

动态注意力机制和全局建模能力使Transformer表现出较强的特征学习能力。近年来,Transformer在计算机视觉方面已经可以媲美CNN方法。本文主要研究了Transformer在图像和视频应用中的研究进展,对Transformer在视觉学习理解中的应用进行了全面的综述。首先,回顾了在Transformer中起着重要作用的注意力机制。然后介绍了视觉Transformer模型和各个模块的工作原理。第三,研究了现有的基于Transformer的模型,并比较了它们在视觉学习理解应用中的性能。研究了计算机视觉的三个图像任务和两个视频任务。前者主要包括图像分类、目标检测和图像分割。后者包括目标跟踪和视频分类。它对于比较不同模型在多个公共基准数据集上的不同任务性能具有重要意义。最后,总结了视觉Transformer存在的10个普遍问题,并对其发展前景进行了展望。
引言
深度学习[1]发展迅速,卷积神经网络(CNN)在深度学习[2]、[3]的各个领域都占据了主导地位。然而,近年来Transformer[4]逐渐打破了这种局面。它摒弃了以往深度学习任务中使用的CNN和RNN,在自然语言处理(NLP)、计算机视觉(CV)等领域取得了突破。逐渐地,基于Transformer的模型在最近三年中得到了很好的发展。最初的Transformer模型是在2017年[4]题为“Attention is all you need”的论文中正式提出的。它来自于NLP中的机器翻译模型seq2seq[5]。此外,在Transformer模型中也采用了编码器-解码器架构。它主要是从一个注意力模块演变而来的,自注意力,这是现有的注意力模式之一。在注意力机制方面,出现了多种注意力模型来提高识别效果。现有的注意力模型主要包括通道注意力、空间注意力和自注意力[6]。《Transformer》的核心是自注意力。
首先,Transformer是一种新颖的方法,在自然语言处理中取得了巨大的成功。后来又扩展到CV中的不同任务,如高分辨率图像合成[7]、目标跟踪[8]、目标检测[9]-[11]、分类[12]、分割[13]、图像处理[14]、再识别[15]-[17]等。在过去的三年里,Transformer已经进化出了一系列变体,也被称为X-Transformer[18]。各种Transformer 应运而生,并在各项任务中取得了良好的应用进展。研究表明,预训练的Transformer模型在各种任务中都达到了最先进的水平。Transformer模型的效果是显著的,特别是在ImageNet分类任务中。ViT[19]、BoTNet[20]、Swin Transformer[21]相继提出,并一次又一次实现性能突破。本文综述了Transformer在视觉学习理解的图像和视频应用方面的发展进展。
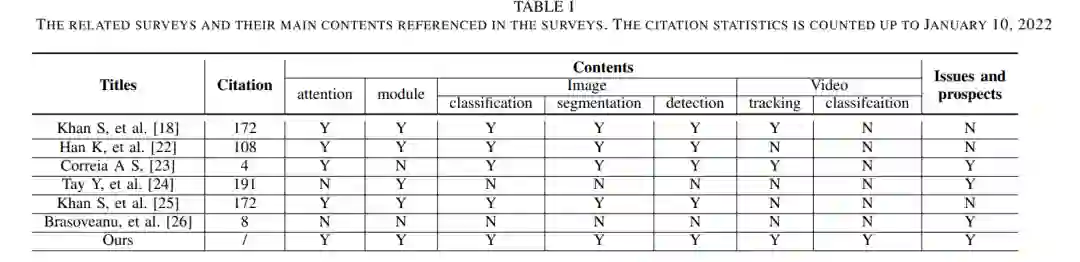
对比[18]、[22]-[24]、[26]等相关综述,从Transformer的模型机制、视觉学习理解应用的应用进展、各种模型在公共基准上的性能比较等方面进行了全面的研究。相关综述及其主要内容见表一。这篇综述旨在让读者全面了解Transformer、其原理以及现有的应用进展。此外,还为所研究的图像和视频研究提供了实验比较。同时,也为深度学习研究者提供了进一步的思路。这项综述的主要贡献如下:
- 全面研究了基于Transformer的视觉学习理解方法,并给出了一些评论。
- 对注意力机制进行了回顾,它在Transformer中起着至关重要的作用。
- 对原始可视化Transformer模型的每个部分进行了详细说明。充分理解视觉Transformer的原理是至关重要的。
- 总结了基于Transformer模型在视觉学习理解方面的应用进展,包括图像分类、目标跟踪、图像分割、目标跟踪、视频分类等。然后,在每个小节中给出了各模型的性能比较,为相关研究人员提供了实验比较。
- 总结Transformer的十大公共问题。为研究人员提供进一步的研究思路。
注意力机制
注意力机制是20世纪90年代提出的。它指的是将人类的感知和注意行为应用到机器上,机器可以学习感知数据中重要和不重要的部分。在CV中,注意力机制让机器感知图像中的目标信息,抑制图像的背景信息。引入注意力机制可以缓解深度学习中计算能力和优化算法的限制。
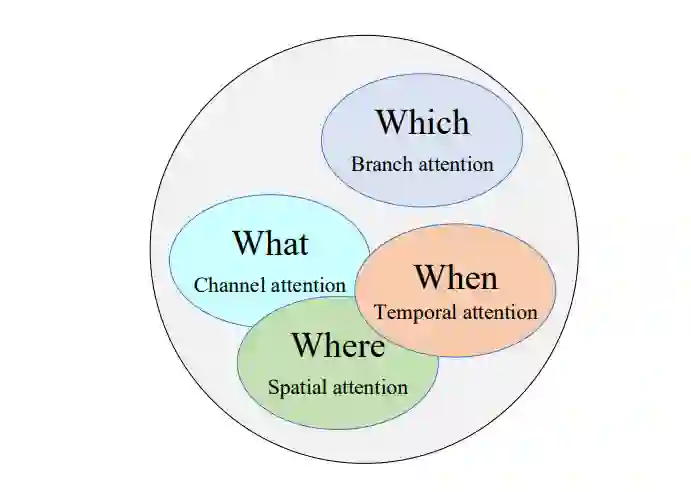
根据不同的角度[28]对现有的深度学习注意机制进行了分类。解码时是否考虑编码器的所有隐藏状态,分为全局注意力机制和局部注意力机制。从注意力域的角度看,可分为注意力域、空间力域、通道域和混合域。根据编码方式的不同,可分为软注意力机制、硬注意力机制和自注意力机制。其中,自注意力是Transformer模型的研究核心。
Transformers
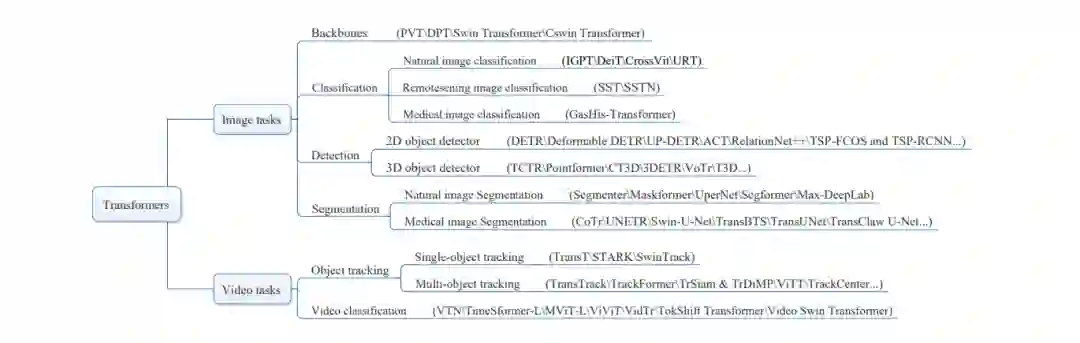
Transformers的视觉学习和理解框架。针对图像任务,主要研究了基于Transformer的主干、图像分类、目标检测和图像分割。针对视频任务,综述了基于Transformer的目标跟踪、视频分类方法。
图像分类、目标检测和图像分割是图像分类的三个基本任务。针对这三项任务的基于Transformer的方法已经得到了很好的发展。有基于Transformer的骨干和基于Transformer的颈部。前者在所有的三个任务中进行评估,而后者通常在其中任何一个任务中进行评估。研究了相关的Transformer模型及其相应的实验结果。
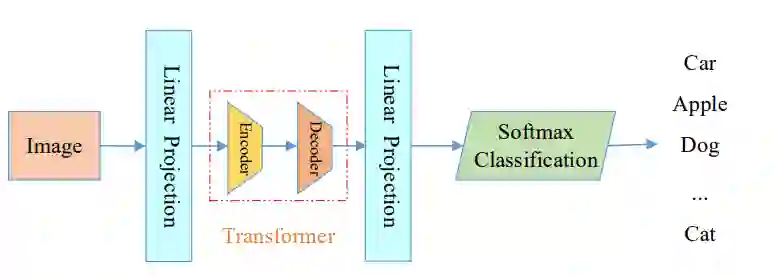
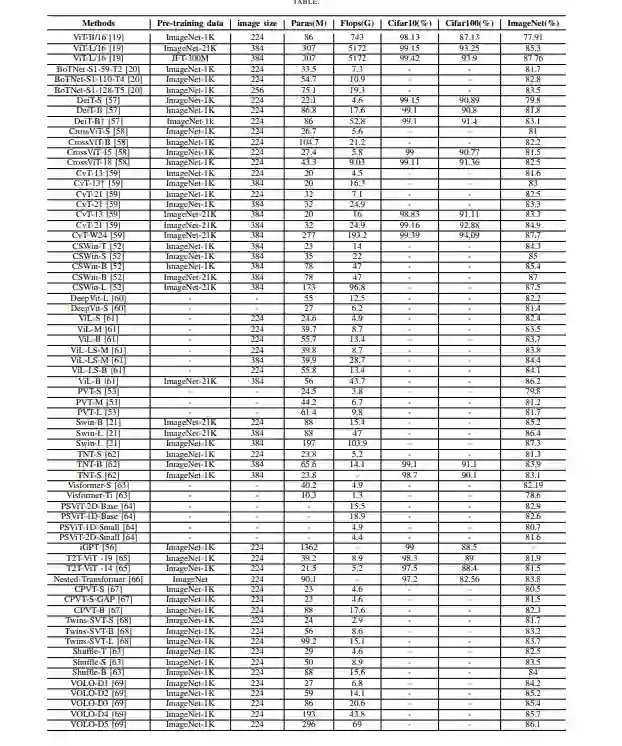
基于Transformer的图像分类的总体框架
Transformer在视频学习和理解方面得到了发展,包括目标跟踪、视频分类和视频分割。本节主要研究基于Transformer的目标跟踪和视频分类方法。
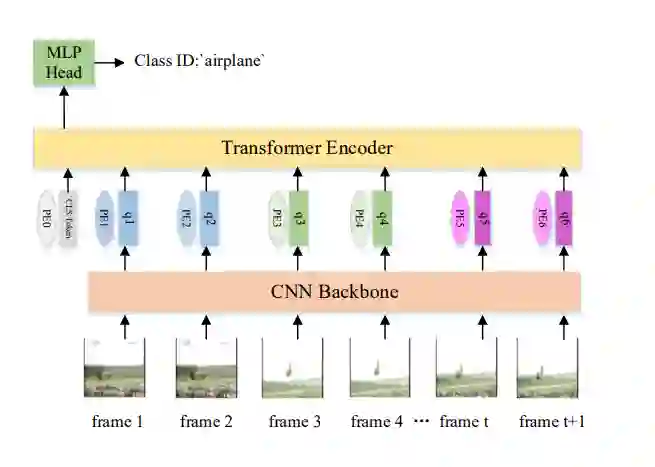
基于Transformer的视频分类的总体框架
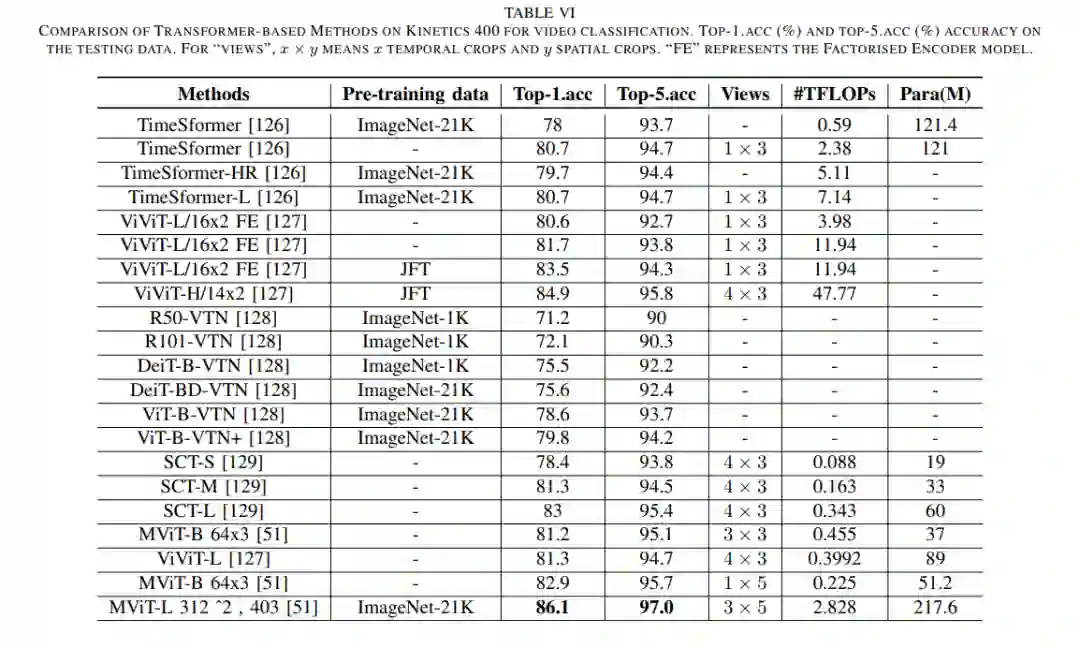
总结
本文对Transformer在视觉学习理解方面的发展进行了全面的研究,并提出了一些看法。值得注意的是,基于transformer方法的一些关键实验性能统计数据在多个图像和视频任务中得到了展示,为研究人员提供了实验性能参考。同时,提出了基于Transformer的模型计算复杂、局部表示能力弱、依赖于大量预训练数据等10个开放性问题。当然,也提出了一些发展方向。本综述旨在使研究者对基于Transformer的研究有一个全面的认识,这对促进Transformer的发展具有重要意义。


