视觉推理任务中的ImageNet:斯坦福GQA数据集重磅发布
【导读】近日,斯坦福NLP研究组发布了最新整理视觉问答数据集——GQA,以推动真实场景下的视觉-语言理解的研究进程,其中包括问答、图片、语义信息等内容,并且本数据集将被应用于2019年的VQA track中。
介绍:
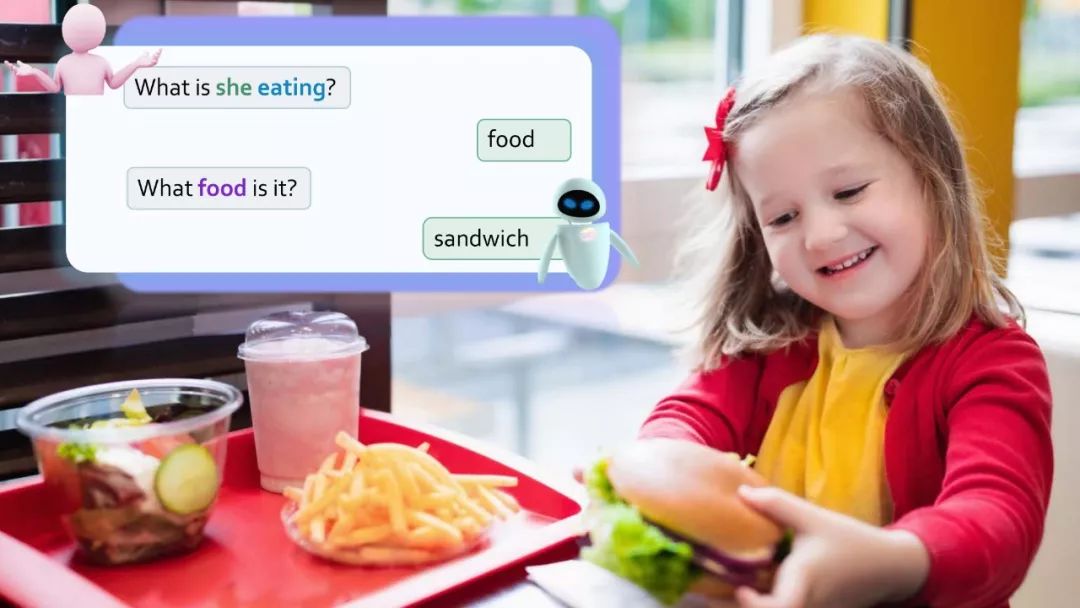
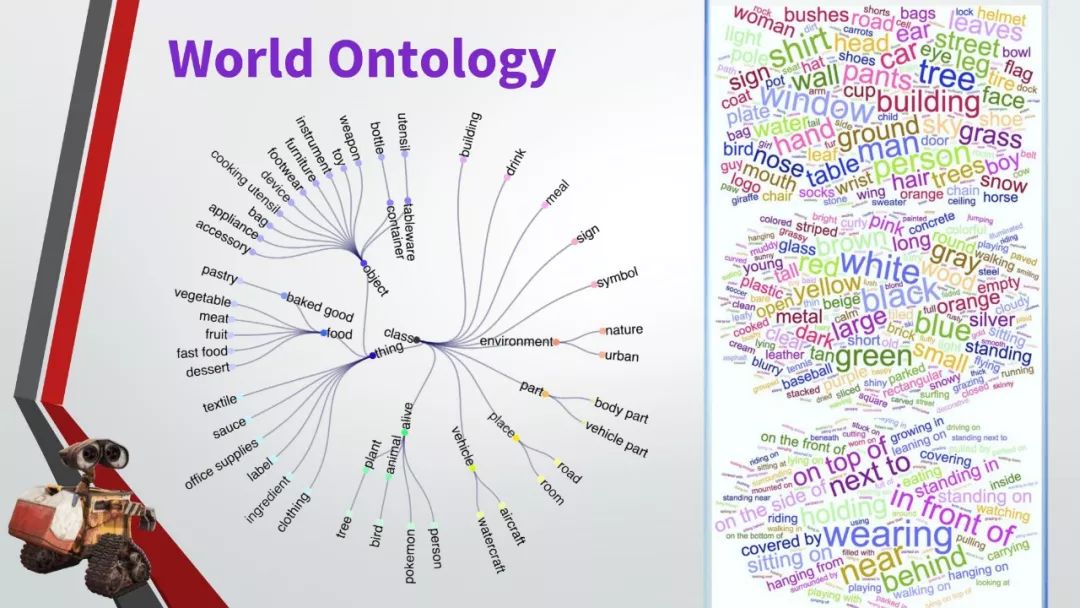
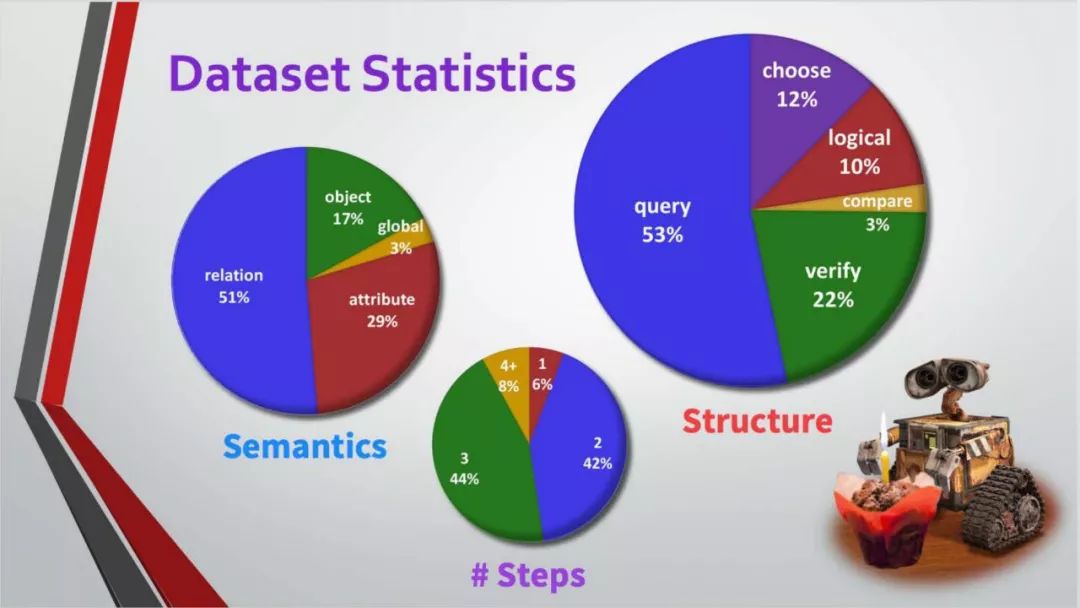
GQA——关于图像场景下的问答数据集。这是一个新的数据集,将被用于对现实世界中的图像进行视觉推理与组合回答的任务中。该数据集中包括了有关各种日常图像的近2000万条问题。每个图像都与一组场景图(scene graph)对应。每个问题都与其语义的结构化表示相关联在一起,并且约束应答者必须采用特定的推理步骤来回答它。
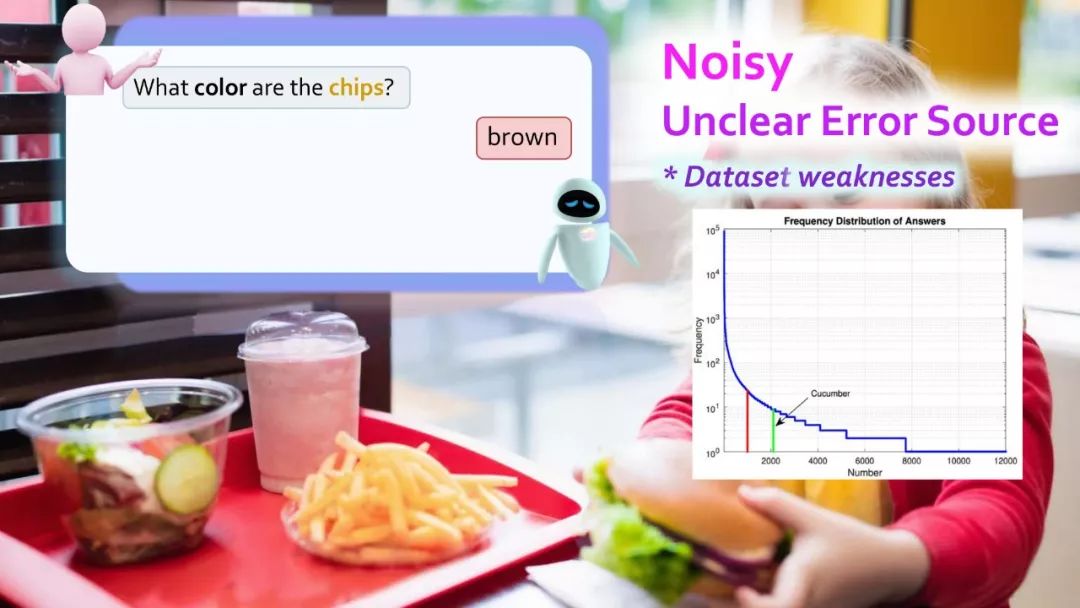
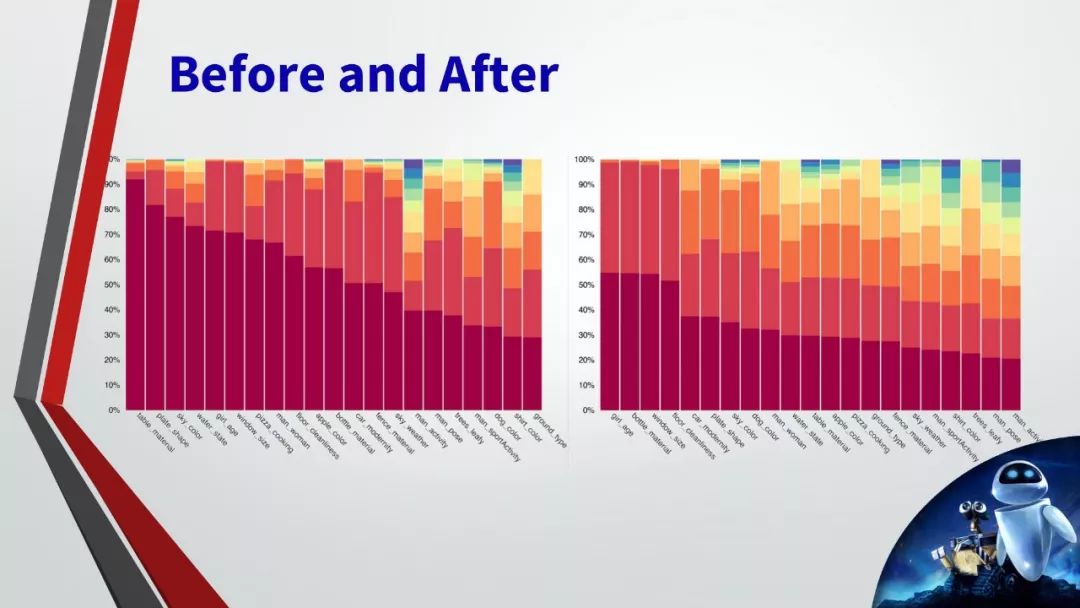
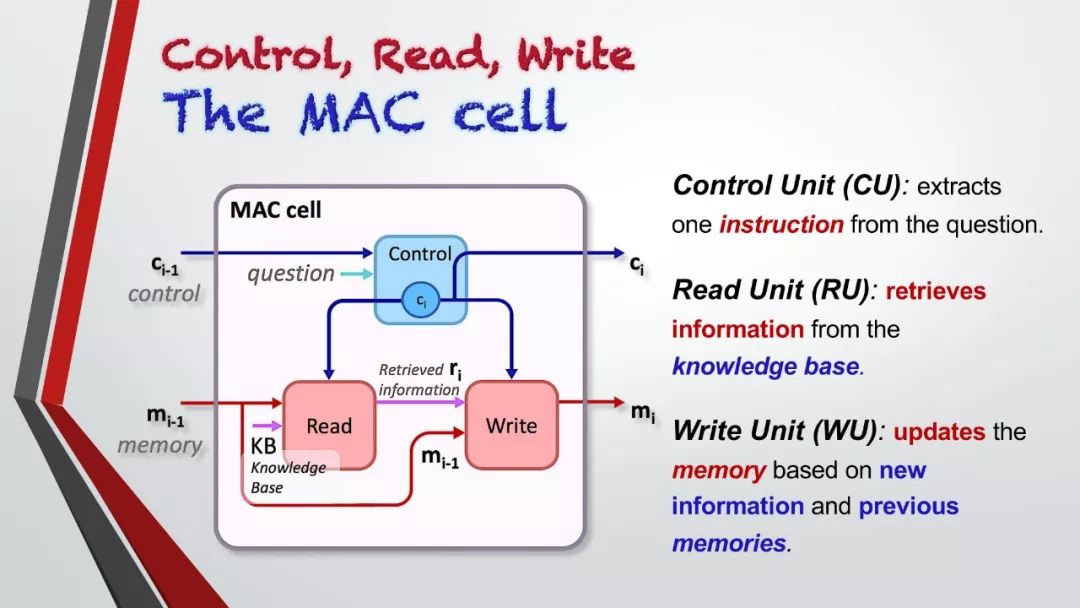
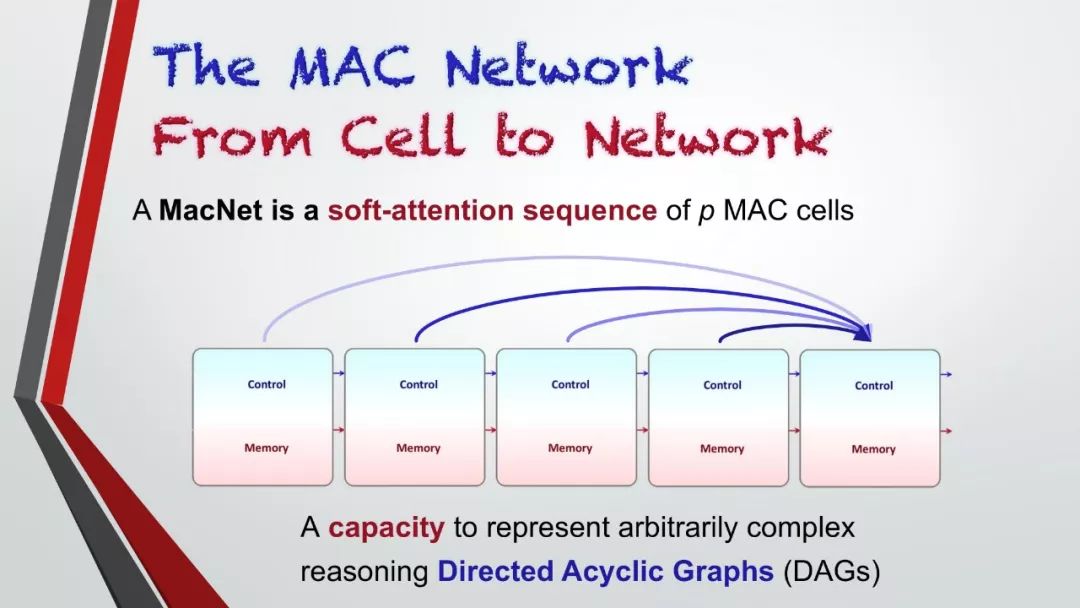
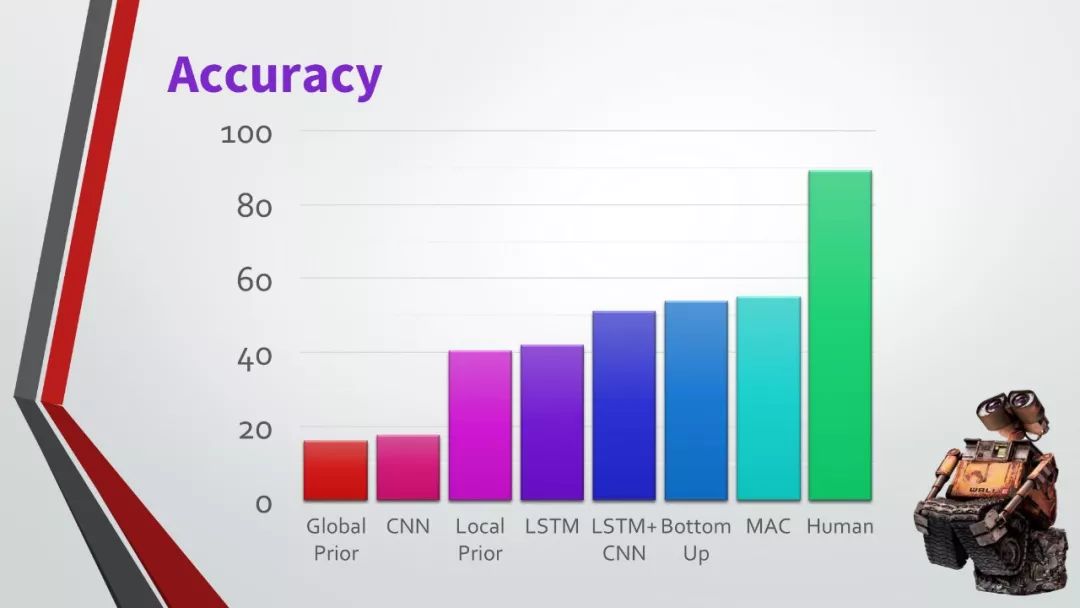
许多GQA的问题中涉及到了多种的推理技巧,空间理解和多步推理等,因此,通常比社区中使用的视觉问答数据集更有挑战性。在本次的收集过程中,我们还确保了数据集的平衡性,严格控制不同问题组的答案分布,以防止使用语言和先验信息进行猜测。
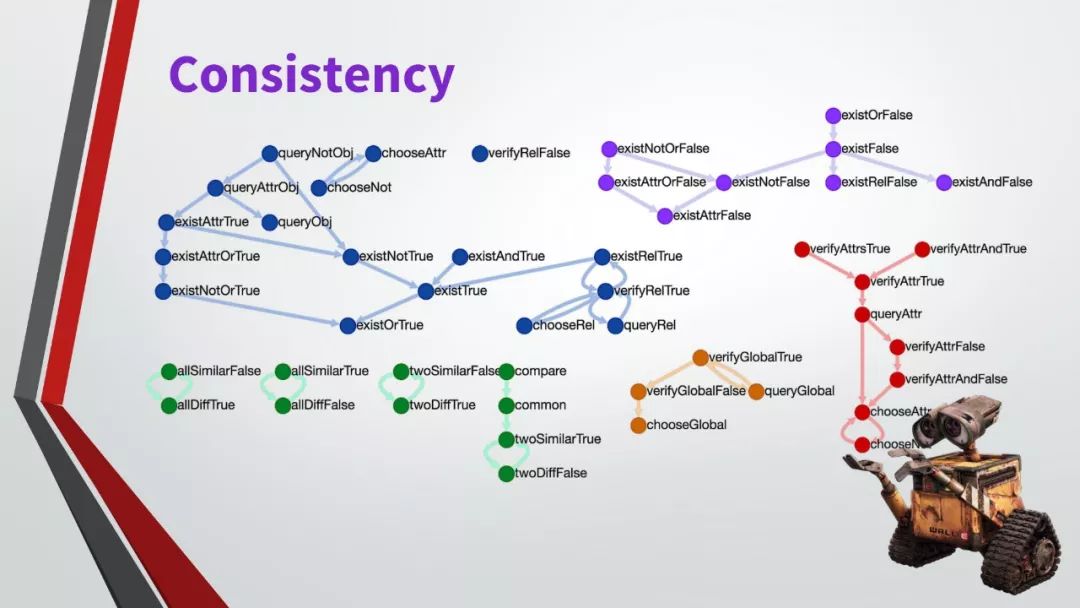
最后,我们采用了一套新的指标来补充数据集,不仅可以测试模型响应的准确性,还可以测试模型的一致性、有效性和合理性,从而更加了解其行为。虽然问题是自动生成的,但他们基于自然语言的众包场景图,使得问题具有语法性、多样性和惯用性。
为鼓励人们尝试使用GQA数据集,我们将从2019年2月开始举办比赛,期望GQA能够成为更强大、更有说服力的推理模型的研究基石,并助力于推进场景理解和视觉问答的领域。
【论文完整版下载】
请关注专知公众号(点击上方蓝色专知关注)
后台回复“GQASTF”就可以获取数据集介绍完整版的下载链接~
专知2019年《深度学习:算法到实战》精品课程,欢迎扫码报名学习!

原文链接:
https://cs.stanford.edu/people/dorarad/gqa/index.html
附数据集介绍PDF:


















































-END-
专 · 知
专知《深度学习:算法到实战》课程全部完成!460+位同学在学习,现在报名,限时优惠!网易云课堂人工智能畅销榜首位!
请加专知小助手微信(扫一扫如下二维码添加),咨询《深度学习:算法到实战》参团限时优惠报名~

欢迎微信扫一扫加入专知人工智能知识星球群,获取专业知识教程视频资料和与专家交流咨询!

请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

点击“阅读原文”,了解报名专知《深度学习:算法到实战》课程



