BERT-flow|CMUx字节推出简单易用的文本表示新SOTA!

因为工作和个人信仰的关系,我一直比较关注文本表示的进展。召回是很多NLP系统中必备的一步,而向量化的召回比纯基于文字的离散召回效果更好更合理。同时文本表示还可以做很多事情,比如聚类、分类,不过更多地还是用在文本匹配上。
2015年到18年间有很多优秀的文本表示模型,祭出宝图:
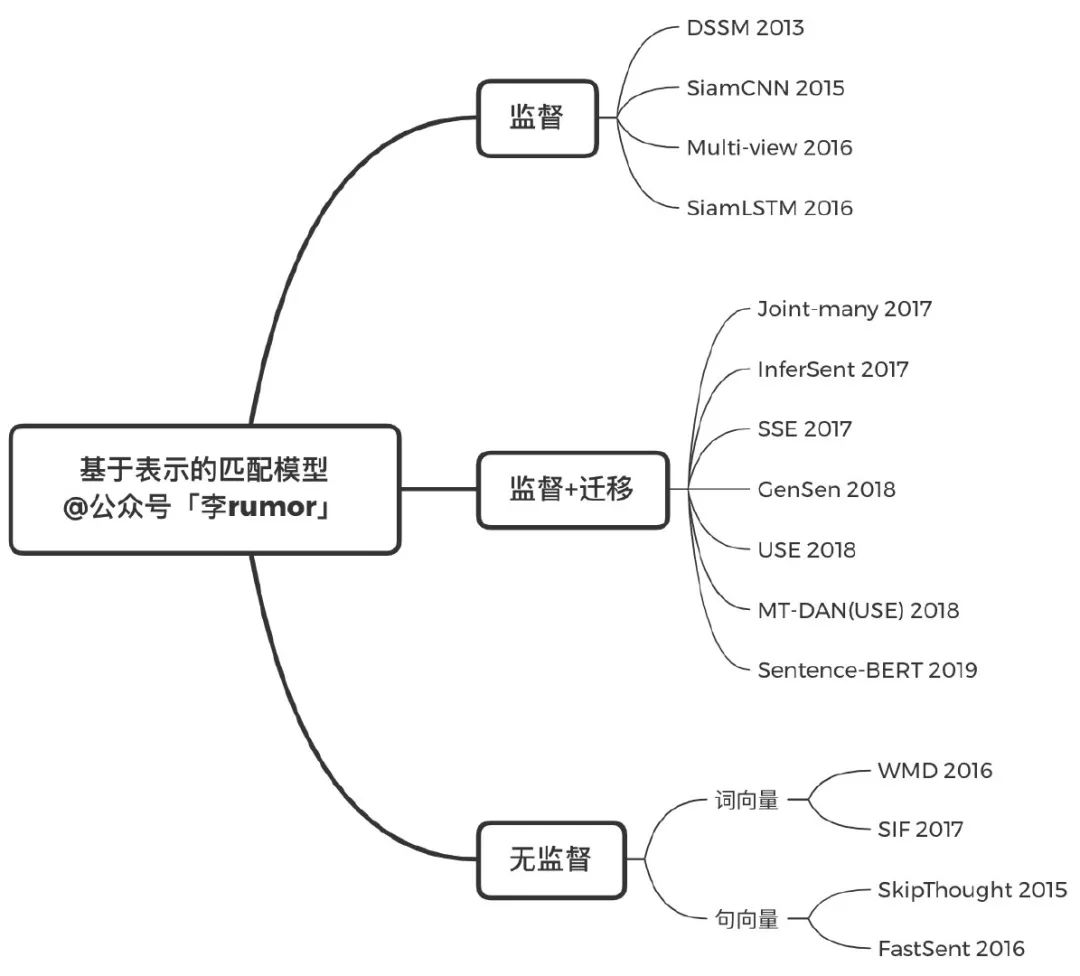
但基于交互的匹配模型明显优于单纯的表示,再加上BERT出来,就很少有人再去研究了,2019年只有一个Sentence-BERT,其实也只是把经典的双塔encoder换成BERT而已,不过总比直接用[CLS]或者对BERT最后一层pooling出来的表示要好。
今年在EMNLP看到了三篇相关文章,一篇是之前解读过的Cross-Thought,还有一篇Manning组同学提出的SLM[1],但这两个都需要预训练,而且也没有和Sentence-BERT直接对比,让我这样很懒的人不方便直接拿来用也不确定真的work多少。

相比之下,今天想介绍的这篇BERT-flow就方便很多,不动BERT的参数,直接在业务数据上无监督训练一个新网络就可以优化BERT输出的表示。同时,作者在前文细致地分析了预训练与语义相关性的联系,并探索了BERT表示的特点,对直接用BERT表示效果不好的现象进行了解释。
论文题目:On the Sentence Embeddings from Pre-trained Language Models
下载地址:https://arxiv.org/pdf/2011.05864.pdf
论文代码:https://github.com/bohanli/BERT-flow
语言模型预训练和语义相关性的联系
先来一个灵魂拷问:
假设文本c的编码是 ,为什么两个文本表示的点积 就能代表它们的语义相似程度呢? (表示归一化后等价于cosine)
有点绕是不是,感觉大家一直都是这么默认的。那让我们从数学角度理解一下,先来看看 和文本中词x的表示 的点积 。这个term出现在了语言模型的优化目标之中:
根据论文[2],对于一个充分训练的语言模型来说:
其中 是词的概率, 是跟上下文c相关的term。 是互信息,表示词与上下文的共现,PMI越大共现概率越大,同时统计意义上的共现也暗示了两者语境、语义的接近。 也可以这样解释。
那语言模型预训练是怎样助力文本表示的呢?
在回头看 的计算,语言模型的目标其实就是最大化token与上下文的共现概率。在向这个目标优化时,c 与 x 的表示会不断接近,如果 x 同时也在另一个上下文 c' 中出现了,那 c 与 c' 的距离就会被拉近,因此语言模型的训练会提升表示的质量,让每个句子在空间中找到自己合适的位置。
BERT表示存在的问题
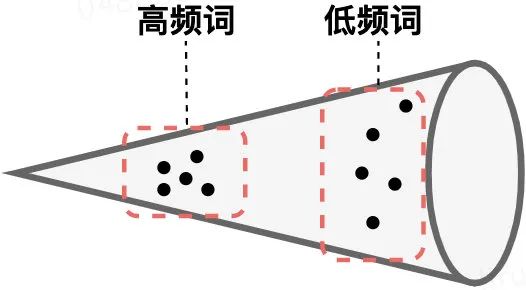
虽然这个道理没毛病,但真正在使用时,不少研究[3] [4]都发现BERT的表示存在一些问题。作者也通过计算表示的L2距离进行了验证,我用力画了一下:
-
BERT的词向量在空间中不是均匀分布,而是呈锥形。作者发现高频词都靠近原点(所有的均值),而低频词远离原点,相当于这两种词处于了空间中不同的区域,那高频词和低频词之间的相似度就不再适用了 -
低频词的分布很稀疏。正如我画的那样,低频词表示得到的训练不充分,分布稀疏,导致该区域存在语义定义不完整的地方(poorly defined),这样算出来的相似度也有问题。
BERT-flow
基于以上对相似度的深入探讨和问题研究,作者提出了BERT-flow,基于流式生成模型,将BERT的表示可逆地映射到一个均匀的空间,上述的问题就迎刃而解了:
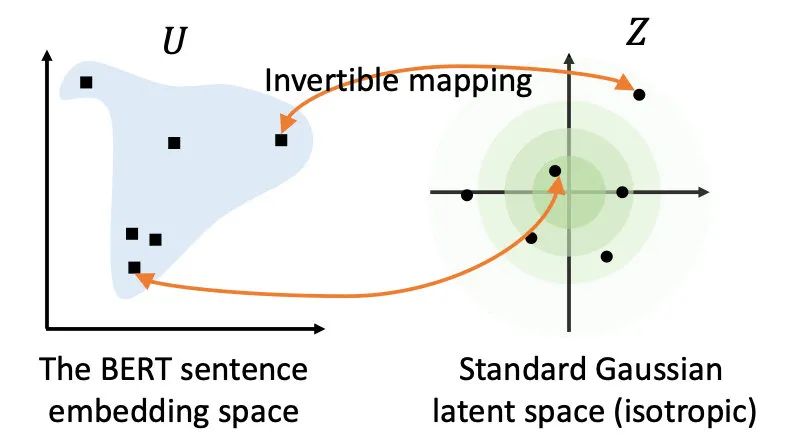
关于流式生成模型的原理可以再写一篇文章了,简单的说就是学习一个可逆的映射 ,把服从高斯分布的变量 映射到BERT编码的 ,那 就可以把 到均匀的高斯分布,这时我们最大化从高斯分布中产生BERT表示的概率,就学习到了这个映射:
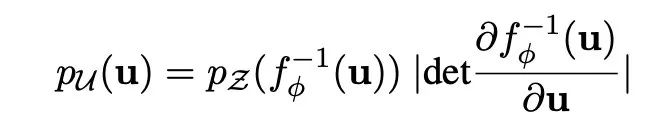
感兴趣的同学可以阅读以下三篇论文[5]:
ICLR 2015 NICE-Non-linear Independent Components Estimation
ICLR 2017 Density estimation using Real NVP
NIPS 2018 Glow: Generative Flow with Invertible 1×1 Convolutions
作者对2018年OpenAI提出的Glow模型进行了简化,用BERT生成的任务数据表示(无标签)作为输入训练模型。
实验效果
作者分别在任务数据(train+dev+test)和 NLI(SNLI+MNLI)数据上无监督地训练流式模型,就得到了比BERT本身要好十多个点的结果:
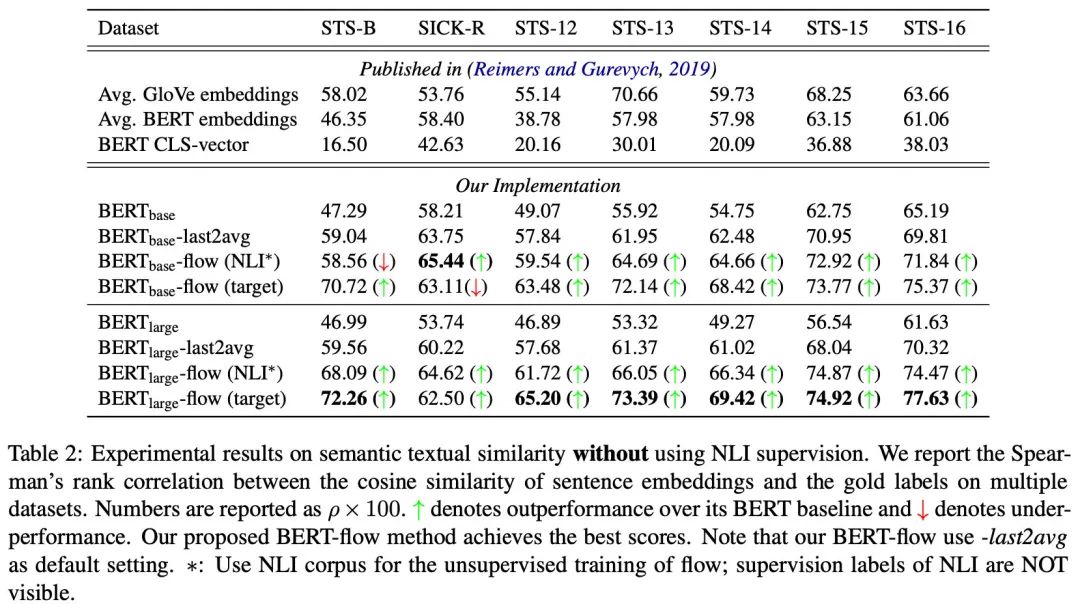
另外作者还发现,取BERT最后两层的平均要比取最后一层要好很多。
是不是还没跟Sentence-BERT(SBERT)比呢?别急,作者采用Sentence-BERT的方式在NLI语料上进行了精调,效果最高好了4个点:
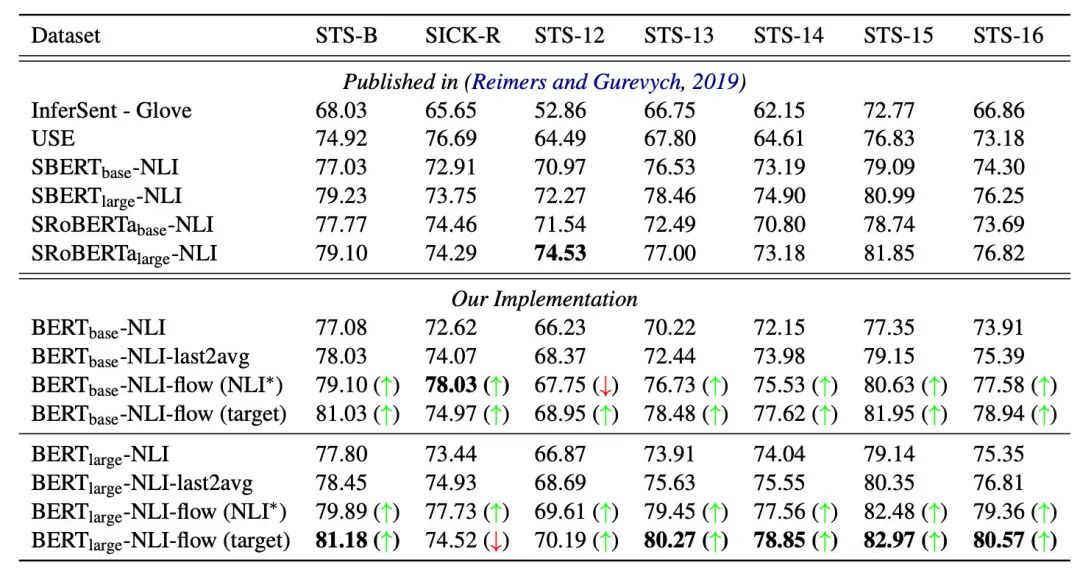
除了SemEval上的对比之外,后续作者还和其他normalisation的方法进行了对比,最好的也比BERT-flow差2个点。
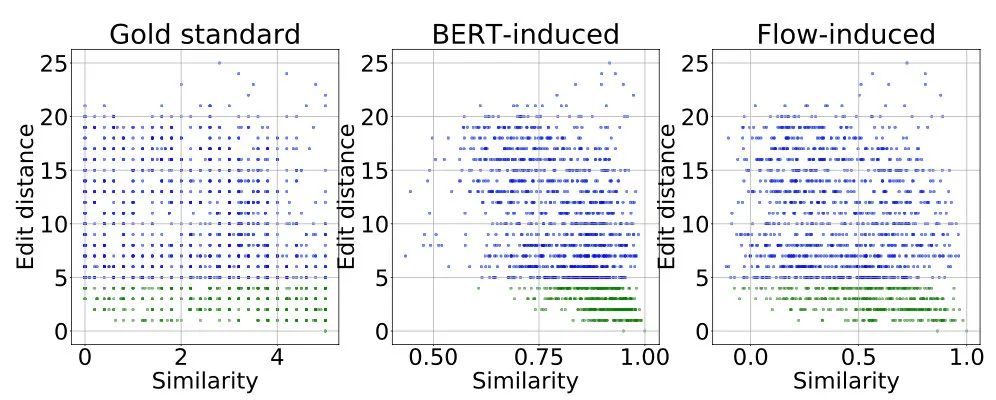
最后作者还研究了语义相似度和字面相似度的关系,结果显示在BERT的表示下,编辑距离小于4的句子语义相似度很高,但这显然是不对的,在文本中随便加一个「不」字都会让这两句话意思相反。而BERT-flow则可以改善这种情况:
总结
这篇工作是实至名归的文本表示新SOTA,不仅可以利用无监督数据,又可以不动BERT本身的参数,减少了训练时间。虽然改进比较简单,但对BERT表示进行了深入的分析,让我们意识到了更多问题。
对了,英文的NLI数据很好用,但中文就比较匮乏,需要数据的小伙伴建议使用哈工大的LCQMC[6]数据集,最近CLUE上也出了一个OCNLI[7],不过只有5W训练数据,亲测20W的LCQMC更好用些。
参考资料
SLM: Learning a Discourse Language Representation with Sentence Unshuffling: https://arxiv.org/abs/2010.16249
[2]Breaking the softmax bot- tleneck: A high-rank rnn language model: https://arxiv.org/abs/1711.03953
[3]Representation Degeneration Problem in Training Natural Language Generation Models: https://arxiv.org/abs/1907.12009
[4]Improving Neural Language Generation with Spectrum Control: https://openreview.net/forum?id=ByxY8CNtvr
[5]Flow-based生成模型: https://zhuanlan.zhihu.com/p/43157737
[6]LCQMC: A Large-scale Chinese Question Matching Corpus: http://icrc.hitsz.edu.cn/Article/show/171.html
[7]OCNLI: Original Chinese Natural Language Inference: https://arxiv.org/abs/2010.05444
由于微信平台算法改版,公号内容将不再以时间排序展示,如果大家想第一时间看到我们的推送,强烈建议星标我们和给我们多点点【在看】。星标具体步骤为:
(1)点击页面最上方"AINLP",进入公众号主页。
(2)点击右上角的小点点,在弹出页面点击“设为星标”,就可以啦。
感谢支持,比心

推荐阅读
征稿启示| 200元稿费+5000DBC(价值20个小时GPU算力)
完结撒花!李宏毅老师深度学习与人类语言处理课程视频及课件(附下载)
模型压缩实践系列之——bert-of-theseus,一个非常亲民的bert压缩方法
文本自动摘要任务的“不完全”心得总结番外篇——submodular函数优化
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。

阅读至此了,分享、点赞、在看三选一吧🙏


