十年回顾——CV的未来:ConvNeXt or Transformer?
点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
作者:gwave | 已授权转载(源:知乎)编辑:CVer
https://zhuanlan.zhihu.com/p/502076132
2012年,AlexNet横空出世,推动深度学习快速发展,带动AI的第三波浪潮,转眼已经十年弹指一挥间。
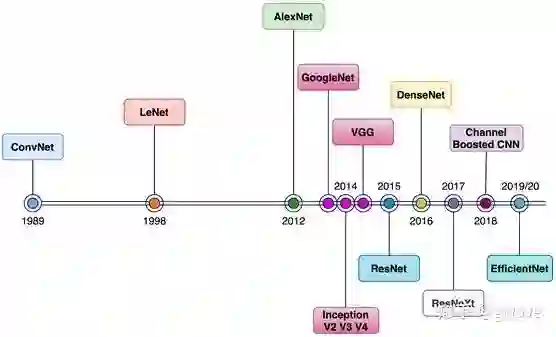
十年来,计算机视觉(CV)突飞猛进,VGGNet,GoogLeNet/Inception,ResNet、ResNeXt,DenseNet,MobileNet 和 EfficientNet等一大批ImageNet竞赛的年度冠军等优秀模型蓬勃发展,你方唱罢我登场,精彩纷呈,卷积神经网络CNN作为图像处理的标配卷过了AI的大半边天。
直到最近两年,自然语言处理 (NLP) 好像和CV是两条平行线,各自相对独立的发展。RNN和CNN是教科书中两个独立的章节,分别对应自然语言的序列(Sequence)和图像局部特征的特点。2017年,Google在NLP领域发表了Attention is all you need[1],提出基于自注意力(self-attention)的Transformer,当时,CV界被微软研究院He kaiming的ResNet打破人类分类错误率下限而激动不已,很少有人意识到CNN的“大厦将倾”的危险,正如经典物理学在20世纪初晴空万里的两朵乌云,看似不温不火NLP算法并将在数年后“全面碾压“看似更为“成熟”的CV领域,并显示了一统江湖的野心。

2018年的NLP领域注定不凡,谷歌的Jacob Devlin等人提出了基于Transformer的BERT[2](Bidirectional Encoder Representations from Transformers),BERT的B表示双向,了解NLP的朋友都知道“语言模型” (Language Model),根据一句话左边的词预测右边的词最有可能是哪个;BERT将这个预测游戏变成了自监督的“完形填空”,不再预测最右侧的词,而是预测句子中的任何位置的词,可同时利用将该位置左右两边(Bidirectional)的词进行预测。随着基于Transformer的BERT在NLP的各个子任务上“屠榜”,隔壁已经卷到无以复加的CV圈有点坐不住了。
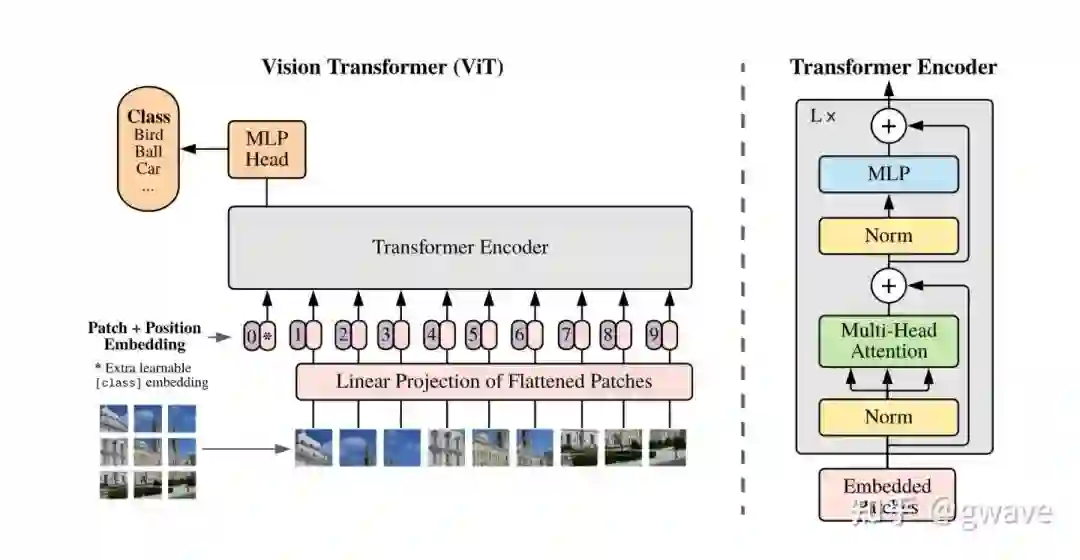
2020年Transformer在CV领域一炮打响,谷歌提出的Vision Transformer (ViT)[3] (An Image is Worth 16x16 Words,模仿“An Image is Worth a thousand Words”)再次横空出世,只是简单的将图片切成16X16的patch,扔到原封不动的NLP的Transformer中,结果竟然就一骑绝尘,表现超过了一众沉淀了多年的CNN,最神奇的是,完全不考虑图像的特点,把图像打成patch后就按NLP的Sequence的方法处理!
ViT的核心思想是将图片看成一系列16X16的patch序列,看来处理图像和自然语言并没有太大差别,在ViT/Transformer看来,一切都不过是Sequence而已,Transformer如同“降龙十八掌”,不管你是CV还是NLP的任务,都是一招制敌!不过 ViT 严重依赖大量训练技巧,包括花式数据增强等,但ViT毕竟是开创性工作,不宜苛求,总是要留点饭给后人吃的嘛(挖了很多大坑,比如NLP/CV多模态)。
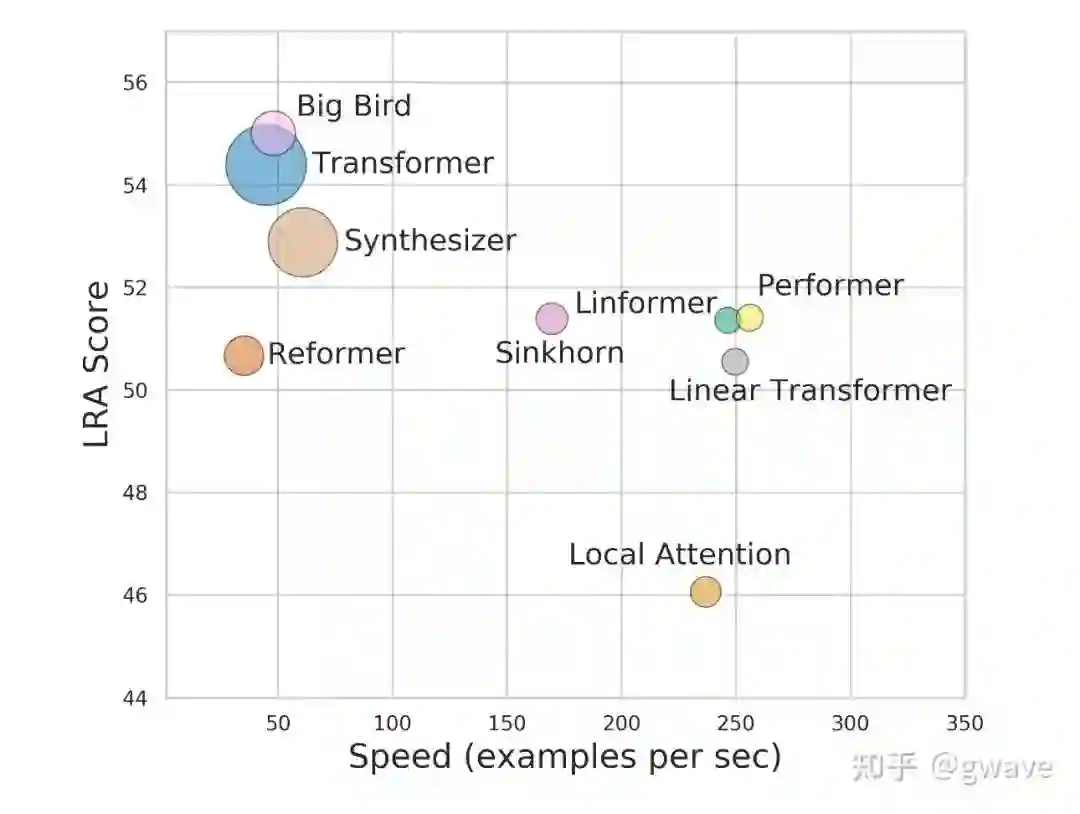
ViT恐怕是CV界自AlexNet(2012)以来最大的突破(之前各种CNN架构都是改良),之后各种XX-Former层出不穷(Long Range Arena: A Benchmark for Efficient Transformers[4]),结构上相对简单的CNN就像是过气的曾经大牌明星被拍的灰头土脸,不知道哪天才能恢复往日的荣光。
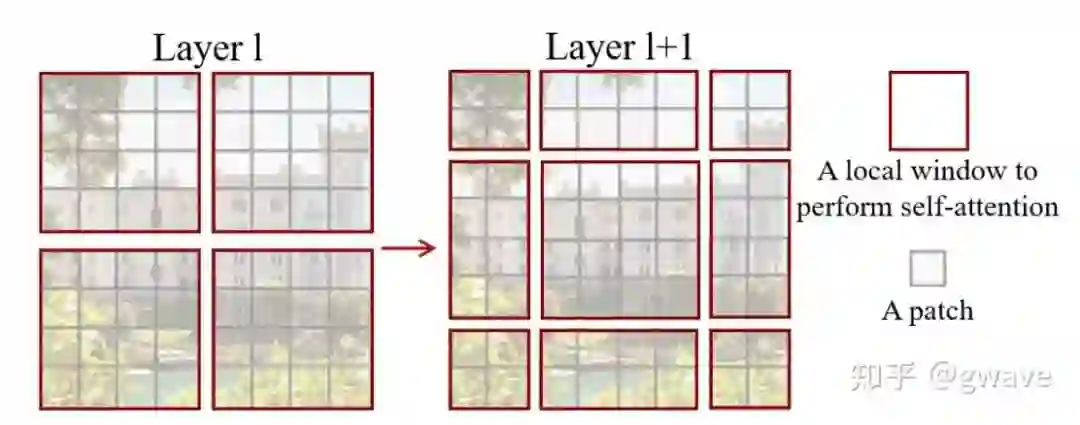
2021 年年中,微软发表了一款基于窗口移动(Shift Window)的Swin Transformer[5],窗口移动有点CNN的感觉又回来了,窗口移动能够促进相邻patch之间交互,也是个屠榜级的存在,文章自称可以作为Backbone,大家知道,Backbone都是史上留名的经典架构。
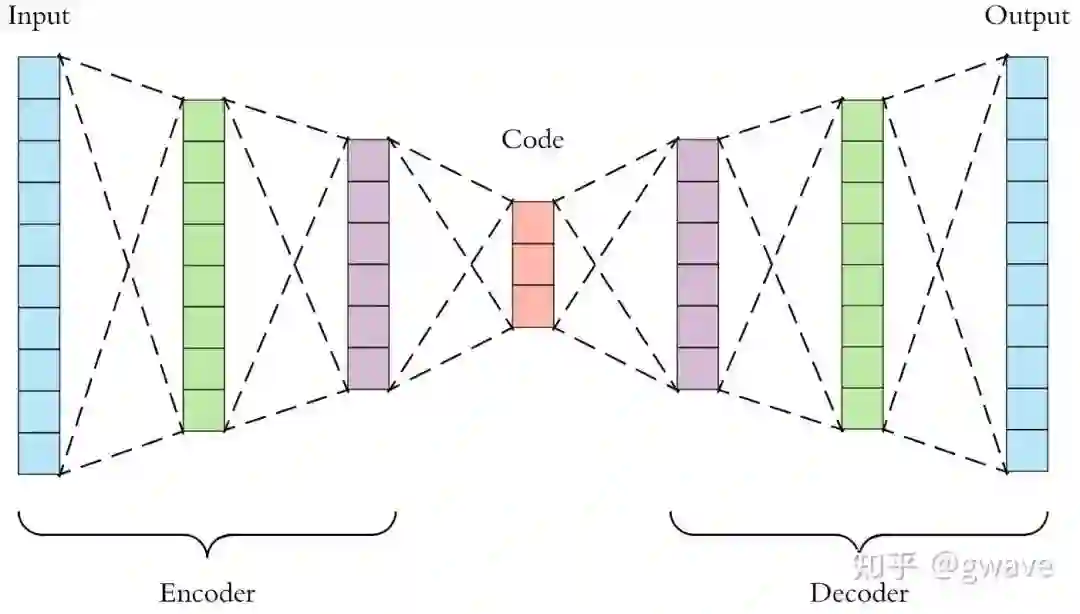
类似于NLP领域的BERT,自监督学习最近两年风头正劲,虽然这个概念并不新,2006年,Hinton老爷子在深度学习的三篇开山之作之一 Reducing the Dimensionality of Data with Neural Networks[6]就展示了Autoencoder优于PCA的数据表达/压缩能力,Autoencoder通过调整参数,力求使输出等于输入。十多年后,idea还是那个idea,无需人工标注的自监督学习再次流行。Autoencoder的Auto并不是“自动”的意思,而是“自”的意思,类似用法还有自回归Autoregressive,自闭症Autism等。Autoencoder一般由encoder和decoder两个部分组成,两者往往是对称的(下面也有不对称的例子),比如医疗影像分割的U-Net[7]是个典型的对称结构。
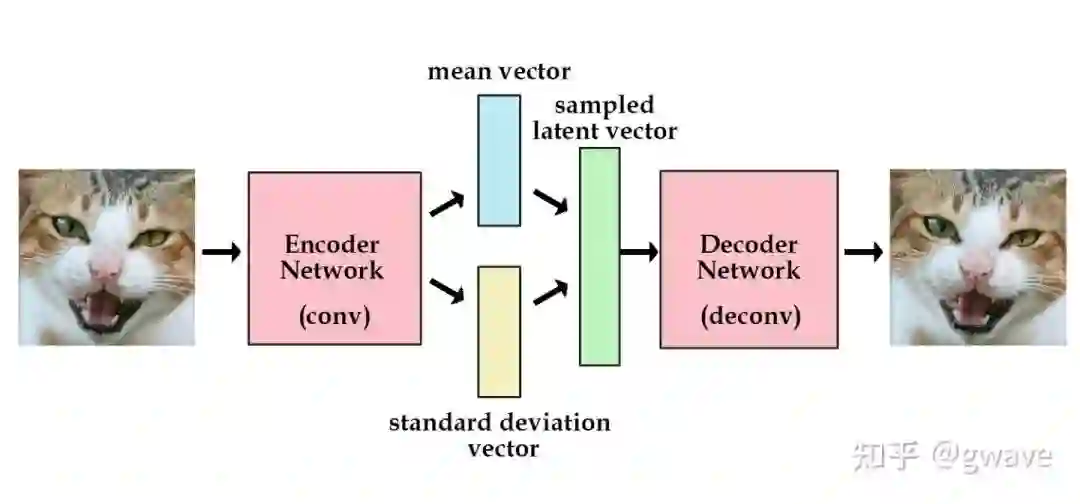
2013年出现的VAE(Variational Autoencoder)[8]恐怕是最著名的生成式模型(Generative Model)了,VAE和AE的差异在于VAE学到的是隐空间的概率分布,然后再对该概率分布进行采样,生成输出,比AE多了学习概率分布参数这一步。
生成式模型长期不温不火是因为表现一直比常见的判别式模型要弱一点,但历史总是用来被打破的!
2018年之后,NLP领域自监督的BERT的一统江湖。随着ViT将Transformer引入CV领域,CV领域是否也会产生一种类似于BERT这样的一种屠榜的自监督生成式模型呢?

2021年底,kaiming大神的MAE[9](Masked Autoencoder)来了,和VAE一样,MAE是个生成模型,它的Encoder和Decoder是不对称的。所谓Masked就是“掩盖”,上图80%的patch都被盖住 (左),MAE还原的效果(中)和ground truth(右)的对比。感觉比我厉害多了,我很难看出原来的被盖住图像是啥。

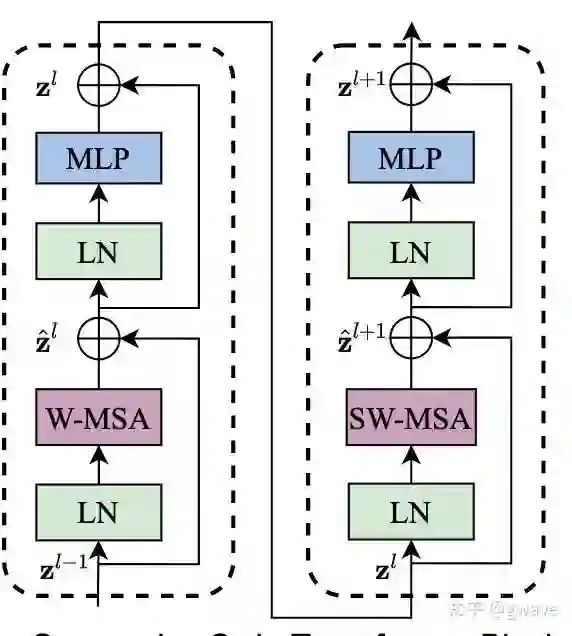
MAE的encoder和decoder都是Transformer block,但是encoder只处理不被掩盖的patch,由于大部分patch都被掩盖了,所以计算量相对要小很多。大概2017年左右,当时还在微软研究院的kaiming提出的ResNet解决了深度学习的层数限制问题,残差连接成为了至今仍被最广泛应用的技术之一,Swin Transformer中两个前后连续的block中分别都有两个残差连接(指向 
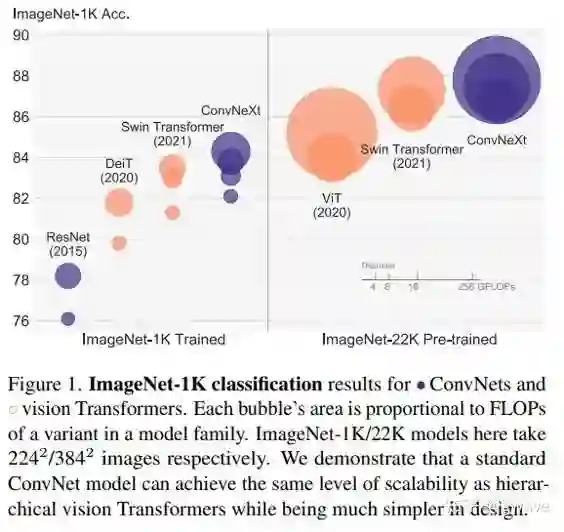
同样还是FAIR,最近从CNN发起了绝地反击,A ConvNet for the 2020s一文提出ConvNeXt[10],借鉴了 Vision Transformer 和 CNN 的成功经验,构建一个纯卷积网络,其性能超越了高大上(复杂的) 基于Transformer 的先进的模型,荣耀归卷积网络!但仔细看,好像也没又什么大的idea方面的创新,只是一堆Trick。但至少回应了“廉颇老矣,尚能饭否”的质疑,“饮食不弱于从前”!
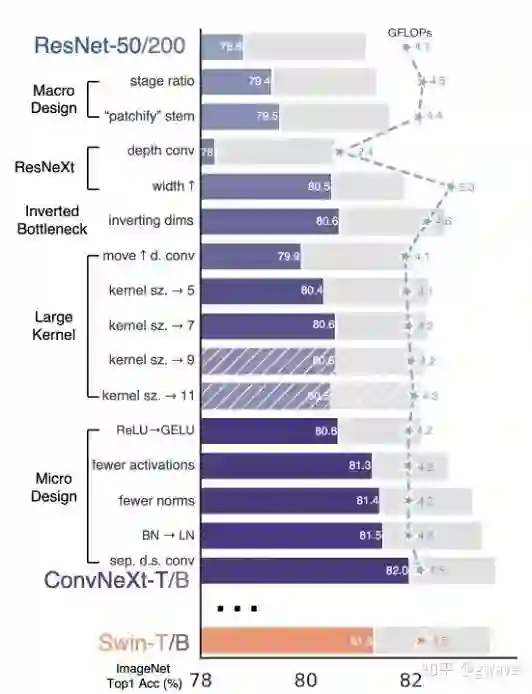
ConvNeXt 采用标准神经网络 ResNet-50 并对其进行现代化改造,以使设计更接近ViT,使用 AdamW 优化器,使用更多 epoch 对其进行训练,应用花式数据增强技术和正则化(高斯误差线性单元GELU代替Relu),使用大卷积核和Inverse Bottleneck(中间粗两头细)。
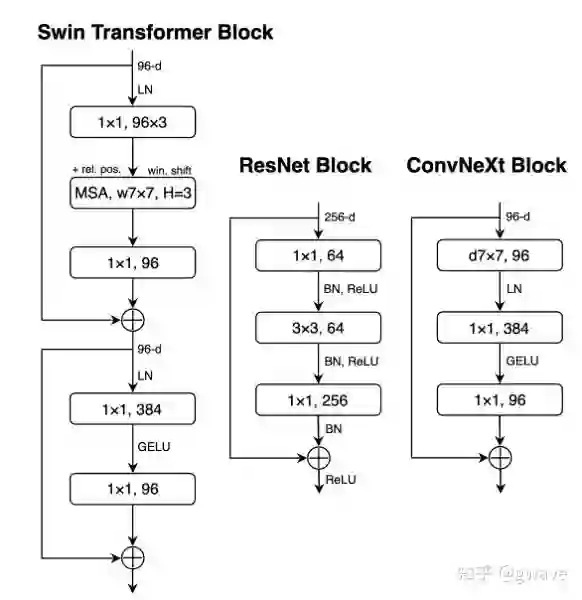
ConvNeXt的出现证明,并不一定需要Transformer那么复杂的结构,只是对原有CNN的技术和参数优化也能达到SOTA,未来CV领域卷积和Transformer谁主沉浮?
虽然ConvNeXt扳回一城,但未来应该也不是ConvNeXt is all you need! Transformer的价值不会被抹杀。
从Swin和PVT(Pyramid Vision Transformer)[11]可以看出,仅仅有注意力不太够用,(小patch)计算成本指数增长 O(n^2) ,大patch的颗粒度比较粗,不能满足语义分割等dense prediction的要求,而卷积具有提取本地特征计算成本低的优点,Transformer则更擅长于长程(long range)的全局特征(计算量大)处理,这恰是CNN的弱点(不杠空洞卷积哈),两者具有互补性;而ConvNext则借鉴了Transform的一些参数设置(如Block的数量)。
个人观点:未来CV的发展方向可能是ConvNet在前面对底层的特征进行抽取,后面接Transformer对全局特征处理,两者各司其职,并进行相应的结构简化。大家有什么其他观点,在评论区愿闻其详!

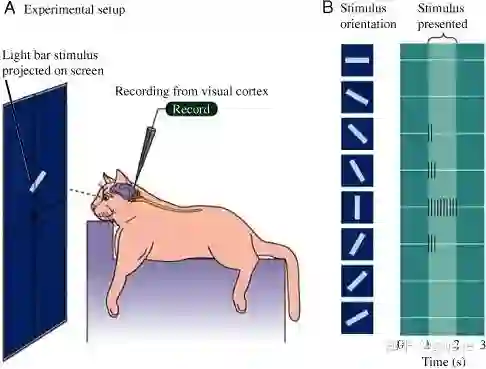
从更长远的历史尺度来看,CNN的工作原理与1958年Johns Hopkins大学两位教授Hubbell和Wiesel对于猫的视觉研究非常相似。他们在猫的脑壳上开了个3mm的小孔,放入电极,测量给猫看不同的图像刺激时猫脑电波动,他们发现特定的大脑视皮层细胞只会被部分对应形状的视觉特征图像所激发(CNN中的卷积核的工作原理与之非常类似),他们由此发现了大脑视觉过程的机制,获1981年诺贝尔医学奖。
1979年,日本科学家Kunihiko Fukushima提出Neocognitron模型,可以说是CV界卷积思想的鼻祖了吧。1990年代,Yan Lecun提出LeNet,比较好的识别了手写数字,他的MNIST数据集已经成为今天CV学习者的“Hello World”。2014年ImageNet冠军27层神经网络GoogLeNet中的L大写,是为了向LeNet致敬。

未来,CV大的突破也许来源于脑科学,认知科学或其他领域(GAN源于博弈论,玻尔兹曼机源于统计力学)的新发现,毕竟人类对大脑认知比宇宙还要少的多。不过,也有人认为,飞机不必向鸟那样煽动翅膀才能飞起来,但总的来说,我们期待未来CV领域的理论能有所突破,而不仅仅是堆算力的暴力美学以及炼丹(强化学习,遗传算法,元学习的用武之地?)。不过我也不是太悲观,大量实践是理论突破的基础,人类的认知一贯如此:
先发明了飞机,后有空气动力学
先发明了望远镜,后来才建立了光学
先有第谷.布拉赫积累大量行星运动数据,开普勒才发现了三大定律,牛顿才能提出万有引力定理
... ...
期待CV领域的:
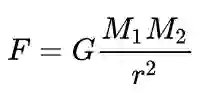
来解释第谷几麻袋的“天文数字”,彼时,GPU应该要回归其初心吧,亦或矿机仍然需求强烈,达成共识是个熵减的过程,消耗能量是必然的,也许宇宙的本质就是计算(病毒不断变异本质也是计算,研制疫苗的本质是和巨量使用遗传算法的病毒变异拼算力?),关键在于降低每次计算的能耗,大脑的功耗大约20W,一个馒头就够思考人参很久了。
题图来源:
https://appen.com/blog/computer-vision-vs-machine-vision/
参考
^https://arxiv.org/abs/1706.03762
^https://arxiv.org/abs/1810.04805
^https://arxiv.org/abs/2010.11929
^https://arxiv.org/pdf/2011.04006.pdf
^https://arxiv.org/abs/2103.14030
^https://www.science.org/doi/10.1126/science.1127647
^https://arxiv.org/abs/1505.04597
^https://arxiv.org/abs/1312.6114
^https://arxiv.org/abs/2111.06377
^https://arxiv.org/abs/2201.03545
^https://arxiv.org/abs/2102.12122
ICCV和CVPR 2021论文和代码下载
后台回复:CVPR2021,即可下载CVPR 2021论文和代码开源的论文合集
后台回复:ICCV2021,即可下载ICCV 2021论文和代码开源的论文合集
后台回复:Transformer综述,即可下载最新的3篇Transformer综述PDF
目标检测和Transformer交流群成立
扫描下方二维码,或者添加微信:CVer6666,即可添加CVer小助手微信,便可申请加入CVer-目标检测或者Transformer 微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer等。
一定要备注:研究方向+地点+学校/公司+昵称(如目标检测或者Transformer+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
▲扫码或加微信: CVer6666,进交流群
CVer学术交流群(知识星球)来了!想要了解最新最快最好的CV/DL/ML论文速递、优质开源项目、学习教程和实战训练等资料,欢迎扫描下方二维码,加入CVer学术交流群,已汇集数千人!
▲扫码进群
▲点击上方卡片,关注CVer公众号
整理不易,请点赞和在看