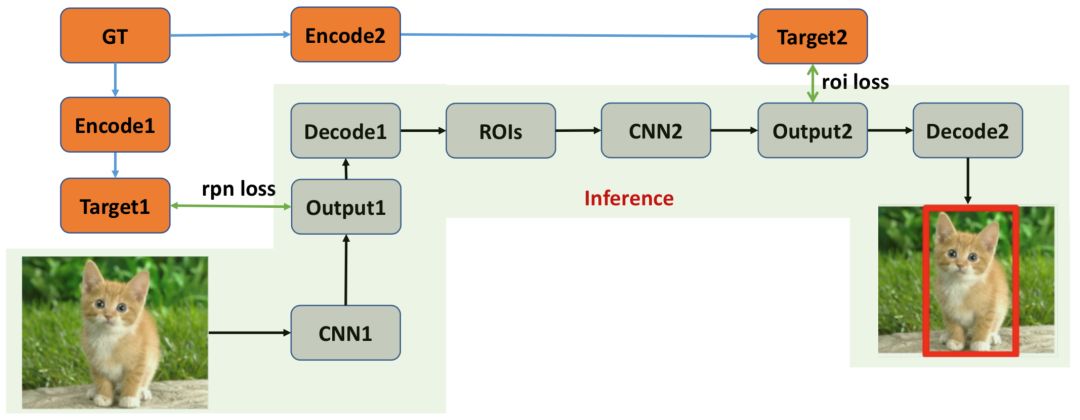
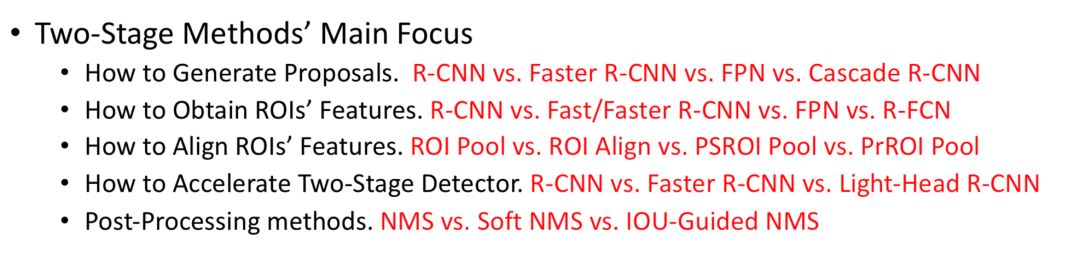
如上图所示,Two-Stage的两个阶段拆开来看均与One-Stage检测算法相似,所以我觉得Two-Stage可以看成是两个One-Stage检测算法的组合,第一个Stage做初步检测,剔除负样本,生成初步位置信息(Region of Interest),第二个Stage再做进一步精化并生成最终检测结果。目前对于Two-Stage算法的主要创新主要集中在如何高效准确地生成Proposals、如何获取更好的ROI features、如何Align获取到的ROI features、如何加速Two-Stage检测算法以及如何改进后处理方法。
小结
目标检测至今仍然是计算机视觉领域较为活跃的一个研究方向,虽然One-Stage检测算法和Two-Stage检测算法都取得了很好的效果,但是对于真实场景下的应用还存在一定差距,目标检测这一基本任务仍然是非常具有挑战性的课题,存在很大的提升潜力和空间。
欢迎关注https://github.com/CVBox
参考文献
[1] A. Krizhevsky, I. Sutskever,and G. E. Hinton, “Imagenet classification with deep convolutional neuralnetworks,” in Advances in neural information processing systems, 2012, pp.1097–1105.
[2] Vishwakarma S, Agrawal A. Asurvey on activity recognition and behavior understanding in video surveillance[J]. The Visual Computer, 2012: 1-27.
[3] D. Lowe. Distinctive imagefeatures from scale-invariant keypoints. IJCV, 2004.
[4] N. Dalal and B. Triggs. Histograms of oriented gradients for humandetection. In CVPR, 2005.
[5] Liu, Wei, et al. "SSD:Single Shot MultiBox Detector." European Conference on Computer VisionSpringer International Publishing, 2016:21-37.
[6] Fu C Y, Liu W, Ranga A, et al.DSSD : Deconvolutional Single Shot Detector[J]. 2017.
[7] Li Z, Zhou F. FSSD: FeatureFusion Single Shot Multibox Detector[J]. 2017.
[8] Redmon, Joseph, et al."You Only Look Once: Unified, Real-Time Object Detection."(2015):779-788.
[9]Redmon, Joseph, and A. Farhadi. "YOLO9000: Better, Faster,Stronger." (2016):6517-6525.
[10]Law H, Deng J. CornerNet: Detecting Objects as PairedKeypoints[J]. 2018.
[11]Girshick, R., Donahue, J., Darrell, T., Malik, J.: Rich featurehierarchies for accurate object detection and semantic segmentation. In CVPR2014.
[12]Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun. FasterR-CNN: Towards real-time object detection with region proposal networks. InNeural Information Processing Systems (NIPS), 2015.
[13]Lin T Y, Dollár P, Girshick R, et al. Feature Pyramid Networksfor Object Detection[J]. 2016.
[14]Cai Z, Vasconcelos N. Cascade R-CNN: Delving into High QualityObject Detection[J]. 2017.
[15] Dai J, Li Y, He K, et al.R-FCN: Object Detection via Region-based Fully Convolutional Networks[J]. 2016.
[16] Li Z, Peng C, Yu G, et al.Light-Head R-CNN: In Defense of Two-Stage Object Detector[J]. 2017.
[17]Bodla N, Singh B, Chellappa R, et al. Soft-NMS — Improving ObjectDetection with One Line of Code[J]. 2017.
[18]Softer-NMS: Rethinking Bounding Box Regression for Accurate ObjectDetection. arxiv id:1809.08545
[19]Jiang B, Luo R, Mao J, et al. Acquisition of LocalizationConfidence for Accurate Object Detection[J]. 2018.
SFFAI讲者招募
为了满足人工智能不同领域研究者相互交流、彼此启发的需求,我们发起了SFFAI这个公益活动。SFFAI每周举行一期线下活动,邀请一线科研人员分享、讨论人工智能各个领域的前沿思想和最新成果,使专注于各个细分领域的研究者开拓视野、触类旁通。
SFFAI目前主要关注机器学习、计算机视觉、自然语言处理等各个人工智能垂直领域及交叉领域的前沿进展,将对线下讨论的内容进行线上传播,使后来者少踩坑,也为讲者塑造个人影响力。
SFFAI还将构建人工智能领域的知识树(AI Knowledge Tree),通过汇总各位参与者贡献的领域知识,沉淀线下分享的前沿精华,使AI Knowledge Tree枝繁叶茂,为人工智能社区做出贡献。
这项意义非凡的社区工作正在稳步向前,衷心期待和感谢您的支持与奉献!
有意加入者请与我们联系:wangxl@mustedu.cn


历史文章推荐:



