一文看尽15种语义分割损失函数(含代码解析)
点击上方“CVer”,选择加"星标"置顶
重磅干货,第一时间送达

本文转载自:AI算法修炼营 | 论文已上传,文末附下载方式
这是一篇关于图像分割损失函数的总结,具体包括:
Binary Cross Entropy
Weighted Cross Entropy
Balanced Cross Entropy
Dice Loss
Focal loss
Tversky loss
Focal Tversky loss
log-cosh dice loss (本文提出的新损失函数)

论文地址:https://arxiv.org/abs/2006.14822
代码地址:
https://github.com/shruti-jadon/Semantic-Segmentation-Loss-Functions图像分割一直是一个活跃的研究领域,因为它有可能修复医疗领域的漏洞,并帮助大众。在过去的5年里,各种论文提出了不同的目标损失函数,用于不同的情况下,如偏差数据,稀疏分割等。在本文中,总结了大多数广泛用于图像分割的损失函数,并列出了它们可以帮助模型更快速、更好的收敛模型的情况。此外,本文还介绍了一种新的log-cosh dice损失函数,并将其在NBFS skull-stripping数据集上与广泛使用的损失函数进行了性能比较。某些损失函数在所有数据集上都表现良好,在未知分布数据集上可以作为一个很好的选择。
深度学习彻底改变了从软件到制造业的各个行业。深度学习在医学界的应用也十分广泛,例如使用U-Net进行肿瘤分割、使用SegNet进行癌症检测等。在这些应用中,图像分割是至关重要的,分割后的图像除了告诉我们存在某种疾病外,还展示了它到底存在于何处,这为实现自动检测CT扫描中的病变等功能提供基础保障。
图像分割可以定义为像素级别的分类任务。图像由各种像素组成,这些像素组合在一起定义了图像中的不同元素,因此将这些像素分类为一类元素的方法称为语义图像分割。在设计基于复杂图像分割的深度学习架构时,通常会遇到了一个至关重要的选择,即选择哪个损失/目标函数,因为它们会激发算法的学习过程。损失函数的选择对于任何架构学习正确的目标都是至关重要的,因此自2012年以来,各种研究人员开始设计针对特定领域的损失函数,以为其数据集获得更好的结果。
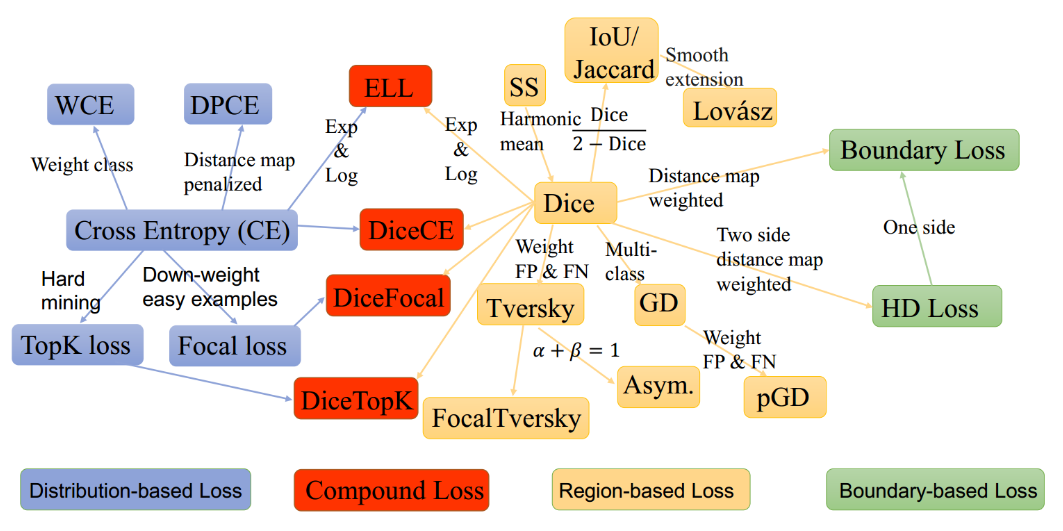
在本文中,总结了15种基于图像分割的损失函数。被证明可以在不同领域提供最新技术成果。这些损失函数可大致分为4类:基于分布的损失函数,基于区域的损失函数,基于边界的损失函数和基于复合的损失函数( Distribution-based,Region-based, Boundary-based, and Compounded)。
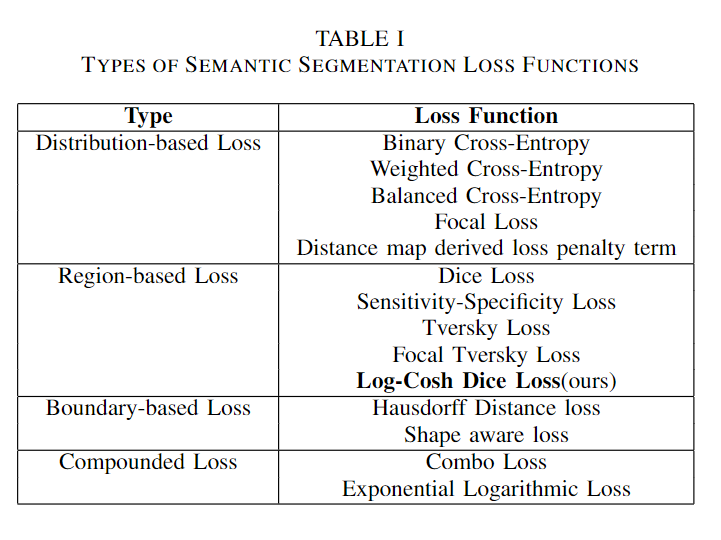
本文还讨论了确定哪种目标/损失函数在场景中可能有用的条件。除此之外,还提出了一种新的log-cosh dice损失函数用于图像语义分割。为了展示其效率,还比较了NBFS头骨剥离数据集上所有损失函数的性能。
1. Binary Cross-Entropy:二进制交叉熵损失函数
交叉熵定义为对给定随机变量或事件集的两个概率分布之间的差异的度量。它被广泛用于分类任务,并且由于分割是像素级分类,因此效果很好。在多分类任务中,经常采用 softmax 激活函数+交叉熵损失函数,因为交叉熵描述了两个概率分布的差异,然而神经网络输出的是向量,并不是概率分布的形式。所以需要 softmax激活函数将一个向量进行“归一化”成概率分布的形式,再采用交叉熵损失函数计算 loss。
交叉熵损失函数的具体表达为:

其中,


交叉熵损失函数可以用在大多数语义分割场景中,但它有一个明显的缺点:当图像分割任务只需要分割前景和背景两种情况。当前景像素的数量远远小于背景像素的数量时,即 的数量远大于 的数量,损失函数中 的成分就会占据主导,使得模型严重偏向背景,导致效果不好。
#二值交叉熵,这里输入要经过sigmoid处理
import torch
import torch.nn as nn
import torch.nn.functional as F
nn.BCELoss(F.sigmoid(input), target)
#多分类交叉熵, 用这个 loss 前面不需要加 Softmax 层
nn.CrossEntropyLoss(input, target)
2、Weighted Binary Cross-Entropy加权交叉熵损失函数
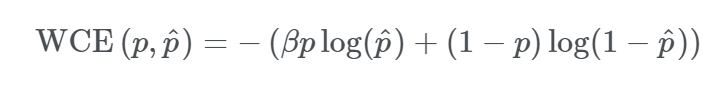
加权交叉熵损失函数只是在交叉熵Loss的基础上为每一个类别添加了一个权重参数为正样本加权。设置 
class WeightedCrossEntropyLoss(torch.nn.CrossEntropyLoss):
"""
Network has to have NO NONLINEARITY!
"""
def __init__(self, weight=None):
super(WeightedCrossEntropyLoss, self).__init__()
self.weight = weight
def forward(self, inp, target):
target = target.long()
num_classes = inp.size()[1]
i0 = 1
i1 = 2
while i1 < len(inp.shape): # this is ugly but torch only allows to transpose two axes at once
inp = inp.transpose(i0, i1)
i0 += 1
i1 += 1
inp = inp.contiguous()
inp = inp.view(-1, num_classes)
target = target.view(-1,)
wce_loss = torch.nn.CrossEntropyLoss(weight=self.weight)
return wce_loss(inp, target)3、Balanced Cross-Entropy平衡交叉熵损失函数
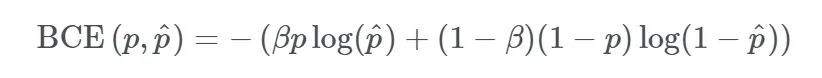
与加权交叉熵损失函数类似,但平衡交叉熵损失函数对负样本也进行加权。
4、Focal Loss
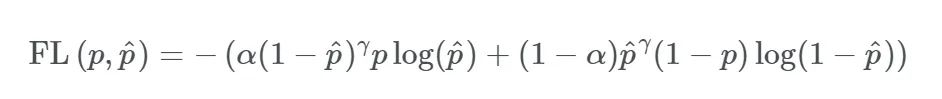
Focal loss是在目标检测领域提出来的。其目的是关注难例(也就是给难分类的样本较大的权重)。对于正样本,使预测概率大的样本(简单样本)得到的loss变小,而预测概率小的样本(难例)loss变得大,从而加强对难例的关注度。但引入了额外参数,增加了调参难度。
class FocalLoss(nn.Module):
"""
copy from: https://github.com/Hsuxu/Loss_ToolBox-PyTorch/blob/master/FocalLoss/FocalLoss.py
This is a implementation of Focal Loss with smooth label cross entropy supported which is proposed in
'Focal Loss for Dense Object Detection. (https://arxiv.org/abs/1708.02002)'
Focal_Loss= -1*alpha*(1-pt)*log(pt)
:param num_class:
:param alpha: (tensor) 3D or 4D the scalar factor for this criterion
:param gamma: (float,double) gamma > 0 reduces the relative loss for well-classified examples (p>0.5) putting more
focus on hard misclassified example
:param smooth: (float,double) smooth value when cross entropy
:param balance_index: (int) balance class index, should be specific when alpha is float
:param size_average: (bool, optional) By default, the losses are averaged over each loss element in the batch.
"""
def __init__(self, apply_nonlin=None, alpha=None, gamma=2, balance_index=0, smooth=1e-5, size_average=True):
super(FocalLoss, self).__init__()
self.apply_nonlin = apply_nonlin
self.alpha = alpha
self.gamma = gamma
self.balance_index = balance_index
self.smooth = smooth
self.size_average = size_average
if self.smooth is not None:
if self.smooth < 0 or self.smooth > 1.0:
raise ValueError('smooth value should be in [0,1]')
def forward(self, logit, target):
if self.apply_nonlin is not None:
logit = self.apply_nonlin(logit)
num_class = logit.shape[1]
if logit.dim() > 2:
# N,C,d1,d2 -> N,C,m (m=d1*d2*...)
logit = logit.view(logit.size(0), logit.size(1), -1)
logit = logit.permute(0, 2, 1).contiguous()
logit = logit.view(-1, logit.size(-1))
target = torch.squeeze(target, 1)
target = target.view(-1, 1)
# print(logit.shape, target.shape)
#
alpha = self.alpha
if alpha is None:
alpha = torch.ones(num_class, 1)
elif isinstance(alpha, (list, np.ndarray)):
assert len(alpha) == num_class
alpha = torch.FloatTensor(alpha).view(num_class, 1)
alpha = alpha / alpha.sum()
elif isinstance(alpha, float):
alpha = torch.ones(num_class, 1)
alpha = alpha * (1 - self.alpha)
alpha[self.balance_index] = self.alpha
else:
raise TypeError('Not support alpha type')
if alpha.device != logit.device:
alpha = alpha.to(logit.device)
idx = target.cpu().long()
one_hot_key = torch.FloatTensor(target.size(0), num_class).zero_()
one_hot_key = one_hot_key.scatter_(1, idx, 1)
if one_hot_key.device != logit.device:
one_hot_key = one_hot_key.to(logit.device)
if self.smooth:
one_hot_key = torch.clamp(
one_hot_key, self.smooth/(num_class-1), 1.0 - self.smooth)
pt = (one_hot_key * logit).sum(1) + self.smooth
logpt = pt.log()
gamma = self.gamma
alpha = alpha[idx]
alpha = torch.squeeze(alpha)
loss = -1 * alpha * torch.pow((1 - pt), gamma) * logpt
if self.size_average:
loss = loss.mean()
else:
loss = loss.sum()
return loss5、Distance map derived loss penalty term距离图得出的损失惩罚项
可以将距离图定义为ground truth与预测图之间的距离(欧几里得距离、绝对距离等)。合并映射的方法有2种,一种是创建神经网络架构,在该算法中有一个用于分割的重建head,或者将其引入损失函数。遵循相同的理论,可以从GT mask得出的距离图,并创建了一个基于惩罚的自定义损失函数。使用这种方法,可以很容易地将网络引导到难以分割的边界区域。损失函数定义为:
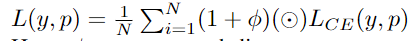
class DisPenalizedCE(torch.nn.Module):
"""
Only for binary 3D segmentation
Network has to have NO NONLINEARITY!
"""
def forward(self, inp, target):
# print(inp.shape, target.shape) # (batch, 2, xyz), (batch, 2, xyz)
# compute distance map of ground truth
with torch.no_grad():
dist = compute_edts_forPenalizedLoss(target.cpu().numpy()>0.5) + 1.0
dist = torch.from_numpy(dist)
if dist.device != inp.device:
dist = dist.to(inp.device).type(torch.float32)
dist = dist.view(-1,)
target = target.long()
num_classes = inp.size()[1]
i0 = 1
i1 = 2
while i1 < len(inp.shape): # this is ugly but torch only allows to transpose two axes at once
inp = inp.transpose(i0, i1)
i0 += 1
i1 += 1
inp = inp.contiguous()
inp = inp.view(-1, num_classes)
log_sm = torch.nn.LogSoftmax(dim=1)
inp_logs = log_sm(inp)
target = target.view(-1,)
# loss = nll_loss(inp_logs, target)
loss = -inp_logs[range(target.shape[0]), target]
# print(loss.type(), dist.type())
weighted_loss = loss*dist
return loss.mean()
1、Dice Loss
Dice系数是计算机视觉界广泛使用的度量标准,用于计算两个图像之间的相似度。在2016年的时候,它也被改编为损失函数,称为Dice损失。
Dice系数:是用来度量集合相似度的度量函数,通常用于计算两个样本之间的像素之间的相似度,公式如下:
或
分子中之所以有一个系数2是因为分母中有重复计算 和 的原因,的取值范围是 。而针对分割任务来说, 表示的就是Ground Truth分割图像,而Y代表的就是预测的分割图像。
Dice Loss:
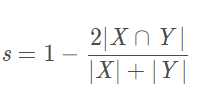
此处,在分子和分母中添加1以确保函数在诸如y = 0的极端情况下的确定性。Dice Loss使用与样本极度不均衡的情况,如果一般情况下使用Dice Loss会回反向传播有不利的影响,使得训练不稳定。
def get_tp_fp_fn(net_output, gt, axes=None, mask=None, square=False):
"""
net_output must be (b, c, x, y(, z)))
gt must be a label map (shape (b, 1, x, y(, z)) OR shape (b, x, y(, z))) or one hot encoding (b, c, x, y(, z))
if mask is provided it must have shape (b, 1, x, y(, z)))
:param net_output:
:param gt:
:param axes:
:param mask: mask must be 1 for valid pixels and 0 for invalid pixels
:param square: if True then fp, tp and fn will be squared before summation
:return:
"""
if axes is None:
axes = tuple(range(2, len(net_output.size())))
shp_x = net_output.shape
shp_y = gt.shape
with torch.no_grad():
if len(shp_x) != len(shp_y):
gt = gt.view((shp_y[0], 1, *shp_y[1:]))
if all([i == j for i, j in zip(net_output.shape, gt.shape)]):
# if this is the case then gt is probably already a one hot encoding
y_onehot = gt
else:
gt = gt.long()
y_onehot = torch.zeros(shp_x)
if net_output.device.type == "cuda":
y_onehot = y_onehot.cuda(net_output.device.index)
y_onehot.scatter_(1, gt, 1)
tp = net_output * y_onehot
fp = net_output * (1 - y_onehot)
fn = (1 - net_output) * y_onehot
if mask is not None:
tp = torch.stack(tuple(x_i * mask[:, 0] for x_i in torch.unbind(tp, dim=1)), dim=1)
fp = torch.stack(tuple(x_i * mask[:, 0] for x_i in torch.unbind(fp, dim=1)), dim=1)
fn = torch.stack(tuple(x_i * mask[:, 0] for x_i in torch.unbind(fn, dim=1)), dim=1)
if square:
tp = tp ** 2
fp = fp ** 2
fn = fn ** 2
tp = sum_tensor(tp, axes, keepdim=False)
fp = sum_tensor(fp, axes, keepdim=False)
fn = sum_tensor(fn, axes, keepdim=False)
return tp, fp, fn
class SoftDiceLoss(nn.Module):
def __init__(self, apply_nonlin=None, batch_dice=False, do_bg=True, smooth=1.,
square=False):
"""
paper: https://arxiv.org/pdf/1606.04797.pdf
"""
super(SoftDiceLoss, self).__init__()
self.square = square
self.do_bg = do_bg
self.batch_dice = batch_dice
self.apply_nonlin = apply_nonlin
self.smooth = smooth
def forward(self, x, y, loss_mask=None):
shp_x = x.shape
if self.batch_dice:
axes = [0] + list(range(2, len(shp_x)))
else:
axes = list(range(2, len(shp_x)))
if self.apply_nonlin is not None:
x = self.apply_nonlin(x)
tp, fp, fn = get_tp_fp_fn(x, y, axes, loss_mask, self.square)
dc = (2 * tp + self.smooth) / (2 * tp + fp + fn + self.smooth)
if not self.do_bg:
if self.batch_dice:
dc = dc[1:]
else:
dc = dc[:, 1:]
dc = dc.mean()
return -dc2、Tversky Loss
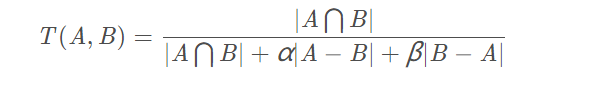
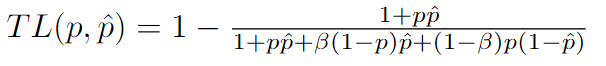
论文地址为:https://arxiv.org/pdf/1706.05721.pdf 。Tversky系数是Dice系数和 Jaccard 系数的一种推广。当设置α=β=0.5,此时Tversky系数就是Dice系数。而当设置α=β=1时,此时Tversky系数就是Jaccard系数。α和β分别控制假阴性和假阳性。通过调整α和β,可以控制假阳性和假阴性之间的平衡。
class TverskyLoss(nn.Module):
def __init__(self, apply_nonlin=None, batch_dice=False, do_bg=True, smooth=1.,
square=False):
"""
paper: https://arxiv.org/pdf/1706.05721.pdf
"""
super(TverskyLoss, self).__init__()
self.square = square
self.do_bg = do_bg
self.batch_dice = batch_dice
self.apply_nonlin = apply_nonlin
self.smooth = smooth
self.alpha = 0.3
self.beta = 0.7
def forward(self, x, y, loss_mask=None):
shp_x = x.shape
if self.batch_dice:
axes = [0] + list(range(2, len(shp_x)))
else:
axes = list(range(2, len(shp_x)))
if self.apply_nonlin is not None:
x = self.apply_nonlin(x)
tp, fp, fn = get_tp_fp_fn(x, y, axes, loss_mask, self.square)
tversky = (tp + self.smooth) / (tp + self.alpha*fp + self.beta*fn + self.smooth)
if not self.do_bg:
if self.batch_dice:
tversky = tversky[1:]
else:
tversky = tversky[:, 1:]
tversky = tversky.mean()
return -tversky
3、Focal Tversky Loss
与“Focal loss”相似,后者着重于通过降低易用/常见损失的权重来说明困难的例子。Focal Tversky Loss还尝试借助γ系数来学习诸如在ROI(感兴趣区域)较小的情况下的困难示例,如下所示:
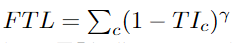
class FocalTversky_loss(nn.Module):
"""
paper: https://arxiv.org/pdf/1810.07842.pdf
author code: https://github.com/nabsabraham/focal-tversky-unet/blob/347d39117c24540400dfe80d106d2fb06d2b99e1/losses.py#L65
"""
def __init__(self, tversky_kwargs, gamma=0.75):
super(FocalTversky_loss, self).__init__()
self.gamma = gamma
self.tversky = TverskyLoss(**tversky_kwargs)
def forward(self, net_output, target):
tversky_loss = 1 + self.tversky(net_output, target) # = 1-tversky(net_output, target)
focal_tversky = torch.pow(tversky_loss, self.gamma)
return focal_tversky
4、Sensitivity Specificity Loss
首先敏感性就是召回率,检测出确实有病的能力:
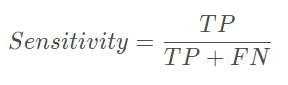
特异性,检测出确实没病的能力:
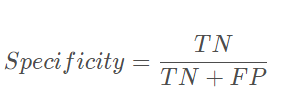
而Sensitivity Specificity Loss为:
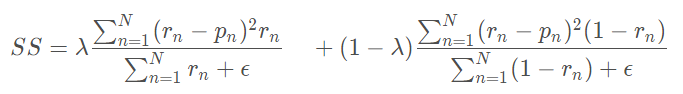
其中左边为病灶像素的错误率即,1−Sensitivity,而不是正确率,所以设置λ 为0.05。其中是为了得到平滑的梯度。
class SSLoss(nn.Module):
def __init__(self, apply_nonlin=None, batch_dice=False, do_bg=True, smooth=1.,
square=False):
"""
Sensitivity-Specifity loss
paper: http://www.rogertam.ca/Brosch_MICCAI_2015.pdf
tf code: https://github.com/NifTK/NiftyNet/blob/df0f86733357fdc92bbc191c8fec0dcf49aa5499/niftynet/layer/loss_segmentation.py#L392
"""
super(SSLoss, self).__init__()
self.square = square
self.do_bg = do_bg
self.batch_dice = batch_dice
self.apply_nonlin = apply_nonlin
self.smooth = smooth
self.r = 0.1 # weight parameter in SS paper
def forward(self, net_output, gt, loss_mask=None):
shp_x = net_output.shape
shp_y = gt.shape
# class_num = shp_x[1]
with torch.no_grad():
if len(shp_x) != len(shp_y):
gt = gt.view((shp_y[0], 1, *shp_y[1:]))
if all([i == j for i, j in zip(net_output.shape, gt.shape)]):
# if this is the case then gt is probably already a one hot encoding
y_onehot = gt
else:
gt = gt.long()
y_onehot = torch.zeros(shp_x)
if net_output.device.type == "cuda":
y_onehot = y_onehot.cuda(net_output.device.index)
y_onehot.scatter_(1, gt, 1)
if self.batch_dice:
axes = [0] + list(range(2, len(shp_x)))
else:
axes = list(range(2, len(shp_x)))
if self.apply_nonlin is not None:
softmax_output = self.apply_nonlin(net_output)
# no object value
bg_onehot = 1 - y_onehot
squared_error = (y_onehot - softmax_output)**2
specificity_part = sum_tensor(squared_error*y_onehot, axes)/(sum_tensor(y_onehot, axes)+self.smooth)
sensitivity_part = sum_tensor(squared_error*bg_onehot, axes)/(sum_tensor(bg_onehot, axes)+self.smooth)
ss = self.r * specificity_part + (1-self.r) * sensitivity_part
if not self.do_bg:
if self.batch_dice:
ss = ss[1:]
else:
ss = ss[:, 1:]
ss = ss.mean()
return ss5、Log-Cosh Dice Loss(本文提出的损失函数)
Dice系数是一种用于评估分割输出的度量标准。它也已修改为损失函数,因为它可以实现分割目标的数学表示。但是由于其非凸性,它多次都无法获得最佳结果。Lovsz-softmax损失旨在通过添加使用Lovsz扩展的平滑来解决非凸损失函数的问题。同时,Log-Cosh方法已广泛用于基于回归的问题中,以平滑曲线。
将Cosh(x)函数和Log(x)函数合并,可以得到Log-Cosh Dice Loss:
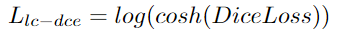
def log_cosh_dice_loss(self, y_true, y_pred):
x = self.dice_loss(y_true, y_pred)
return tf.math.log((torch.exp(x) + torch.exp(-x)) / 2.0)
1、Shape-aware Loss
顾名思义,Shape-aware Loss考虑了形状。通常,所有损失函数都在像素级起作用,Shape-aware Loss会计算平均点到曲线的欧几里得距离,即预测分割到ground truth的曲线周围点之间的欧式距离,并将其用作交叉熵损失函数的系数,具体定义如下:(CE指交叉熵损失函数)
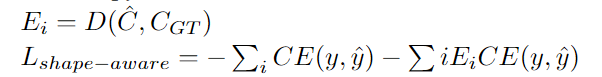
class DistBinaryDiceLoss(nn.Module):
"""
Distance map penalized Dice loss
Motivated by: https://openreview.net/forum?id=B1eIcvS45V
Distance Map Loss Penalty Term for Semantic Segmentation
"""
def __init__(self, smooth=1e-5):
super(DistBinaryDiceLoss, self).__init__()
self.smooth = smooth
def forward(self, net_output, gt):
"""
net_output: (batch_size, 2, x,y,z)
target: ground truth, shape: (batch_size, 1, x,y,z)
"""
net_output = softmax_helper(net_output)
# one hot code for gt
with torch.no_grad():
if len(net_output.shape) != len(gt.shape):
gt = gt.view((gt.shape[0], 1, *gt.shape[1:]))
if all([i == j for i, j in zip(net_output.shape, gt.shape)]):
# if this is the case then gt is probably already a one hot encoding
y_onehot = gt
else:
gt = gt.long()
y_onehot = torch.zeros(net_output.shape)
if net_output.device.type == "cuda":
y_onehot = y_onehot.cuda(net_output.device.index)
y_onehot.scatter_(1, gt, 1)
gt_temp = gt[:,0, ...].type(torch.float32)
with torch.no_grad():
dist = compute_edts_forPenalizedLoss(gt_temp.cpu().numpy()>0.5) + 1.0
# print('dist.shape: ', dist.shape)
dist = torch.from_numpy(dist)
if dist.device != net_output.device:
dist = dist.to(net_output.device).type(torch.float32)
tp = net_output * y_onehot
tp = torch.sum(tp[:,1,...] * dist, (1,2,3))
dc = (2 * tp + self.smooth) / (torch.sum(net_output[:,1,...], (1,2,3)) + torch.sum(y_onehot[:,1,...], (1,2,3)) + self.smooth)
dc = dc.mean()
return -dc
2、Hausdorff Distance Loss
Hausdorff Distance Loss(HD)是分割方法用来跟踪模型性能的度量。它定义为:
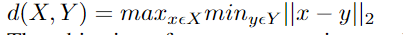
任何分割模型的目的都是为了最大化Hausdorff距离,但是由于其非凸性,因此并未广泛用作损失函数。有研究者提出了基于Hausdorff距离的损失函数的3个变量,它们都结合了度量用例,并确保损失函数易于处理。
class HDDTBinaryLoss(nn.Module):
def __init__(self):
"""
compute haudorff loss for binary segmentation
https://arxiv.org/pdf/1904.10030v1.pdf
"""
super(HDDTBinaryLoss, self).__init__()
def forward(self, net_output, target):
"""
net_output: (batch_size, 2, x,y,z)
target: ground truth, shape: (batch_size, 1, x,y,z)
"""
net_output = softmax_helper(net_output)
pc = net_output[:, 1, ...].type(torch.float32)
gt = target[:,0, ...].type(torch.float32)
with torch.no_grad():
pc_dist = compute_edts_forhdloss(pc.cpu().numpy()>0.5)
gt_dist = compute_edts_forhdloss(gt.cpu().numpy()>0.5)
# print('pc_dist.shape: ', pc_dist.shape)
pred_error = (gt - pc)**2
dist = pc_dist**2 + gt_dist**2 # \alpha=2 in eq(8)
dist = torch.from_numpy(dist)
if dist.device != pred_error.device:
dist = dist.to(pred_error.device).type(torch.float32)
multipled = torch.einsum("bxyz,bxyz->bxyz", pred_error, dist)
hd_loss = multipled.mean()
return hd_loss1、Exponential Logarithmic Loss
指数对数损失函数集中于使用骰子损失和交叉熵损失的组合公式来预测不那么精确的结构。对骰子损失和熵损失进行指数和对数转换,以合并更精细的分割边界和准确的数据分布的好处。它定义为:
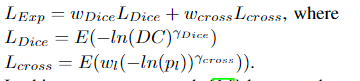
2、Combo Loss
组合损失定义为Dice loss和修正的交叉熵的加权和。它试图利用Dice损失解决类不平衡问题的灵活性,同时使用交叉熵进行曲线平滑。定义为:(DL指Dice Loss)
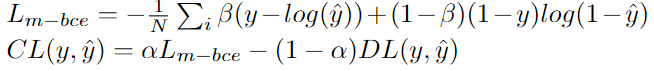
数据集:NBFS Skull Stripping Dataset
实验细节:使用了简单的2D U-Net模型架构
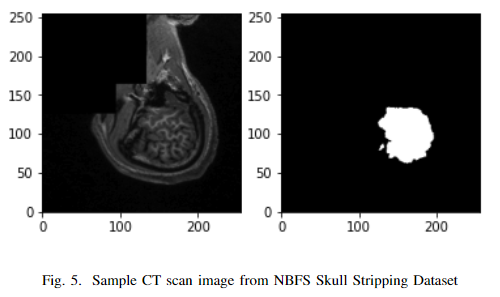
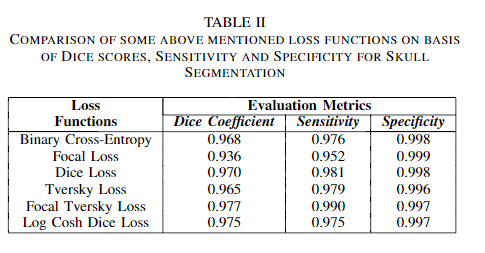
对比实验
参考
[1] https://blog.csdn.net/m0_37477175/article/details/83004746
[2] https://zhuanlan.zhihu.com/p/89194726
论文下载
在CVer公众号后台回复:语义分割损失,即可下载本论文
重磅!CVer-图像分割 交流群已成立
扫码添加CVer助手,可申请加入CVer-图像分割 微信交流群,目前已满1500+人,旨在交流语义分割、实例分割、全景分割和医学图像分割等。
同时也可申请加入CVer大群和细分方向技术群,细分方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch和TensorFlow等群。
一定要备注:研究方向+地点+学校/公司+昵称(如图像分割+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群

▲长按加微信群

▲长按关注CVer公众号
整理不易,请给CVer点赞和在看!



