几种句子表示方法的比较
最近发现了一个有趣的nlp网站:nlp-town,有很多不错的博客文章,也有一些nlpnotebook代码。我觉得非常值得入门者看看。在本篇文章中,我们摘取了其中一篇博客《Comparing Sentence Similarity Methods》中的精华,简单介绍一下各种句子表示方法。喜欢速食的小伙伴请直接看文末的结论。
一、句子表示及其相似度计算有哪些应用呢?
搜索引擎
基于Q-A对的对话机器人
quora\知乎重复问题识别
等等
二、常见的句子向量的表示方法有哪些?
非监督学习的句子表示
1. 句子中所有词的向量之和的平均值
这种方法过于粗暴,改进的办法有1)忽略stopwords 2)使用tf-idf对词汇进行加权
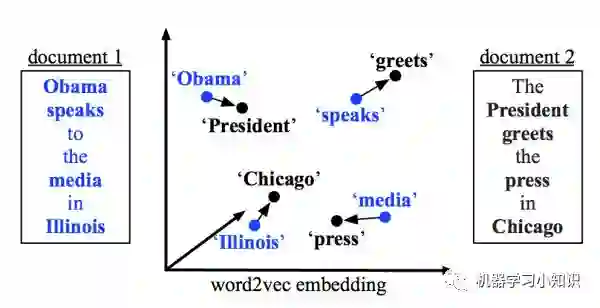
2. WDM (Word Mover's Distance)
如下图所示,该相似度定义为document_1中词汇与document_2对应词汇的‘travel’代价,这里可以简单理解为travel距离之和。
3. SIF (Smooth Inverse Frequency)
类似于tf-idf对于高频出现的词汇降权,得到句子表示
与tf-idf不同的是,SIF对一组句子组成的词向量矩阵A,求A的最大特征值对应的特征向量V,然后将句子表示减去该编码在该特征向量上的投影,从而得到句子向量
这样做的目的是为了降低词频和句法对语义的影响
总之,SIF能够降低just,but等词汇的权重,保留那些对句子语义有用的词汇。
有监督学习的句子表示
这里考察了两个方法:Facebook的InferSent和Google的Sentence Encoder。
1. Facebook的InferSent
基于BiLSTM模型, 使用了SNLI数据集进行训练,包含57万个句子对,有三个类别标签:entailment(蕴含), contradiction(对立)和 neutral(中立)。
2. Google Sentence Encoder的两种形式:
1)基于transformer模型,根据上下文相关的词向量表示进行求和来表示句子的向量
2)使用Deep Averaging Network (DAN),即 unigram和bigram的向量都要经过一个feed-forward 神经网络的编码
ps: 基于transformer的Google Sentence Encoder效果好于DAN,但因为Google并未开放基于transformer的Sentence Encoder,所以本文中仅仅使用了基于DAN的句子向量编码。Google Sentence Encodere与Facebbok InferSent不同,Google不仅使用了labeled的句子,也结合了无标签数据训练得到的词向量。
三、测试数据
作者使用了两个学术界常用的数据集进行评测,都是经过人工标注的。
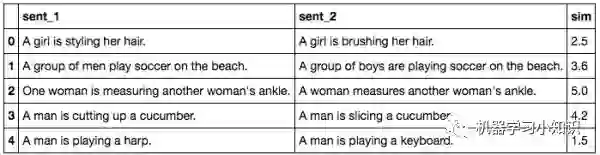
1. STS Benchmark:SemEval句子相似度测评比赛(2012-2017),如下图所示
2. SICK data:包含1万个英文句子对。
四、句子相似度衡量标准
本文仅采用了cosine相似度来衡量句子相似度
五、实验结果
实验结果图例横坐标中的DEV表示验证集,TEST表示测试集。
实验1:词向量平均或加权平均
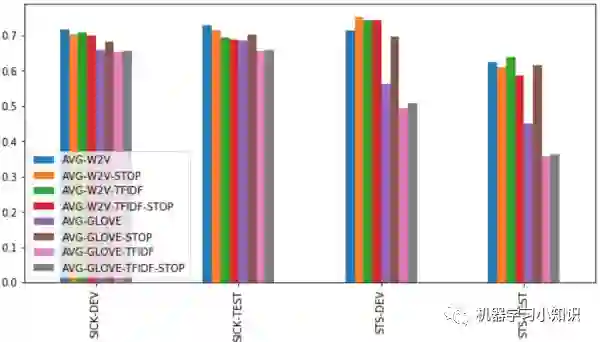
图中左下角方法介绍:
AVG-W2V: 保留stopwords,对句子中的word2vec词向量求平均
AVG-W2V-STOP: 除去stopwords,对句子中的word2vec词向量求平均 - AVG-GLOVE-TFIDF-STOP:除去stopwords,使用tf-idf作为权重对句子中的Glove词向量加权求均值
小结论:
1. word2vec词向量的效果普遍优于glove
2. 是否保留stopwords,是否使用tf-idf进行加权 对于实验结果影响不大,STS数据集上,删除stopwords并使用tf-idf加权有效果,SICK数据集上则没有什么效果。也就是说,这些技巧在某些数据集上的表现还不如简单的word2vec的简单平均。
3. 使用glove词向量时,想要得到好的效果,最好删除stopwords。
实验2:考察WMD与词向量平均
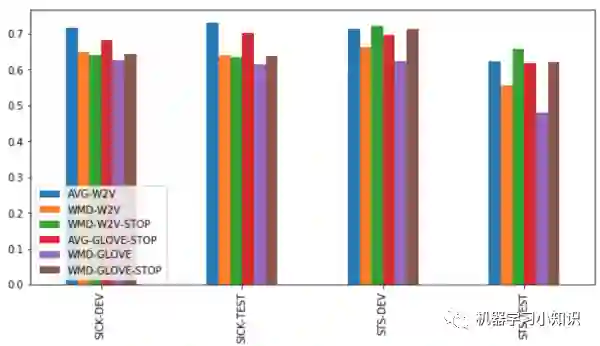
小结论:
WMD普遍效果比较差,仅有少数情况优于简单的词向量平均,不建议使用
实验3:SIF与词向量平均
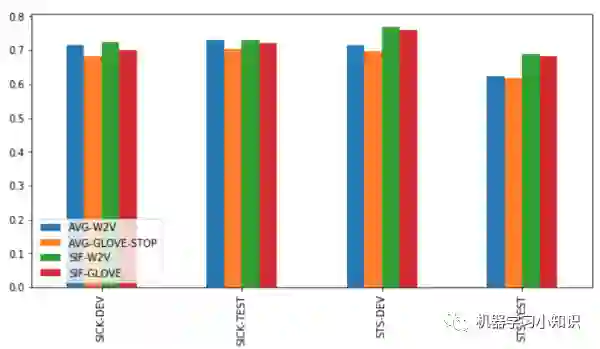
小结论:
1. SIF的表现最为稳定
2. STS数据集上SIF-word2vec远超词向量平均
3. SIF-Word2vec的表现明显强于SIF-glove(这里抛出一个问题:word2vec与glove有什么区别,为什么glove的效果普遍比较差?)
4.SIF的加权和特征向量的删除,有效降低了无用词汇所带来的噪声,使得模型表现非常稳定。
实验4:InferSent、GSE与词向量平均
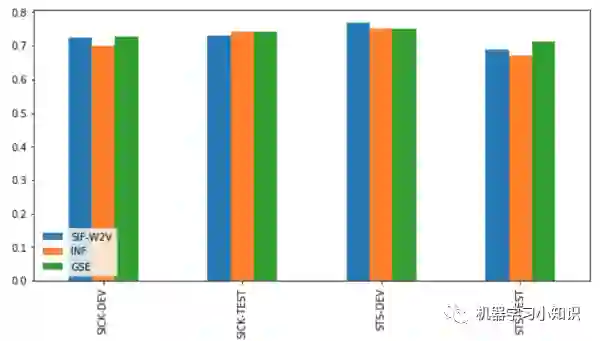
小结论:
1. Google Sentence Encoder(GSE)在测试集上的表现优于Facebook的方法,也优于词向量平均的方法。
2. 使用皮尔逊相关系数对句子表示进行分析,可以发现GSE与SIF的相关度比较高(ps:使用皮尔逊相关系数需要满足的三个条件:连续数据,正态分布,线性关系)
3. 作者认为词向量的表示并非连续数据且不一定满足正太分布,所以采用皮尔逊相关系数并不合适,所以采用了spearman相关系数,结果发现GSE与SIF的相关度比较低
六、结论
句子表示及句子对的相似度计算是一个非常大且非常复杂的研究课题。本文仅仅在Sck和STS两个数据集上,基于cosine similarity,简单探讨了常见的几种句子表示方法的异同,得出了如下结论:
1. word2vec效果比glove更好
2. 词向量的平均作为句子表示的效果还不错,SIF with word2vec效果会更好一些。
3. Google's Sentence Encoder的句子表示效果更好一些,但并不会给模型带来非常显著的提升。
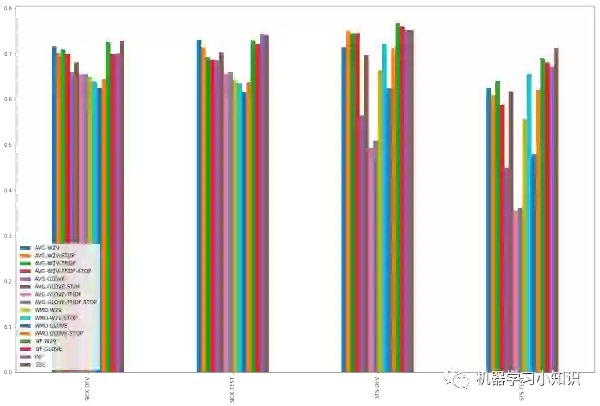
实验结果汇总如下:
七、参考文献
SIF: A Simple but Tough-to-Beat Baseline for Sentence Embeddings
WMD: From Word Embeddings To Document Distances
GSE: Universal Sentence Encoder
InferSent: facebookresearch/InferSent



