CV新时代已经来临

极市导读
自ViT问世以来,CV开始进入膨胀期,也迎来了新一轮的红利,开始了类似于NLP中Transformer的发展趋势。从CNN开始彻底走向ViT,从supervised到self-supervised,再到大数据预训练,ViT的变种不断增加,带来的性能也在持续提升。
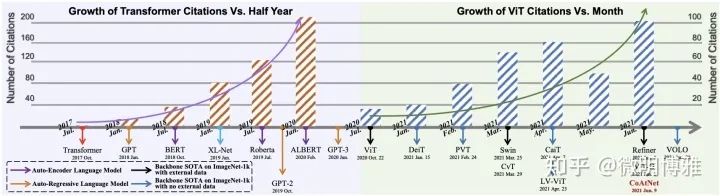
但问题也随之而来,ViT是最优的结构吗?真的需要这么多数据吗?在ViT的原始论文中已经揭露了许多问题,比如大模型对优化的选择非常敏感,同时需要更多的数据。对于优化问题,已经有人提出用卷积流代替patch流,在早期更有效地编码局部特征,这种方式不仅解决了优化问题同时提升了性能。对于数据量,DeiT和SwinT已经给出了一种数据有效性的ViT模型,但其中或多或少都引入了卷积的inductive bias,这不得不使我们重新考虑ViT结构:卷积流、分层设计甚至局部注意力。
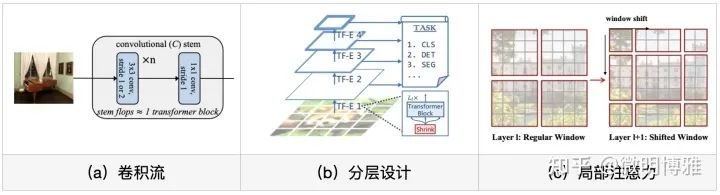
另外,越来越多CV任务已经开始转向Transformer架构,像目标检测中的DETR、语义分割中Segformer等;或者仅仅使用ViT作为backbone,比如SwinT已经证明了其在下游任务的有效性和通用性,已经可以完全替代CNN作为新一代的backbone。对于多模态任务,是否也需要朝着ViT发展,或者使用ViT作为backbone?事实上,对于captioning已经有这方面的工作,像CPTR直接用ViT替换Encoder,初步看效果不错,但探索的仍然不够充分。
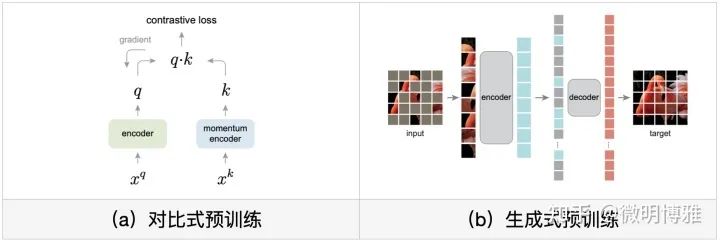
最后谈谈预训练,在ViT原始论文中使用了大规模JFT数据集,supervised预训练为图片分类带来了极大的提升,同时也证明了ViT是data-hungry的模型。然而,预训练的本质是视觉表征学习,这亦可以通过self-supervised的方式进行预训练学习,主要可以根据pretext task的类型分为两种方法:对比式预训练和生成式预训练:对比式预训练代表主要有SimCLR和MoCo等,它们都是衡量相似度以提炼视觉特征;而生成式预训练多数是效仿Bert或GPT,以Mask的机制重建或生成原始图像,典型的代表有iGPT和BEiT等,其实早在ViT论文中也做过类似的预训练,但没有很work。直到最近何凯明大神的MAE出现,打开了Mask生成式预训练的大门,通过一个简单模型在小数据量下达到超越监督式的效果。
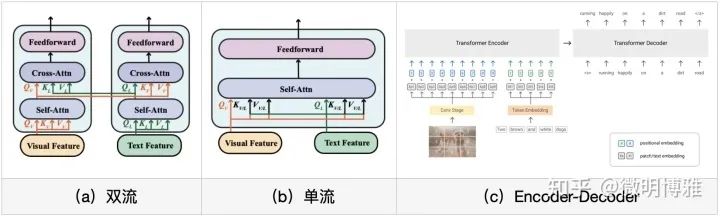
另一方面,多模态预训练最近也在不断兴起,视觉语言预训练(VLP)旨在将视觉和语言特征对齐,学习更好的联合嵌入表示。VLP主要可以分为双流和单流:双流模型通常有两个Encoder将视觉和语言分开编码,在晚期进行交互,如LXMERT;单流模型通常将视觉和语言送入同一个Encoder,在早期进行交互,如微软的Oscar,不过这些都类似于Bert的Mask预训练方法。另外,还有基于Encoder-Decoder的生成式预训练方法,像Google最新提出的SimVLM,其模型简单且更为通用,在6个多模态任务下都达到了惊人的sota。这些VLP模型的最主要特点就是大规模数据集,区别在于不同的pretext tasks,而且这些模型相对简单,但带来的效果却十分显著,这也许表明了:在大数据量的背景下简单架构足以学习到高质量的多模态表示。这不得不让我们思考多模态任务未来的发展方向,是否需要朝着预训练方向前进,或者使用一些预训练好的组件。
计算机视觉领域蓬勃发展,作为一名初学者,恰逢其时,踏入这个崭新的时代,这是多么幸运!
如果觉得有用,就请分享到朋友圈吧!
公众号后台回复“transformer”获取最新Transformer综述论文下载~

# CV技术社群邀请函 #

备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~




