语义分割和转置卷积

雷锋网按:本文为雷锋字幕组编译的技术博客,原标题 Semantic Segmentation and Transposed Convolution,作者为 Ujjwal Saxena。
翻译 | 赵朋飞 程思婕 整理 | 凡江
插播一则小广告:NLP领域的C位课程,斯坦福CS224n正在AI慕课学院持续更新中,无限次免费观看!

使用 FCN8 识别可移动区域
分割对图像分析是必不可少的。语义分割描述了每个像素与类别标记的关联过程,(例如:花朵、人物、道路、天空、海洋、或者汽车)。
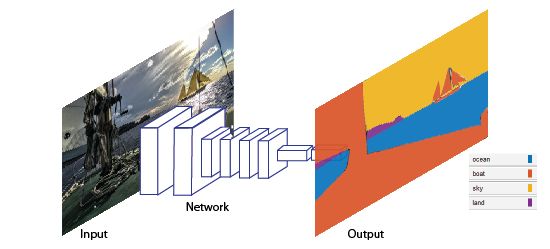
图像来源:Mathworks
众多语义分割方法中,很多领域都有很大的潜力。这些领域包括自主驾驶、工业锅炉检验、热图等,卫星图中的地形划分,医学影像分析。基于个人兴趣,我也做了从叶子中检测植物疾病的研究。包括将纹理或叶片从实际疾病标记中分离出来。这也促进了疾病检测过程的简化并提高了精度。
但语义分割到底是什么呢 ?
语义分割是指在像素层面去理解图像,即,我们想给图像中的每个像素分配一个对象类。例如,查看下面的图片。

输入图像
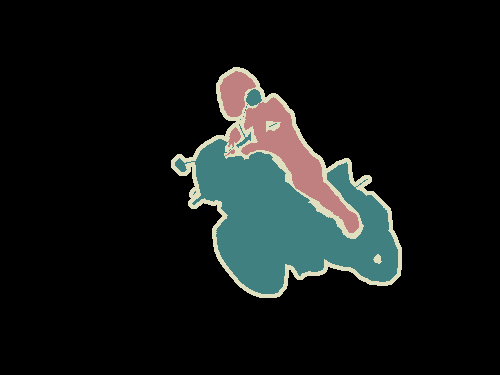
语义分割
在上面的图片中,只有 3 种类别,人、自行车和其他事物。FCN 可以被训练来识别道路、植物以及天空。VOC2012 和 MSCOCO 是语义分割领域最重要的数据集。
2014 年,来自伯克利的 Long 等人提出的全卷积网络 (FCN),促使 CNN 架构在没有全连接层的情况下在密集预测领域普遍应用。这使得分割图可以生成任何大小的图像,而且与之前使用的补丁分类方法相比,也要快得多。几乎所有后来的关于语义分割的顶级方法都采用了这种模式。
除了完全连接的层,使用 CNN 进行语义分割的另一个主要问题是池化层。池层增加了视图的范围,并且能够在丢弃「where」信息的同时聚合上下文。然而,语义分割需要精确的类别分布信息,因此,需要保留空间信息。在文献中有两种不同的体系结构来解决这个问题。
第一种是编码器-解码器架构。编码器使用池化层逐渐减少空间维度,解码器逐步恢复对象细节和空间维度信息。通常在编码器和解码器之间有快捷连接,用于更好地帮助解码器恢复对象细节。
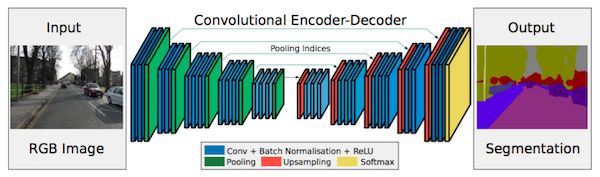
第二种方法没有在这里讨论。
当我在研究转置卷积中填充差异的时候,我发现关于一些关于 SAME 和 VALID 填充的很有趣的事情。需要理解的最重要的事情是,在 Valid 填充时,滤波器 Kernel 的大小不会超出输入图像的尺寸,对于卷积和转置卷积都是如此。类似,Same 填充核可以超出图像维度。
让我们更多的讨论下 Valid 填充。当增加 kernel 步长时,输入图像会在像素之间填充。如果步长是 2,会在现有行列之间再分别增加一行和一列。如果步长是 1,不会做任何填充。

Stride:1, kernel:3x3
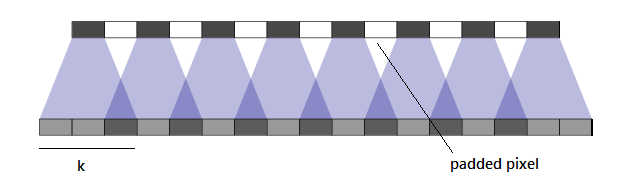
Stride:2, kernel:3x3
保持 k 不变,增加步长减少重叠。这种重叠指的是由相邻的内核行为计算的公共区域。让我们想象一下相反的效果。
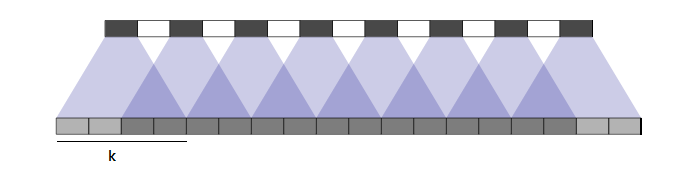
Stride:2, kernel:4x4
因此,填充的输入图像取决于步长:
Ip_d= (I-1)*s
s=步长,I= 输入维度,Ip_d 填充输入维度
输出图像维度取决于填充输入图像维度和核大小,如下:
O_d= Ip_d+ k;
O_d= (I-1)*s+k; k 是核大小
这个方程是正确的,无论核大小是大于或小于步长的,都可以在这里进行验证。然而,我的同事 Keshav Aggarwal 在玩 tensorflow 的一些代码时,得到了一个更好的等式。如下:
O_d = I * s+ max(k — s, 0);所有变量和上面的公式相同
我建议你稍微玩一下代码。
Same Padding 很简单但相当神秘。Same padding 通常在图像边界之外填充空的行和列。在正常的卷积过程中,即使填充是相同的,Kernel 可以用上面提到的步长扫描完整图像,实际上也不会在输入图像上填充任何东西。然而,如果由于 Kernel 大小和步长值而漏掉一些行或列,则添加一些额外的列和行来覆盖整个图像。
这不是转置卷积的情况。输出图像维度不依赖于过滤器的内核大小,而是根据步长的倍数增加。
O_d= I_d*s;
s=步长,I_d= 输入维度,O_d 填充输入维度
在这个案例中,输出维度由系统预先计算,然后图像在应用过滤器来维护输出维度之前,在外部被填充,去卷积之后,维度结果和计算的一样。优先考虑给图像增加列,图像两侧增加的列要一致。如果不一致,那么额外的列就会被添加到图像右侧。
那么如何采用这些滤波器对图像进行上采样呢?
这很简单,因为现在我们有了方程。假设我们想把图像放大到原来的两倍。
对 Same 填充来说,你可以设置 Kernel 任何合适的值,并且步长设置为 2。
对 Valid 填充,你可以将 Kernel 和步长都设置为 2。
然而,这些滤波器的性能是一个实验领域。我发现这里的 Same padding 比 Valid padding 更优秀。设置 kernel 值为一个偶数值不是好的实践,但是如果你想使用 Valid padding 将图片放大 2 倍,似乎没有别的办法。
你访问我的 Github 查看一些做过的项目,如果需要查看我更多的文章可以访问我的 medium 账号或 Wordpress。
原文链接:https://hackernoon.com/semantic-segmentation-and-transposed-convolution-4b1dd964a14b



