万物皆可VIT!我和小伙伴都惊呆了!
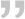
其实很早之前就听小伙伴们聊过vision transformer,但是因为当时自己所做的工作用到ViT的属实是很少,所以对于主动去了解这个东西就有些嗤之以鼻。
真正开始学,或者说认真开始看原paper结合code去理解vision transformer是由于我在AIR的暑研项目中,mentor提出了个有意思的想法是基于DETR (detection transformer)思路构造多类别异常检测模型。
这就使我不得不加班加点的从头了解vision transformer的结构以及其中的self-attention以及cross-attention机制。
借此机会也想跟大家分享一下关于我的学习心得。
对我个人而言,学习一个新技术或者去follow一项新的工作,我的学习路线通常是:读原paper——知乎找一下大家有关这篇工作的讨论——重读技术路线——对照代码去再次理解技术路线以及着重关注损失函数。
(以下参考了沐神讲vit视频下的笔记进行回忆)
扫码0.1元领取
8月29、30日晚20:00电子羊老师VIT论文精讲直播

带你详细解读VIT论文的启发点和创新点
首先是阅读原paper,通过标题和摘要可以获得一些信息:an image is worth 16*16 words,即每一张输入transformer的图片都会被打散为若干个16*16的小方格(patches),这样就可以利用nlp里面典型的transformer结构去做大规模的图像识别。
值得一提的是在ViT之前,我们都知道transformer在nlp领域是基本操作,但是这么好的idea却在cv领域应用十分有限。
原文作者谷歌团队着手解决了这个问题:1)attention+CNN或attention替换CNN components,但是保持CNN的整体结构。对于保持结构,是指的ResNet50有4个stage(R2/R3/R4/R5),每个stage不变,直接使用attention取代每一个stage里面的每一个block。
作者实验证明attention并不需要非得和CNN一起使用,跟transformer一起用时,在大规模数据集上预训练并在中小数据集做fine-tuning后照样能够取得sota效果。
接下来我跳过related work直接来看到了模型结构,不得不说看了主图基本上就明白很多了。ViT这篇文章尽可能使用原始transformer,旨在于享受架构的高效实现。
输入一张图,将它打成3*3的patches,然后再将其分别flattened从3*3变为1*9,经过一个Linear Projection后,将每个patches转变成了patch embedding。
由于encoder中需要做self-attention,即所有元素两两之间计算自注意力,这与顺序无关。
但是由于每个patch是来自于图片是有序的,所以作者在patch embedding前面加了position embedding,这样patch embedding + position embedding [CLS]=token(包含了图片的patch信息和每个patch在原图的位置信息)。
可以看到,其实真正输入进transformer的就是tokens,这与nlp中的工作是异曲同工的。
另外,文章主图做的分类任务,虽然每个token都会有输出,但是最终还是只拿[CLS]来做分类!这是因为transformer encoder中的self-attention机制使得所有tokens都在做两两的信息交互,那么[CLS]同样也会跟着所有的patches一起做交互,所以[CLS]也是可以学到有用信息的拿来做最终的分类的。
扫码0.1元领取
8月29、30日晚20:00电子羊老师VIT论文精讲直播
带你详细解读VIT论文的启发点和创新点
继续看上面,最终分类任务就是把[CLS]单拎出来到通用的MLP head中得到类别判断,这样就可以使用cross-entropy来进行训练了~
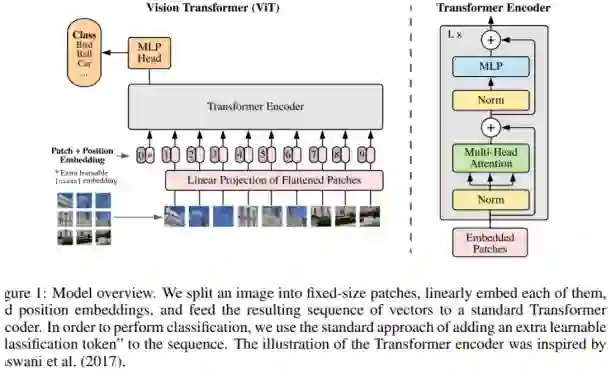
虽然ViT的整体思路在主图上的展示不能够再清晰,但是毕竟最终要拿来改代码做自己的任务嘛,根据代码重新过一遍前向过程是有必要的:
图片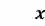
到这里其实阅读原文和代码就结束了,方法思路和代码的具体实现已经get到了。
我并没有看Related work以及实验部分的效果是因为现在ViT已经是经过各种大佬魔改之后被公认为还不错了。
诚然ViT这篇文章中也提及到了一些transformer固有的缺陷,比如data-hungry,相比CNN缺少归纳偏置,序列长维度高以及计算复杂度高等。但正因为有这一系列待解决的问题,留给后面研究的可能性也就越大。
所以我认为ViT原文的可读性依然非常的大,它讲解了最基本的原理和insight,但是真正希望把vit应用到自己的工作(其他领域)当中去,还是要看一些经典的ViT拓展工作来获取独到的思路,如DETR等等~
对于目前ViT的可灌水性真的很大,各个小领域都相继用transformer替换传统CNN实现了不错的效果,所以各位真的学起来啊!!!
扫码0.1元领取
8月29、30日晚20:00电子羊老师VIT论文精讲直播
带你详细解读VIT论文的启发点和创新点
