【深度】如何「看图说话」?Facebook提出全新的基于图像实体的「图像字幕」框架

原文:arXiv
作者:Jiasen Lu、Jianwei Yang、Dhruv Batra、Devi Parikh、Georgia Institute of Technology、Facebook AI Research
来源:雷克世界
导语:一直以来,图像字幕都是计算机视觉和自然语言处理中一个非常具有挑战性的问题,而在本文中,针对这一问题,Facebook提出了一种全新的称之为Neural Baby Talk的图像字幕框架。它能够生成基于目标检测器所发现的实体的自然语言。
在本文中,我们介绍了一种新型图像字幕(image captioning)框架,它可以为图像中目标检测器所发现的实体明确地建立自然语言。我们的方法将传统的槽形填充式字幕方法(通常在基于图像的情况下更好)与有现代的神经字幕方法(通常更自然纯正和精确)相协调。我们的方法首先生成一个句子“模板”,其中的槽位明确地与特定的图像区域绑定。然后这些插槽被目标探测器在该区域中识别的视觉概念所填充。整个架构(句子模板生成和目标检测器槽形填充)是端到端可微的。我们验证了所提出的模型自不同图像字幕任务上的有效性。在标准图像字幕和新型目标字幕上,我们的模型在COCO和Flickr30k数据集上达到了最先进的水平。我们还证明了,当场景组成的训练和测试分布与相关字幕的语言先验不同时,我们的模型具有独特优势的。代码可以点击链接获得。
可以这样说,图像字幕是一个非常具有挑战性的问题,它存在于计算机视觉和自然语言处理的交叉点上。它涉及这样一个问题:生成一个能够准确地对图像内容进行总结的自然语言句子。图像字幕也是迈向真实世界应用的重要的第一步,具有重要的实际影响,范围涉及帮助视力受损用户,到个人助理,再到人机交互。
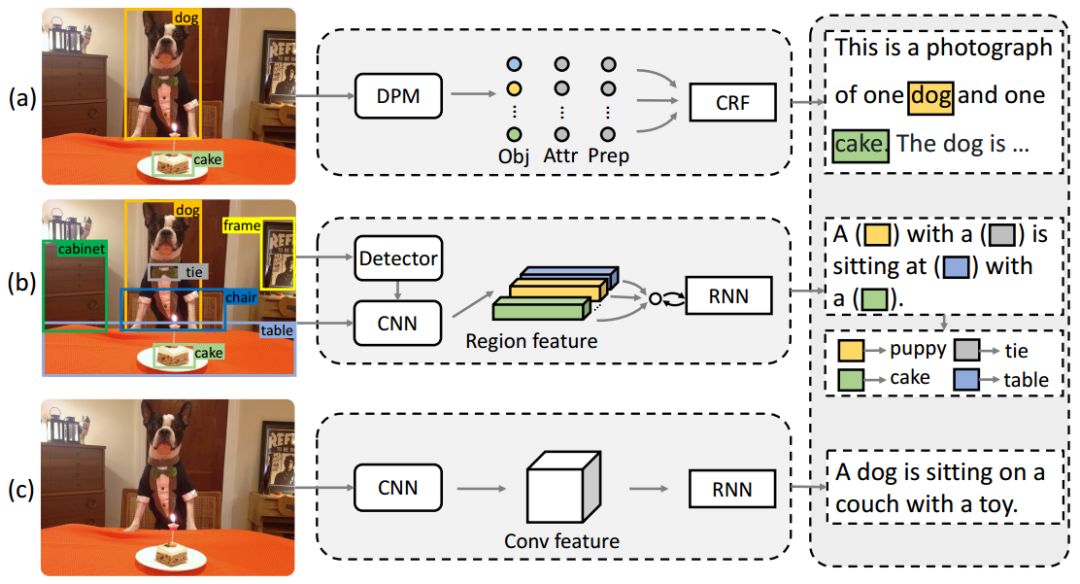
使用(a)Baby Talk、(c)神经图像字幕和(b)我们的Neural Baby Talk方法生成的样本标题。我们的方法生成带有插槽位置的句子“模板”,并与图像区域进行明确绑定(在图像中以相应的颜色进行绘制)。随后,这些插槽然后由目标检测器在区域中检测到的概念进行填充。
目前,最先进的图像字幕模型往往是单片神经模型(monolithic neural models),本质上是“编码器-解码器”范式。图像被编码成一个带有卷积神经网络(CNN)的向量,并且使用循环神经网络(RNN)对该向量进行解码为字幕,而整个系统以端到端的方式进行训练。虽然最近有很多的关于这个基本思想的拓展将注意力包含在内了,但人们很清楚,模型仍然缺乏视觉基础,即,不要将已命名的概念与图像中的像素相关联。他们往往倾向于“看”不同的区域,而人类的往往更倾向于从训练数据中复制字幕。
例如,在图1中,一个神经图像字幕方法将图像描述为“一只狗坐在一个带有玩具的沙发上”。这不太准确。但是,如果有人真的眯着眼睛观察这幅图,它可能(看起来)看起来就像这样一个场景,其中,狗可能坐在一个带有玩具的沙发上。在有玩具的沙发上发现狗是很平常的事情。先验的描述是合理的。而这正是现如今的神经字幕模型倾向于实现的——根据能够与场景的第一印象要点相匹配的语言模型,生成通用合理的字幕。虽然这可能对于普通场景来说足够好了,但鉴于我们的视觉世界的多样性,有很多这样的图像,它们不同于普通场景中的图像,而对于这样的图像来说仅使用这些模型是远远不够的。
如果我们退一步进行思考,我们是否真的需要语言模型来完成图像字幕的繁重工作?鉴于我们在目标识别中所取得的前所未有的进展(例如,目标检测、语义分割、实例分割、姿态估计),这似乎看起来,视觉管线肯定可以做得比仅仅依赖于场景的首要要点好得多。事实上,当今最先进的目标探测器可以成功检测图1(c)中所展示的图像中的桌子和蛋糕!标题应该谈论的是实际检测到的桌子和蛋糕,而不是语言模型所幻想的沙发和玩具,因为这样听起来似乎是合理的。

从左至右是使用相同模型,不同检测器生成的字幕:(1)无检测器(2)弱检测器,只检测到“人”和“三明治”(3)经COCO训练过的检测器(检测结果中显示了“泰迪熊”)(4)能够检测到新概念的检测器(字幕中首次出现了“Ted先生”和“派”),使用不同颜色表示视觉词汇与基础区域之间的对应关系。
有趣的是,在深度学习“革命”爆发之前,在图像字幕方面所做的某些初次尝试,主要依赖目标检测器和属性分类器的输出来对图像进行描述。例如,图1中Baby Talk的输出,它使用槽形填充方法,通过模板字幕来表示场景中所发现的所有目标和属性。虽然语言不够自然,但标题是完全建立在模型所观察到的图像的基础之上的。如今的方法落脚在另一个极端——虽然现代神经图像字幕方法生成的语言更加自然,但它却倾向于以更少的图像为基础。
在本文中,我们介绍了调和这些方法的Neural Baby Talk。它产生了基于目标检测器所发现的实体的自然语言。这是一种神经方法,它可以生成句子“模板”,其中槽的位置明确与图像区域相关联。然后,目标检测器利用在该区域中所找到的概念填充这些槽。而这一方法是以端到端的方式进行训练的,从而会产生自然的声音和基础字幕。
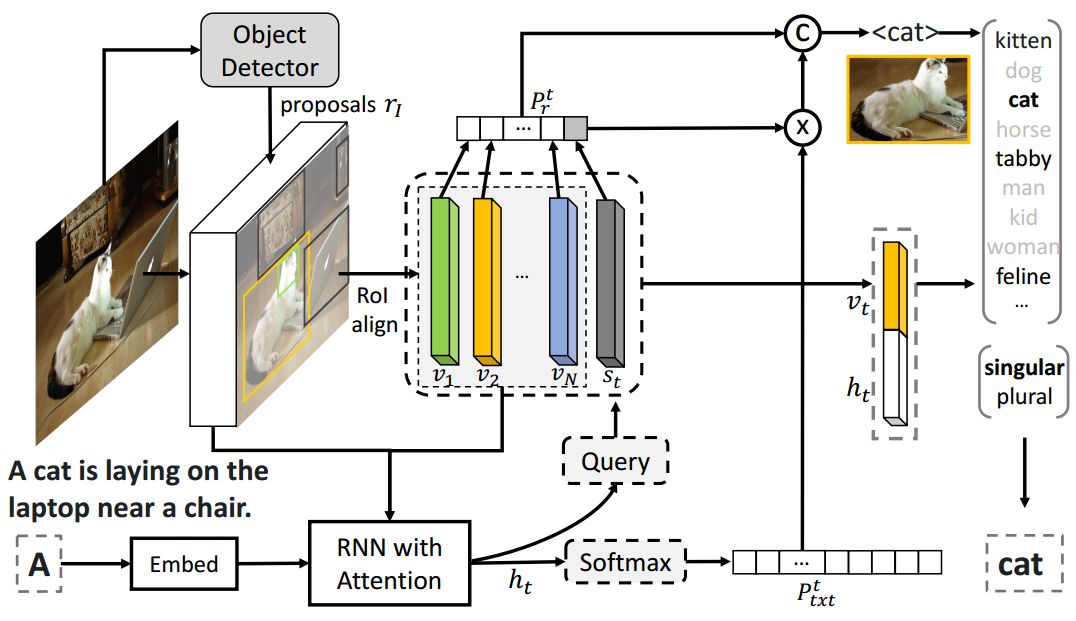
所提出方法的一个块,给定一幅图像,来自任何目标探测器和当前单词“A”的提议,该图显示了预测下一个视觉单词“cat”的过程。
我们的主要技术贡献是一种全新的用于基础图像字幕的新型神经解码器。具体而言,在每个时间步中,模型会决定是从文本词汇中生成一个单词还是生成一个“视觉”单词。视觉单词本质上是一个标记,它将为描述图像中特定区域的单词保留槽位。例如,对于图1中的图像而言,生成的序列可以是“A<region-17>坐在一个带有< region -3>的< region -123>上。”然后在第二阶段(例如,<region−17>→小狗<region−123>→桌子)对每个指示区域进行分类,并填入视觉单词(<region−[.]>’s),从而最终描述“小狗正坐在一张桌子上,身旁摆放着一个蛋糕”——基于图像的自由形式的自然语言描述。我们的模型具有一个很好的特征,那就是它可以轻松地插入不同的目标检测器。因此,我们可以使用不同的检测器后端为同一图像生成多种标题,就像图2所展示的那样。
在标准图像字幕任务上生成的字幕和相应的视觉基础区域
我们的贡献
•我们介绍了Neural Baby Talk——一种全新的以视觉为基础的图像字幕框架,它在生成自由形式的自然语言描述的同时,对图像中的目标进行了明确定位。
•我们的方法分为两个阶段,首先生成混合模板,该混合模板包含(文本)单词和与图像区域明确关联的槽位,然后通过识别相应图像区域中的内容,来填充带有(文本)单词的槽位。
•我们提出了一个具有鲁棒性的图像字幕任务,用于测试图像字幕算法的组合性,其中,模型在测试时,会以全新的组合方式遇到包含已知目标的图像(例如:模型在训练时看到了在沙发上的狗和桌子旁的人,但在测试时遇见了在桌子上的狗)。泛化到这种全新的组合中是展示图像基础的一种方式,而不是简单地利用来自训练数据的相关性。
•在标准图像字幕任务上,我们提出的方法在COCO和Flickr30k数据集上实现了最先进的性能表现,并且在具有鲁棒性图像字幕和新的目标字幕任务上的表现要明显优于现有方法。
在本文中,我们介绍了Neural Baby Talk,这是一种全新的图像字幕框架,它基于目标检测器在图像中发现的实体,从而产生明确的自然语言。我们采用一种两阶段方法,首先生成一个混合模板,其中包含来自文本词汇表的单词组合以及与图像区域相对应的槽位。然后,根据目标检测器在图像区域中识别的类别来填充槽位。通过对COCO数据集的序列和值分割进行重组,我们引入了一种具有鲁棒性的图像字幕分割方法。经过在一系列标准、具有鲁棒和全新的目标图像字幕任务上的实验结果,充分证实了我们所提出的方法的有效性。
原文链接:https://arxiv.org/pdf/1803.09845.pdf
☞【学界】OpenPV:中科院研究人员建立开源的平行视觉研究平台
☞【征稿通知】IEEE IV 2018“智能车辆中的平行视觉”研讨会
☞【学界】ParallelEye:面向交通视觉研究构建的大规模虚拟图像集
☞【CFP】Virtual Images for Visual Artificial Intelligence
☞【最详尽的GAN介绍】王飞跃等:生成式对抗网络 GAN 的研究进展与展望
☞【智能自动化学科前沿讲习班第1期】王飞跃教授:生成式对抗网络GAN的研究进展与展望
☞【智能自动化学科前沿讲习班第1期】王坤峰副研究员:GAN与平行视觉
☞【重磅】平行将成为一种常态:从SimGAN获得CVPR 2017最佳论文奖说起
☞【征稿】神经计算专刊Virtual Images for Visual Artificial Intelligence
☞【教程】 在Keras上实现GAN:构建消除图片模糊的应用
☞【前沿】 DeepMind提出SPIRAL:使用强化对抗学习,实现会用画笔的智能体
☞【深度】模拟世界的模型:谷歌大脑与Jürgen Schmidhuber提出「人工智能梦境」
☞【学界】华盛顿大学推出YOLOv3:检测速度快SSD和RetinaNet三倍(附实现)
☞【教程】先理解Mask R-CNN的工作原理,然后构建颜色填充器应用




