【论文推荐】最新八篇主题模型相关论文—在线光谱学习、PAM变分推断、章节推荐、多芯片系统、文本分析、动态主题模型
【导读】专知内容组整理了最近八篇主题模型(Topic Model)相关文章,为大家进行介绍,欢迎查看!
1. Lessons from the Bible on Modern Topics: Low-Resource Multilingual Topic Model Evaluation(Lessons from the Bible on Modern Topics: 低资源、多语种主题模型评估)
作者:Shudong Hao,Jordan Boyd-Graber,Michael J. Paul
机构:University of Maryland,University of Colorado
摘要:Multilingual topic models enable document analysis across languages through coherent multilingual summaries of the data. However, there is no standard and effective metric to evaluate the quality of multilingual topics. We introduce a new intrinsic evaluation of multilingual topic models that correlates well with human judgments of multilingual topic coherence as well as performance in downstream applications. Importantly, we also study evaluation for low-resource languages. Because standard metrics fail to accurately measure topic quality when robust external resources are unavailable, we propose an adaptation model that improves the accuracy and reliability of these metrics in low-resource settings.

期刊:arXiv, 2018年4月27日
网址:
http://www.zhuanzhi.ai/document/bc6c8157cf1d640a8aa1384279606daf
2. SpectralLeader: Online Spectral Learning for Single Topic Models(SpectralLeader: 单主题模型的在线光谱学习)
作者:Tong Yu,Branislav Kveton,Zheng Wen,Hung Bui,Ole J. Mengshoel
机构:Carnegie Mellon University
摘要:We study the problem of learning a latent variable model from a stream of data. Latent variable models are popular in practice because they can explain observed data in terms of unobserved concepts. These models have been traditionally studied in the offline setting. In the online setting, on the other hand, the online EM is arguably the most popular algorithm for learning latent variable models. Although the online EM is computationally efficient, it typically converges to a local optimum. In this work, we develop a new online learning algorithm for latent variable models, which we call SpectralLeader. SpectralLeader always converges to the global optimum, and we derive a sublinear upper bound on its $n$-step regret in the bag-of-words model. In both synthetic and real-world experiments, we show that SpectralLeader performs similarly to or better than the online EM with tuned hyper-parameters.

期刊:arXiv, 2018年4月26日
网址:
http://www.zhuanzhi.ai/document/3a00e2c9011ee692f4dc5559c6e0dcfd
3. Variational Inference In Pachinko Allocation Machines(Pachinko分配机的变分推断)
作者:Akash Srivastava,Charles Sutton
机构:University of Edinburgh
摘要:The Pachinko Allocation Machine (PAM) is a deep topic model that allows representing rich correlation structures among topics by a directed acyclic graph over topics. Because of the flexibility of the model, however, approximate inference is very difficult. Perhaps for this reason, only a small number of potential PAM architectures have been explored in the literature. In this paper we present an efficient and flexible amortized variational inference method for PAM, using a deep inference network to parameterize the approximate posterior distribution in a manner similar to the variational autoencoder. Our inference method produces more coherent topics than state-of-art inference methods for PAM while being an order of magnitude faster, which allows exploration of a wider range of PAM architectures than have previously been studied.
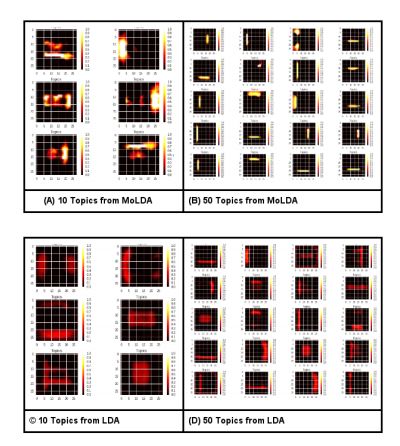
期刊:arXiv, 2018年4月21日
网址:
http://www.zhuanzhi.ai/document/2c0d17e2b6fbb222db623f94a66c8a48
4. Structuring Wikipedia Articles with Section Recommendations(基于维基百科文章的章节推荐)
作者:Tiziano Piccardi,Michele Catasta,Leila Zia,Robert West
机构:Stanford University
摘要:Sections are the building blocks of Wikipedia articles. They enhance readability and can be used as a structured entry point for creating and expanding articles. Structuring a new or already existing Wikipedia article with sections is a hard task for humans, especially for newcomers or less experienced editors, as it requires significant knowledge about how a well-written article looks for each possible topic. Inspired by this need, the present paper defines the problem of section recommendation for Wikipedia articles and proposes several approaches for tackling it. Our systems can help editors by recommending what sections to add to already existing or newly created Wikipedia articles. Our basic paradigm is to generate recommendations by sourcing sections from articles that are similar to the input article. We explore several ways of defining similarity for this purpose (based on topic modeling, collaborative filtering, and Wikipedia's category system). We use both automatic and human evaluation approaches for assessing the performance of our recommendation system, concluding that the category--based approach works best, achieving precision and recall at 10 of about 80\% in the crowdsourcing evaluation.
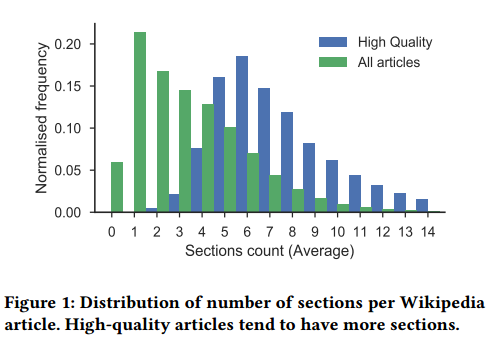
期刊:arXiv, 2018年4月17日
网址:
http://www.zhuanzhi.ai/document/e3ffa96ad1c10c337f747573d295f27c
5. Towards Training Probabilistic Topic Models on Neuromorphic Multi-chip Systems(神经形态多芯片系统概率主题模型的训练)
作者:Zihao Xiao,Jianfei Chen,Jun Zhu
机构:Tsinghua University
摘要:Probabilistic topic models are popular unsupervised learning methods, including probabilistic latent semantic indexing (pLSI) and latent Dirichlet allocation (LDA). By now, their training is implemented on general purpose computers (GPCs), which are flexible in programming but energy-consuming. Towards low-energy implementations, this paper investigates their training on an emerging hardware technology called the neuromorphic multi-chip systems (NMSs). NMSs are very effective for a family of algorithms called spiking neural networks (SNNs). We present three SNNs to train topic models. The first SNN is a batch algorithm combining the conventional collapsed Gibbs sampling (CGS) algorithm and an inference SNN to train LDA. The other two SNNs are online algorithms targeting at both energy- and storage-limited environments. The two online algorithms are equivalent with training LDA by using maximum-a-posterior estimation and maximizing the semi-collapsed likelihood, respectively. They use novel, tailored ordinary differential equations for stochastic optimization. We simulate the new algorithms and show that they are comparable with the GPC algorithms, while being suitable for NMS implementation. We also propose an extension to train pLSI and a method to prune the network to obey the limited fan-in of some NMSs.
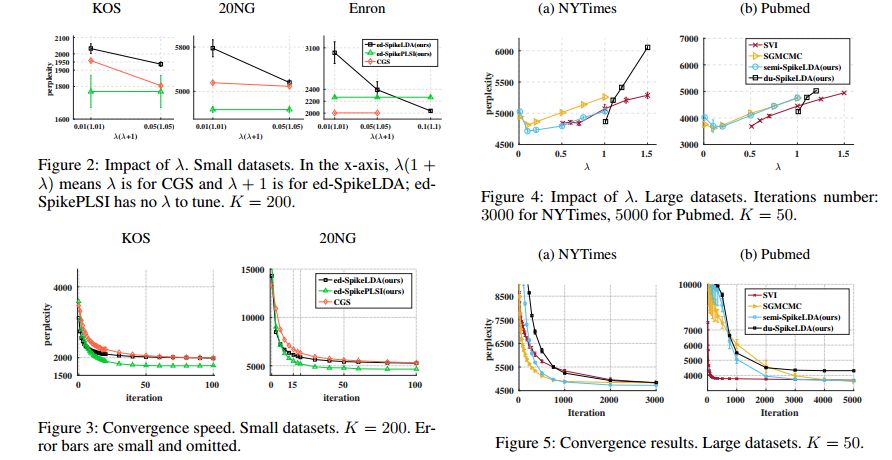
期刊:arXiv, 2018年4月10日
网址:
http://www.zhuanzhi.ai/document/66cb59e7b54301b90579484638cfa05f
6. Topic Modelling of Everyday Sexism Project Entries(日常性别歧视条目的主题建模)
作者:Sophie Melville,Kathryn Eccles,Taha Yasseri
机构:University of Oxford
摘要:The Everyday Sexism Project documents everyday examples of sexism reported by volunteer contributors from all around the world. It collected 100,000 entries in 13+ languages within the first 3 years of its existence. The content of reports in various languages submitted to Everyday Sexism is a valuable source of crowdsourced information with great potential for feminist and gender studies. In this paper, we take a computational approach to analyze the content of reports. We use topic-modelling techniques to extract emerging topics and concepts from the reports, and to map the semantic relations between those topics. The resulting picture closely resembles and adds to that arrived at through qualitative analysis, showing that this form of topic modeling could be useful for sifting through datasets that had not previously been subject to any analysis. More precisely, we come up with a map of topics for two different resolutions of our topic model and discuss the connection between the identified topics. In the low resolution picture, for instance, we found Public space/Street, Online, Work related/Office, Transport, School, Media harassment, and Domestic abuse. Among these, the strongest connection is between Public space/Street harassment and Domestic abuse and sexism in personal relationships.The strength of the relationships between topics illustrates the fluid and ubiquitous nature of sexism, with no single experience being unrelated to another.
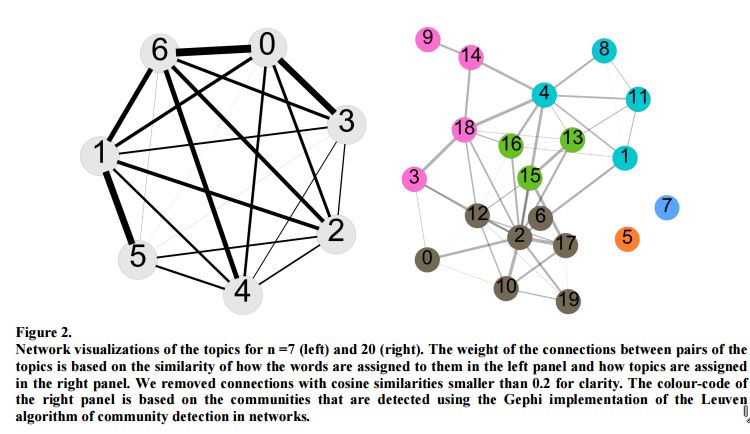
期刊:arXiv, 2018年4月5日
网址:
http://www.zhuanzhi.ai/document/9b067063786d9fb0aedcc922d074c1fa
7. Computer-Assisted Text Analysis for Social Science: Topic Models and Beyond(计算机辅助文本分析:主题模型及其他)
作者:Ryan Wesslen
机构:University of North Carolina at Charlotte
摘要:Topic models are a family of statistical-based algorithms to summarize, explore and index large collections of text documents. After a decade of research led by computer scientists, topic models have spread to social science as a new generation of data-driven social scientists have searched for tools to explore large collections of unstructured text. Recently, social scientists have contributed to topic model literature with developments in causal inference and tools for handling the problem of multi-modality. In this paper, I provide a literature review on the evolution of topic modeling including extensions for document covariates, methods for evaluation and interpretation, and advances in interactive visualizations along with each aspect's relevance and application for social science research.
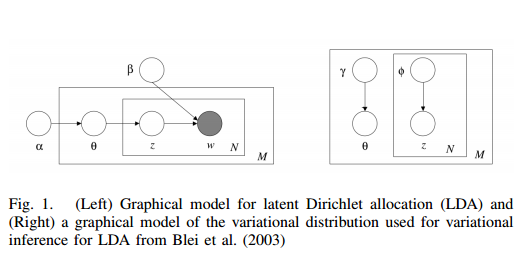
期刊:arXiv, 2018年3月29日
网址:
http://www.zhuanzhi.ai/document/6c771e3b7d2271e1840997f96d19d3ff
8. Scalable Generalized Dynamic Topic Models(可扩展的广义动态主题模型)
作者:Patrick Jähnichen,Florian Wenzel,Marius Kloft,Stephan Mandt
摘要:Dynamic topic models (DTMs) model the evolution of prevalent themes in literature, online media, and other forms of text over time. DTMs assume that word co-occurrence statistics change continuously and therefore impose continuous stochastic process priors on their model parameters. These dynamical priors make inference much harder than in regular topic models, and also limit scalability. In this paper, we present several new results around DTMs. First, we extend the class of tractable priors from Wiener processes to the generic class of Gaussian processes (GPs). This allows us to explore topics that develop smoothly over time, that have a long-term memory or are temporally concentrated (for event detection). Second, we show how to perform scalable approximate inference in these models based on ideas around stochastic variational inference and sparse Gaussian processes. This way we can train a rich family of DTMs to massive data. Our experiments on several large-scale datasets show that our generalized model allows us to find interesting patterns that were not accessible by previous approaches.
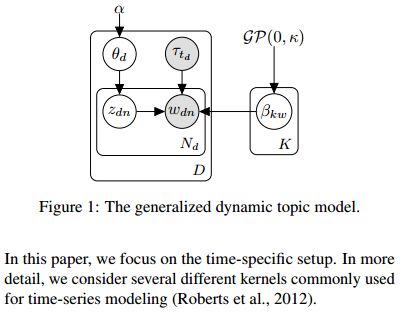
期刊:arXiv, 2018年3月21日
网址:
http://www.zhuanzhi.ai/document/b0d86c66d398e7a43f7a4b445251e1ae
-END-
专 · 知
人工智能领域主题知识资料查看与加入专知人工智能服务群:
【专知AI服务计划】专知AI知识技术服务会员群加入与人工智能领域26个主题知识资料全集获取

点击上面图片加入会员
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请扫一扫如下二维码关注我们的公众号,获取人工智能的专业知识!

点击“阅读原文”,使用专知





