学界 | 如何让医学图像诊断网络具备可解释性?CVPR oral 作者张子钊详解 MDNet 技术细节
AI 科技评论按:AI 科技评论对各大顶级会议的论文及作者一直保持高度关注,在邀约优秀的与会老师和同学参加GAIR大讲堂等线下分享活动外,AI 科技评论也会持续邀请论文作者对自己的工作进行详细介绍。
本文为佛罗里达大学博士生张子钊接受AI 科技评论的独家约稿,对他在 CVPR 2017 的 oral 论文《MDNet: A Semantically and Visually Interpretable Medical Image Diagnosis Network》进行详细解读。
论文地址:https://arxiv.org/pdf/1707.02485.pdf
张子钊是佛罗里达四年级在读博士,导师是佛罗里达大学生物工程、计算机系和电子计算机工程系终身职位教授杨林。张子钊的近期研究包括如何利用多模态知识让基于人工智能的医学图像诊断方法具有可解释性,从而获得更好的临床实际应用价值。他的相关工作在 2017 年的 CVPR 和 MICCAI 大会上都获得 Oral 邀请。
近年来,越来越多的学者开始探索如何用人工智能深度学习方法提高计算机辅助医学图像诊断的能力。在多种病症的图像上,目前已经有一些工作利用大规模的数据证明,深度学习能够达到甚至超过医生的诊断水平。
但是在临床实践中,如果让机器真正有效辅助医生进行诊断,机器的输出应该需要能被医生理解。换句话说,机器应该以生成医生所能理解的自然语言的方式来表述它所看到的图像特征,从而推理得出最后的诊断(比如诊断报告)。而这个能力是现有的医学图像诊断方法所缺乏的。
另一方面,在很多类疾病的图像诊断中(尤其是病理学显微镜图像),医生之间的诊断一致性非常低。所以在临床中,一个医生通常需要获得补充性意见作为参考。这一点更加体现了机器诊断「可解释性」的重要性。
出于这个动机,本文提出了一个能够具有在语义上和视觉上为可解释性的医学图像诊断网络(MDNet)。给定一张医学图像,MDNet 能够自动生成完整的诊断报告同时在描述图像时显示图像关注区(attention)。
网络结构及技术细节
MDNet 的网络结构如图 1 所示。主要由三个子模块构成:图像模块用来生成图像的表达;语言模块接受图像表达输入来生成诊断报告;Attention 模块与语言模块配合生成逐字的图像关注区。
利用图像生成文字描述在计算机视觉中领域中叫做图像标注(Image captioning)。MDNet 在技术上和图像标注相似,但是 MDNet 针对一些医学图像特有问题会有一些特定的解决方案,使得 MDNet 在准确率上高于一般的图像标注方法(实验部分会说明)。在下文中,本文就三个模块一一进行介绍。
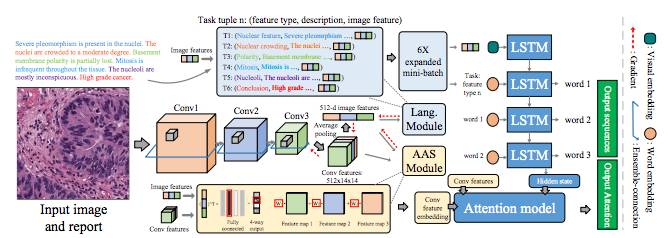
图 1: MDNet 网络结构。图像为膀胱显微镜图像的一个感兴趣区域和对应的诊断报告。
图像模块
医学图像中特征(比如显微镜图像中的细胞)通常表现在不同大小的区域内,所以一方面 CNN 需要多尺度(multi-scale)范围的描述。另一方面,由于医学图像数据集通常不够大,所以 CNN 应该具有高效的学习能力,即用尽量少的参数获得最佳准确率。考虑到这两点,我们改进了残差网络(ResNet)来提高它隐形的多尺度集成能力。根据对 ResNet 最后分类模块的数学分析(具体见原文),提出利用独立的权重来集成不同尺度特征图的思想。实现方法非常简单,只需对 ResNet 稍加改动。在对比试验中,利用 8M 的参数,在 CIFAR 10/100 上达到 4.43%/19.94% 的错误率。而比较的 ResNet,在更大的 10M 的参数量上是 4.92%/22.71%(更多的结果请参考原文)。
语言模块
语言模块主要由 LSTM 网络构成。不同于自然图像标注问题,医学图像并没有像 Inception 一样有带精细化标签数据集(ImageNet)以及训练好的 CNN 网络(最后的特征图融合了很多类的语义信息),所以如何利用 LSTM 从图像对应的诊断报告中提取这些关于图像的语义信息来帮助 CNN 理解图像的特征很重要。我们做了两个改进(见图 2):
因为医学诊断报告比较长并且表述了多个图像特征,我们将整个报告的拟合转化为多个特征描述句的并行拟合(用 Batch shuffle 在训练时完成),即让一个 LSTM 前馈只专注于一种特征描述。
为了让不同句子任务之间共享 LSTM 参数,MDNet 给 LSTM 设计了一个条件输入(第二个时间点),用来指定一个 Batch 中每个样本 LSTM 在输出什么类型的图像特征描述句。
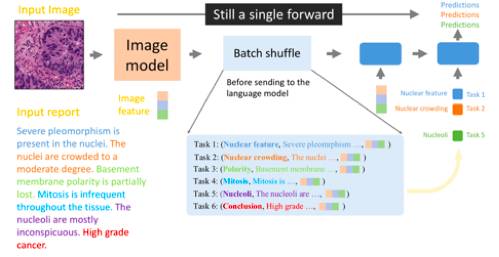
图 2:语言模块的两个改进。
Attention 模块
我们发现原始的 attention model(Xu et al, ICML 2015)得到的 attention 图大部分无法有效关注局部重要的图像区域。为了解决这个问题,我们引入 attention 增强模块(AAS)来辅助 attention 模块生成更佳有效的 attention 图。图 3 比较了结果。
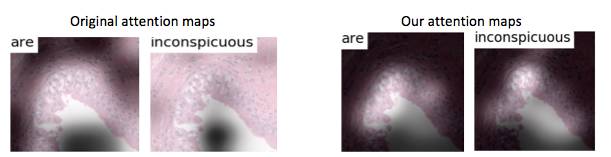
图 3: 我们的 attention 图更佳准确的关注到了感兴趣区域(泌尿道上皮区)。
网络训练
为了让语言中的语义信息能够更好的支持 CNN 的学习,MDNet 提出一种端对端的梯度适应策略。调整梯度的方法如下公式表示:
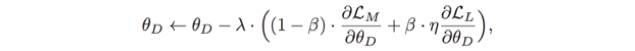
由两个权重参数 β 和 η 控制。β 在训练中动态变化。主要思想是动态平衡来自 LSTM 和 AAS 模块的梯度,从而更好的传播到 CNN 进行学习。
实验结果
这篇文章还改进并提出新的适合医学问题的分析度量标准。实验部分,文章做了 1)生成诊断报告的文字质量量化分析(表格 1),2)诊断准确率量化分析(表格 1),以及 3)用 MDNet 进行基于图像特征描述进行图像检索的试验(表格 2),和 attention 的定性分析。还有对比实验和算法讨论。算法用一个出名的自然图像标注的算法(NeuralTalk2)作为 baseline 进行比较试验。在大部分的评价标准上,MDNet 的结果有很大的提升。
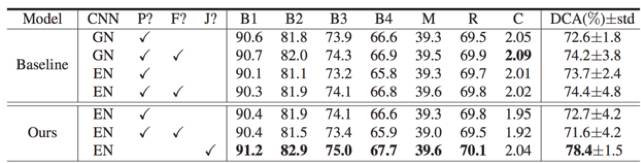
Table 1: 诊断报告文字质量结果。最后一行是 MDNet 完整方法。
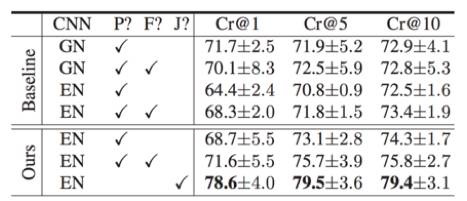
Table 2: 图像检索结果。最后一行是 MDNet 完整方法。
更多的结果和 demo 请参考:
原文:https://arxiv.org/pdf/1707.02485.pdf
项目主页:https://www.cise.ufl.edu/~zizhao/mdnet.html
————— 给爱学习的你的福利 —————
CCF-ADL81:从脑机接口到脑机融合
顶级学术阵容,50+学术大牛
入门类脑计算知识,了解类脑智能前沿资讯
课程链接:http://www.mooc.ai/course/114
或点击文末阅读原文

————————————————————






