火爆全网,却只有4页!ICLR爆款论文「你只需要Patch」到底香不香?

新智元报道
新智元报道
来源:网络
编辑:好困 霜叶
【新智元导读】顶会投稿竟只写4页?拳打ViT,脚踢MLP,Patch到底能不能成为ALL YOU NEED?
金秋十月,又到了ICLR截稿的季节!
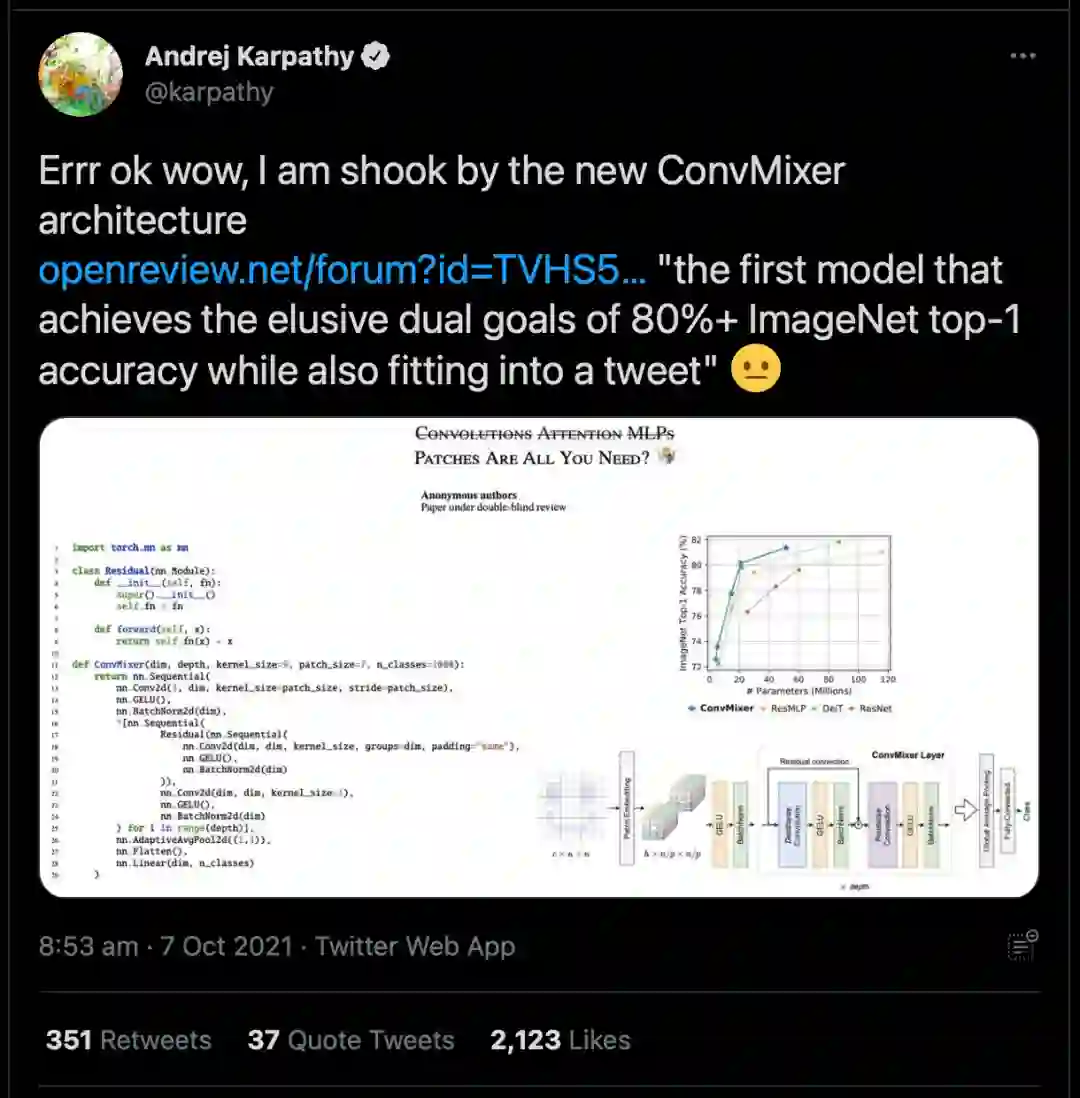
一篇「Patches are all you need」横空出世。
堪称ICLR 2022的爆款论文,从国外一路火到国内。

509个赞,3269个转发
知乎热搜
这篇标题里不仅有「划掉」还有「表情」的论文,正文只有4页!

https://openreview.net/pdf?id=TVHS5Y4dNvM
此外,作者还特地在文末写了个100多字的小论文表示:「期待更多内容?并没有。我们提出了一个非常简单的架构和观点:patches在卷积架构中很好用。四页的篇幅已经足够了。」

这……莫非又是「xx is all you need」的噱头论文?
你只需要PATCHES
这个特立独行的论文在一开篇的时候,作者就发出了灵魂拷问:「ViT的性能是由于更强大的Transformer架构,还是因为使用了patch作为输入表征?」
众所周知,卷积网络架构常年来占据着CV的主流,不过最近ViT(Vision Transformer)架构则在许多任务中的表现出优于经典卷积网络的性能,尤其是在大型数据集上。
然而,Transformer中自注意力层的应用,将导致计算成本将与每张图像的像素数成二次方扩展。因此想要在CV任务中使用Transformer架构,则需要把图像分成多个patch,再将它们线性嵌入 ,最后把Transformer直接应用于patch集合。
在本文中作者提出了一个极其简单的模型:ConvMixer,其结构与ViT和更基本的MLP-Mixer相似,直接以patch作为输入,分离了空间和通道维度的混合,并在整个网络中保持同等大小和分辨率。不同的是,ConvMixer只使用标准的卷积来实现混合步骤。
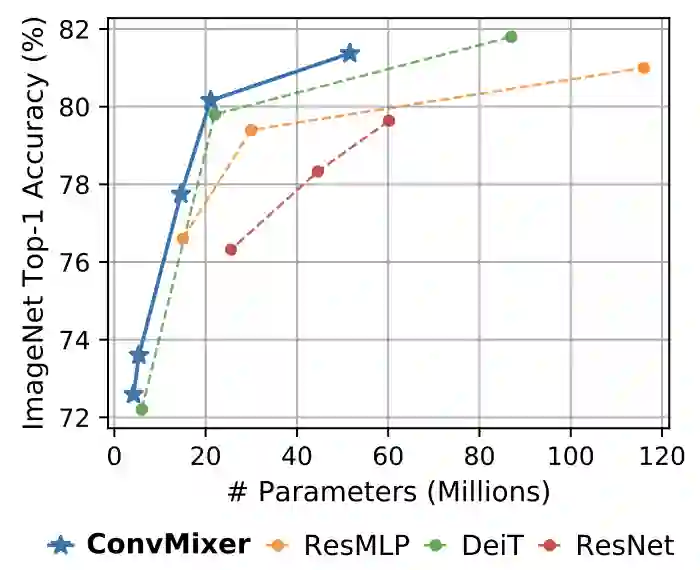
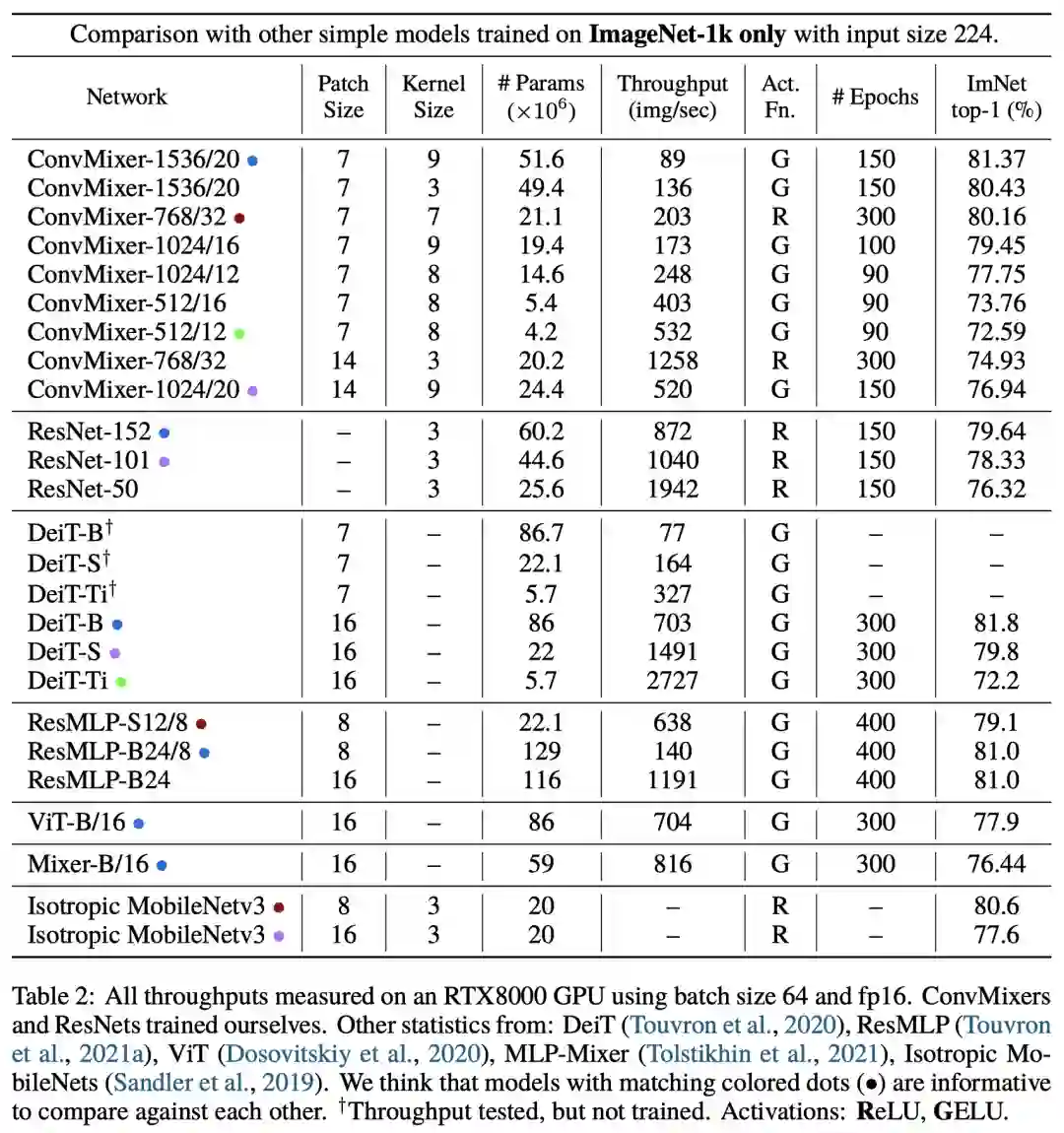
作者表示,通过结果可以证明ConvMixer在类似的参数量和数据集大小方面优于ViT、MLP-Mixer和部分变种,此外还优于经典的视觉模型,如ResNet。
ConvMixer模型
ConvMixer由一个patch嵌入层和一个简单的完全卷积块的重复应用组成。
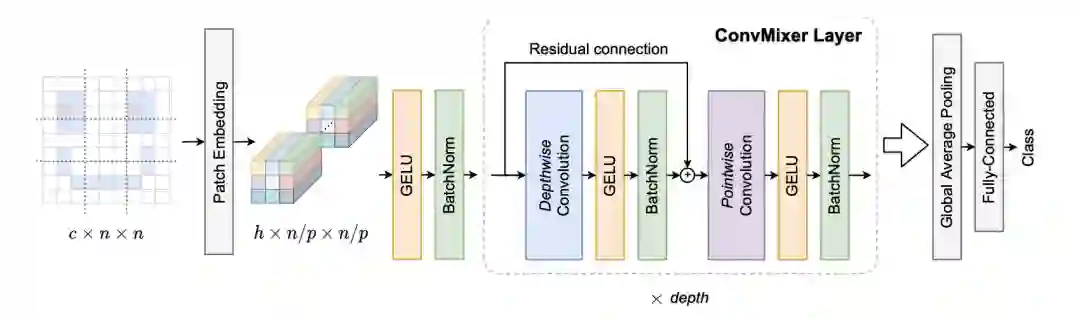
大小为p和维度为h的patch嵌入可以实现输入通道为c、输出通道为h、核大小为p和跨度为p的卷积。

ConvMixer模块包括depthwise卷积(组数等于通道数h的分组卷积)以及pointwise卷积(核大小为1×1)。每个卷积之后都有一个激活函数和激活后的BatchNorm:

在多次应用ConvMixer模块后,执行全局池化可以得到一个大小为h的特征向量,并在之后将其传递给softmax分类器。
ConvMixer的实例化取决于四个参数:
-
「宽度」或隐藏维度h(即patch嵌入的维度) -
「深度」或ConvMixer层的重复次数d -
控制模型内部分辨率的patch大小p -
深度卷积层的核大小k
实验结果

算法实现

网友评论
网友评论







参考资料:
https://www.zhihu.com/question/492712118
https://openreview.net/pdf?id=TVHS5Y4dNvM




