干货|吴恩达 DeepLearning.ai 课程提炼笔记(1-3)神经网络和深度学习 --- 浅层神经网络
以下为在Coursera上吴恩达老师的DeepLearning.ai课程项目中,第一部分《神经网络和深度学习》第三周课程部分关键点的笔记。
笔记并不包含全部小视频课程的记录,如需学习笔记中舍弃的内容请至Coursera 或者 网易云课堂。同时在阅读以下笔记之前,强烈建议先学习吴恩达老师的视频课程。
简单神经网络示意图:
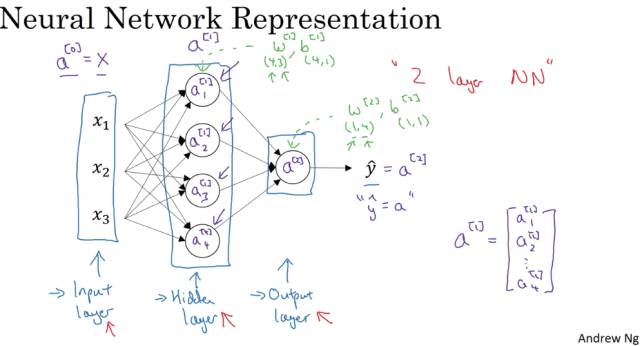
神经网络基本的结构和符号可以从上面的图中看出,这里不再复述。
主要需要注意的一点,是层与层之间参数矩阵的规格大小:


除输入层之外每层的计算输出可由下图总结出:
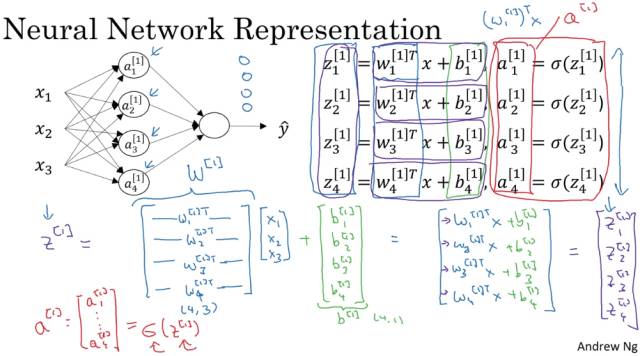
其中,每个结点都对应这两个部分的运算,z运算和a运算。 在编程中,我们使用向量化去计算神经网络的输出:
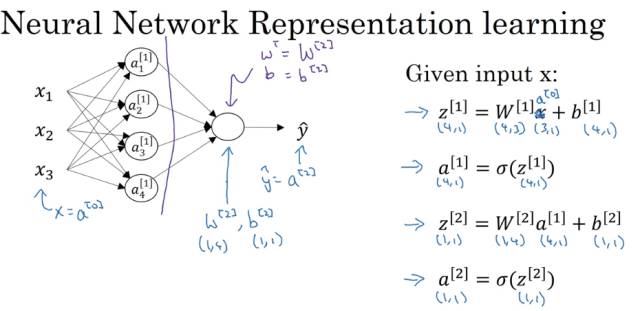
在对应图中的神经网络结构,我们只用Python代码去实现右边的四个公式即可实现神经网络的输出计算。
假定在m个训练样本的神经网络中,计算神经网络的输出,用向量化的方法去实现可以避免在程序中使用for循环,提高计算的速度。
下面是实现向量化的解释:
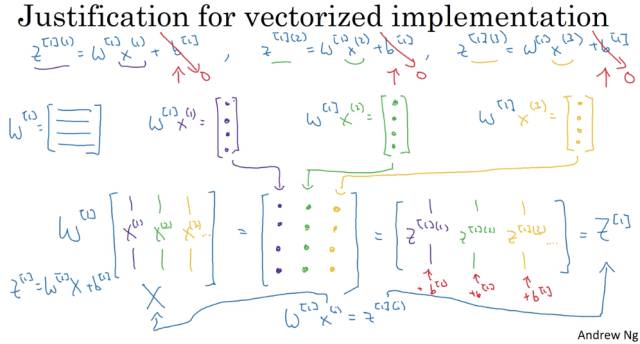

通过向量化,可以更加便捷快速地实现神经网络的计算。
几种不同的激活函数 g(x) :
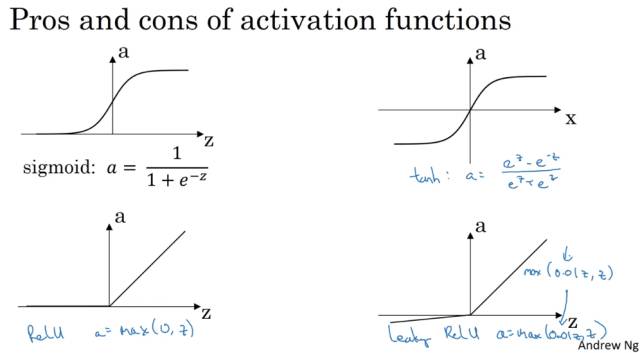

激活函数的选择:
sigmoid函数和tanh函数比较:

然而sigmoid和tanh函数在当 |z| 很大的时候,梯度会很小,在依据梯度的算法中,更新在后期会变得很慢。在实际应用中,要使 |z| 尽可能的落在0值附近。
ReLU弥补了前两者的缺陷,当 z>0 时,梯度始终为1,从而提高神经网络基于梯度算法的运算速度。然而当 z<0 时,梯度一直为0,但是实际的运用中,该缺陷的影响不是很大。
Leaky ReLU保证在 z<0 的时候,梯度仍然不为0。
在选择激活函数的时候,如果在不知道该选什么的时候就选择ReLU,当然也没有固定答案,要依据实际问题在交叉验证集合中进行验证分析。
转自:机器学习算法与自然语言处理
完整内容请点击“阅读原文”




