题目: The History Began from AlexNet: A Comprehensive Survey on Deep Learning Approaches
简介:
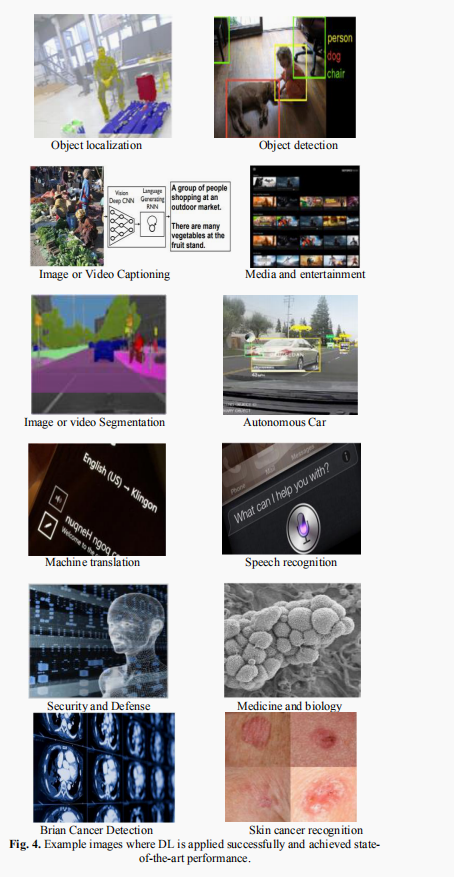
近年来,深度学习在各个应用领域都取得了巨大的成功。这一新的机器学习领域发展迅速,已经应用到大多数传统的应用领域,以及一些提供更多机会的新领域。基于不同的学习类别,提出了不同的学习方法,包括监督学习、半监督学习和非监督学习。当与传统的机器学习方法在图像理、计算机视觉、语音识别、机器翻译、艺术、医学成像、医疗信息处理、机器人控制、生物信息学、自然语言处理(NLP),网络安全等相比,实验结果表明了使用深度学习最先进的性能。
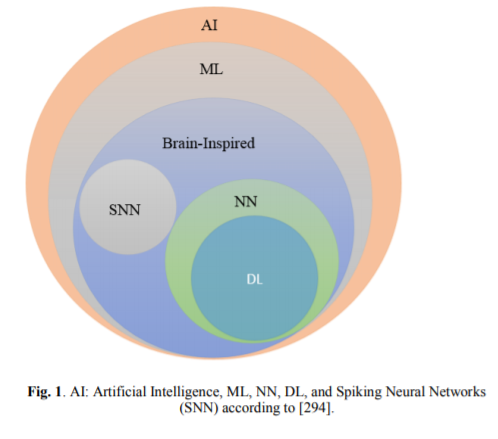
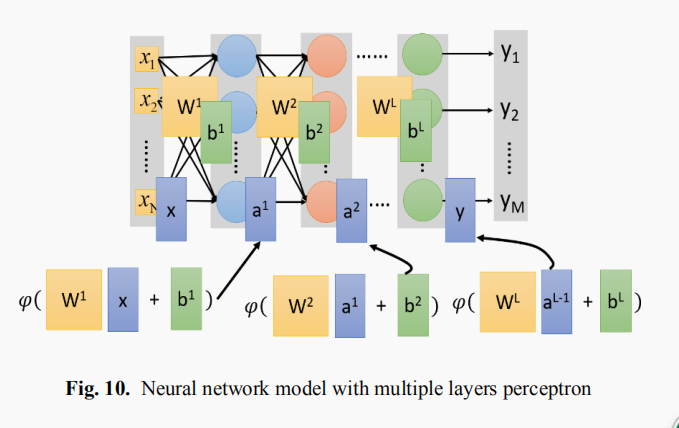
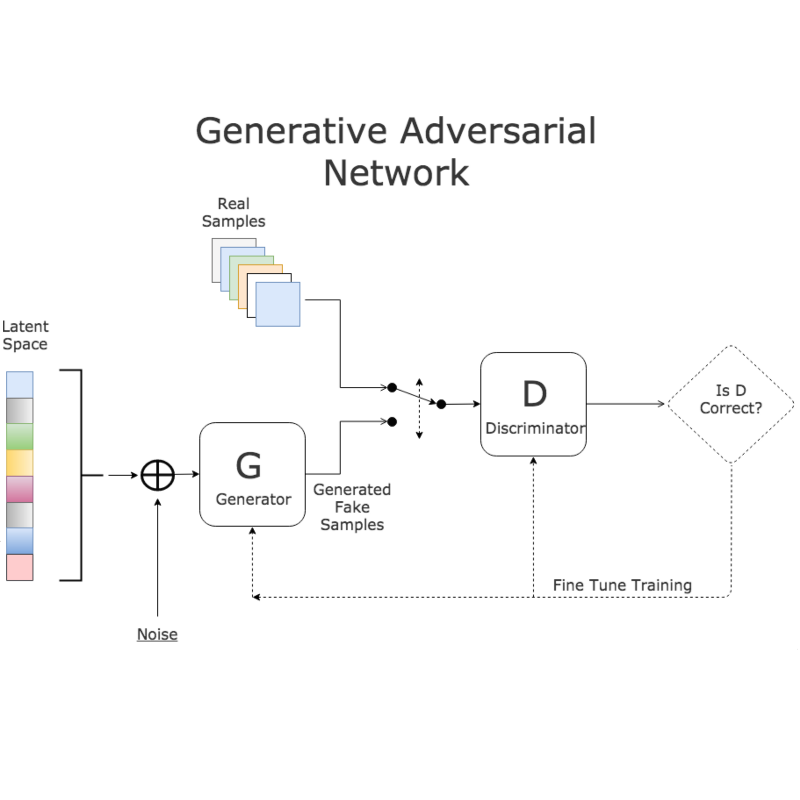
本报告从深度神经网络(DNN)开始,简要介绍了DL领域的研究进展。调查涵盖了卷积神经网络(CNN)、递归神经网络(RNN),包括长短时记忆(LSTM)和门控递归单元(GRU)、自动编码器(AE)、深度信念网络(DBN)、生成对抗网络(GAN)和深度强化学习(DRL)。此外,我们还介绍了最新的发展,例如基于这些DL方法的高级DL变体技术。本研究考虑了2012年以后发表的关于深度学习历史开始的大部分论文。此外,在不同的应用领域中探索和评估过的DL方法也包括在本次调查中。我们还包括最近开发的用于实现和评估深度学习方法的框架、sdk和基准数据集。有一些关于使用神经网络进行深度学习的调查和关于RL的调查已经发表。然而,这些论文并没有讨论用于训练大规模深度学习模型的个别先进技术和最近发展起来的生成模型方法。
作者简介:
Md Zahangir Alom博士是美国俄亥俄州代顿大学的研究工程师。他分别于2008年和2012年获得了孟加拉国拉杰沙伊大学(University of Rajshahi)和韩国全北国立大学(Chonbuk National University)的计算机工程学士和硕士学位。2018年,他获得了戴顿大学电子和计算机工程博士学位。他的研究兴趣包括机器学习、深度学习、医学成像和计算病理学。他是IEEE学生会员,国际神经网络协会(INNS)会员,美国数字病理学协会(DPA)会员。
Tarek M. Taha博士是代顿大学(University of Dayton)电子和计算机工程教授。他的研究兴趣是神经形态计算和高性能计算。Tarek M. Taha博士是美国国家科学基金会职业奖的获得者。