基于表示模型的文本匹配方法

文本匹配是NLU中的一个核心问题,它广泛应用于大量的NLP任务中,如信息检索、问答系统、文本聚类、等等。本文简单总结了几篇经典的基于表示的深度文本匹配论文分享给大家,若有不足之处,请大家指出,后期我会不定期更新“文本匹配”系列文章,敬请期待。
1.概述
文本匹配是自然语言理解中的一个核心问题,它应用于大量的自然语言处理任务中,例如信息检索、问答系统、文本聚类、等等。其中,信息检索可归结为query和文档资源的匹配,问答系统可以归为问题和候选问题的匹配,文本聚类可归结为各文本间的匹配问题。
传统的文本匹配技术主要有Jaccard、Levenshtein、Simhash、TF-idf、Bm25、VSM等算法,其主要是基于统计学方法通过词汇重合度来计算两段文本的字面相似度。然而,仅通过字面相似度是衡量文本的匹配度是远远不够的,因为同一语义的文本在形式上千变万化,两段文本可以表现为字面相似但词序不同而导致语义完全相反;可以表现为字面相似但个别字词不同而导致意思大相径庭;更可以表现为字面完全不相似而语义相同;等等问题。所以,传统的匹配算法存在着词义局限、结构局限等问题。近年来随着深度学习的迅猛发展,各类基于深度学习的文本匹配方法也如雨后春笋一般应运而生。
一般来说,深度文本匹配方法主要分为表示型和交互型。表示型模型主要是将两两段文本转换成一个语义向量,然后计算两向量的相似度,其更侧重对语义向量表示层的构建,它的优势是结构简单、解释性强,且易于实现,是深度学习出现之后应用最广泛的深度文本匹配方法。典型的网络结构有 DSSM、LSTM 和 ESIM,接下来将逐篇进行解读。
2.论文解读
2.1 基于LSTM
论文:《Siamese Recurrent Architectures for Learning Sentence Similarity》
其主要思想是:将两个不一样长的句子,分别经过LSTM编码成相同尺度的稠密向量,以此来比较两个句子的相似性。基于表示的文本匹配模型都是基于这种结构,即向量表示层+相似度计算层。模型结构如下图所示:
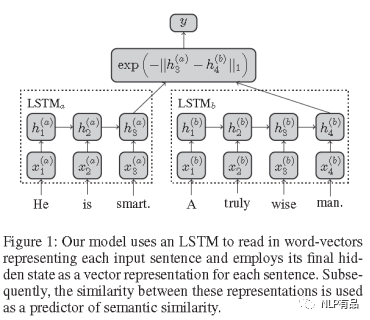
(1)词嵌入层
输入:句子对T1、T2,对齐后长度为m;
输出:两句子的词嵌入矩阵。
(2)隐层
使用LSTM计算长距离语义特征,并且该层参数是共享的,
输入:两句子的词嵌入矩阵;
输出:取两句子经过LSTM计算后最后时刻输出分别作为两句子的语义特征向量s1、s2,向量维度为hsize,hsize为LSTM隐层大小超参。
(3)输出层:
输入:两句子的语义特征向量s1、s2;
输出:计算s1、s2曼哈顿距离(L1距离),并使用负指数函数归一化得相似度分数;
2.2 基于bi-LSTM
大体结构同基于LSTM,主要在三点上做了改进:
(1)将LSTM换为bi-LSTM;
(2)将两句子bi-LSTM各时刻的输出相减得相似性特征s;
(3)相似性特征s后接全连接层映射为2分类。
2.3 基于ESIM
论文:《Enhanced LSTM for Natural Language Inference》
模型主要有五部分组成:词嵌入层、input encoding、local inference modeling、inference composition、以及全连接层。模型结构如下图所示:
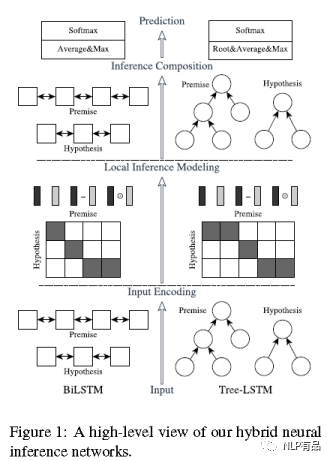
输入:句子对T1、T2,对齐后长度为m;
输出:两句子的词嵌入矩阵。
(2)input encoding(输入编码)
使用 BILSTM来学习词以及他的上下文特征,或者使用treeLSTM语法树的结构收集词组和从句中的局部信息。
输入:两句子的词嵌入矩阵;
输出:经过bi-LSTM编码后的新的词向量。
(3) Local Inference Modeling(局部推断建模)
输入:经过bi-LSTM编码后的新的词向量;
计算方法:1)先计算两个句子word之间的相似度,得到2维的相似度矩阵e,使用点积dot实现;2)然后计算基于句子的局部推断,用上一步的相似度矩阵,用句子T2的bj来生成相似度加权的T1的ai(hat),反过来,用句子T1的word ai来生成相似度加权的T2的 bj(hat),其中,加权是用softmax实现的;3) 把a 和a(hat)计算差和点积,同理,b和b(hat)。然后将多特征做拼接:
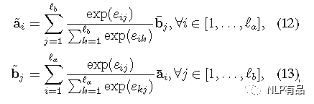
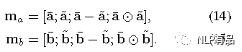
(4) Inference Composition(推断组件)
再一次用到Bi-lstm 对 ma、mb 进行特征提取。然后同时运用 MaxPooling 和 AvgPooling进行池化操作。然后将多特征做拼接得相似性特征v:
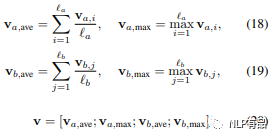
(5)全连接层(MLP)
3 总结
这种模型的优点是结构简单、解释性强,其缺点是得到的句子表示可能会失去语义焦点,容易发生语义偏移,词的上下文重要性难以衡量。为解决这些不足,近年来基于交互型的文本匹配模型相继出现,这一内容将会在放在姊妹篇‘基于交互的文本匹配解读’一文中分享。
下次更新内容可能包括:基于交互模型的文本匹配方法、NLP竞赛平台一览、八大排序算法的java与python实现其中之一,敬请期待♥♥♥。
参考
[1] arxiv:Learning deep structured semantic models for web search using clickthrou- gh data.
[2] arxiv:Siamese Recurrent Architectures for Learning Sentence Similarity.
[3] arxiv:Enhanced LSTM for Natural Language Inference.
[4] CSDN:文本匹配(语义相似度/行为相关性)技术综述.
推荐阅读
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
太赞了!Springer面向公众开放电子书籍,附65本数学、编程、机器学习、深度学习、数据挖掘、数据科学等书籍链接及打包下载
深度学习如何入门?这本“蒲公英书”再适合不过了!豆瓣评分9.5!【文末双彩蛋!】
数学之美中盛赞的 Michael Collins 教授,他的NLP课程要不要收藏?
模型压缩实践系列之——bert-of-theseus,一个非常亲民的bert压缩方法
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。





