EasyNLP中文文图生成模型带你秒变艺术家

导读

多模态数据(文本、图像、声音)是人类认识、理解和表达世间万物的重要载体。近年来,多模态数据的爆炸性增长促进了内容互联网的繁荣,也带来了大量多模态内容理解和生成的需求。与常见的跨模态理解任务不同,文到图的生成任务是流行的跨模态生成任务,旨在生成与给定文本对应的图像。这一文图生成的任务,极大地释放了AI的想象力,也激发了人类的创意。典型的模型例如OpenAI开发的DALL-E和DALL-E2。近期,业界也训练出了更大、更新的文图生成模型,例如Google提出的Parti和Imagen。
文图生成模型简述
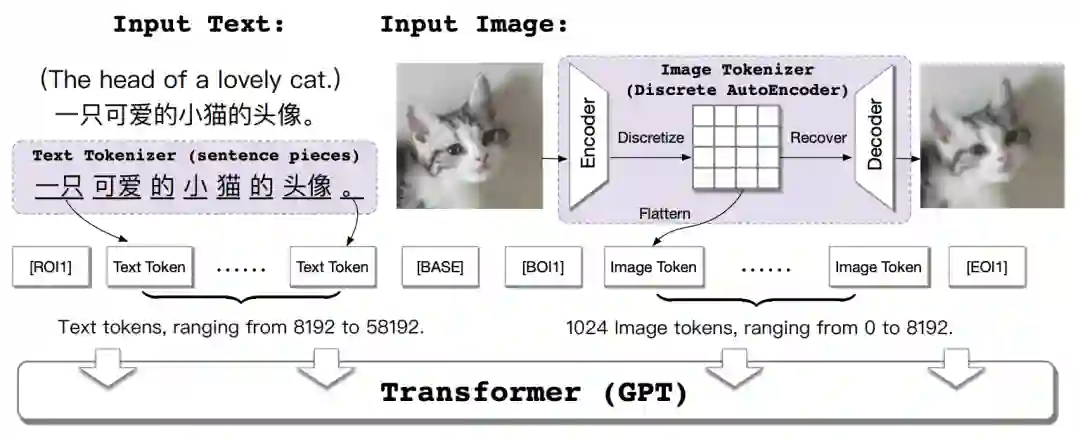
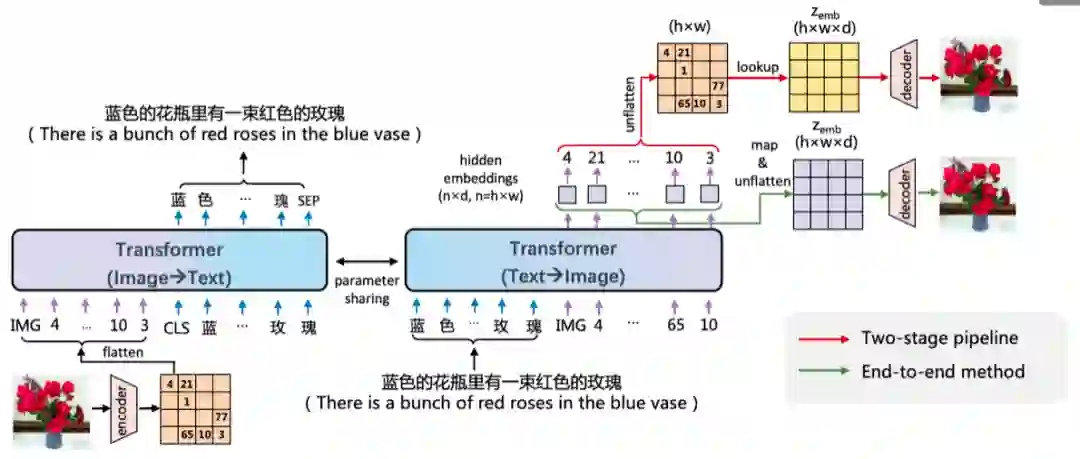
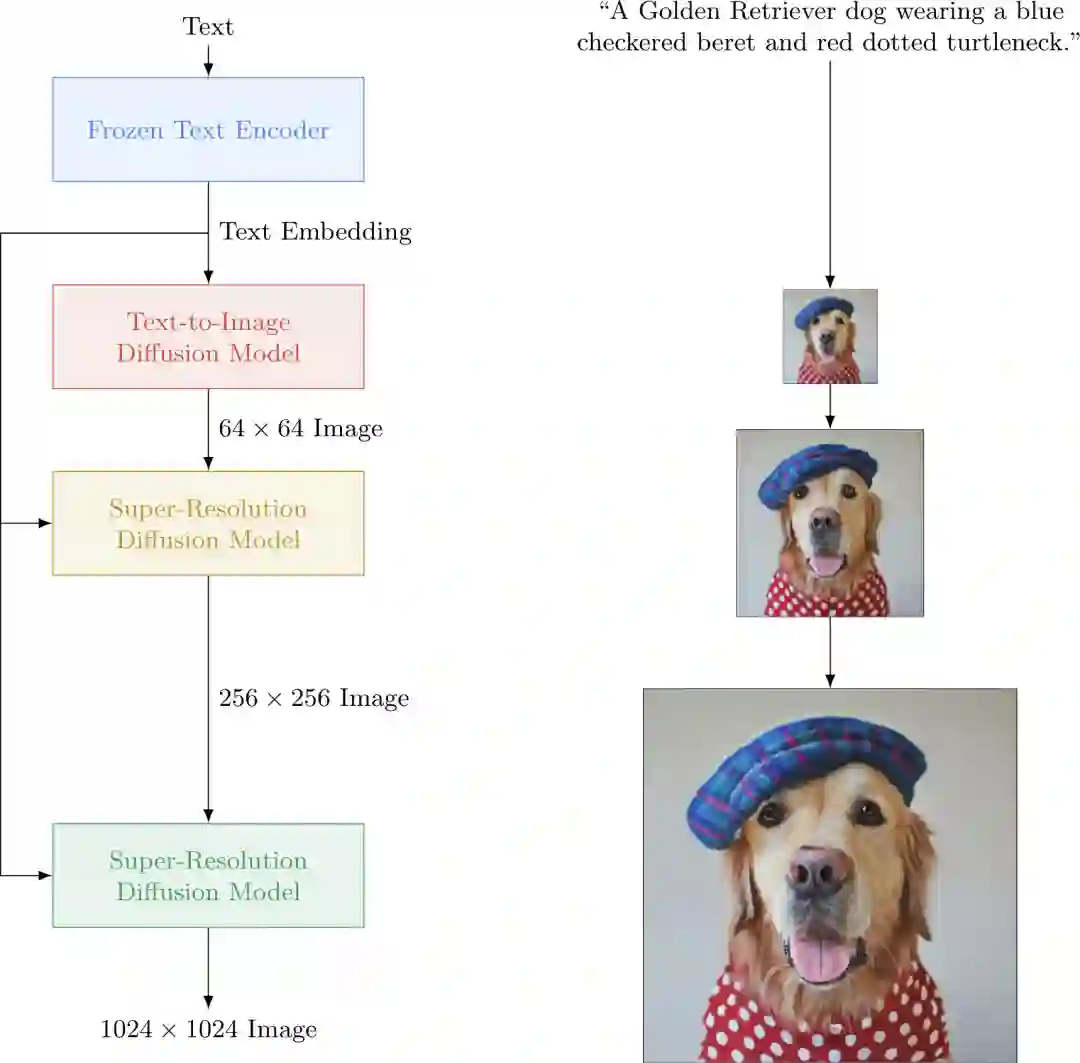
EasyNLP文图生成模型
模型架构
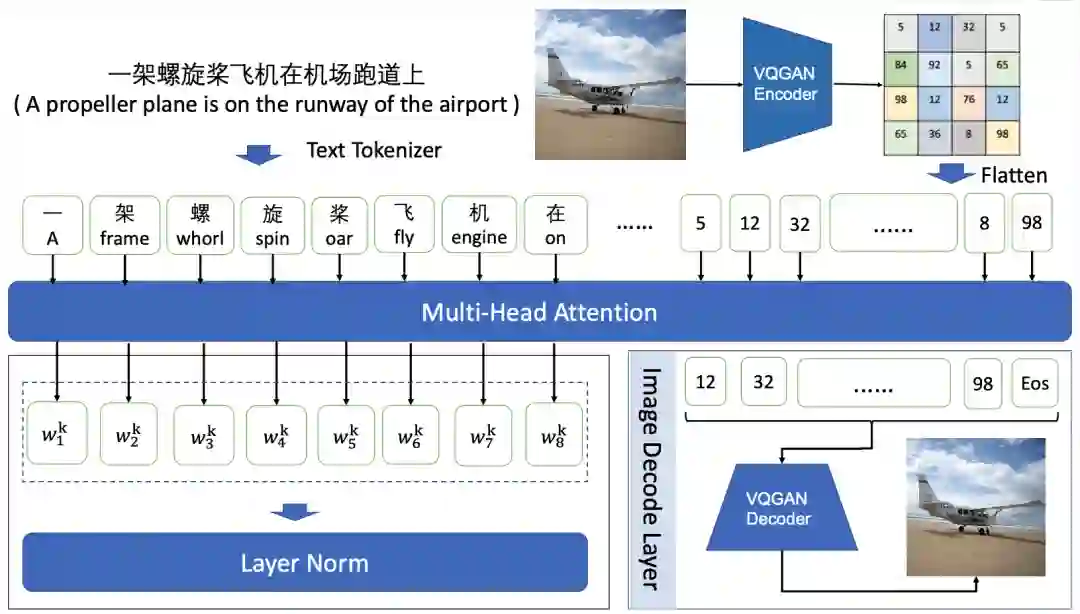
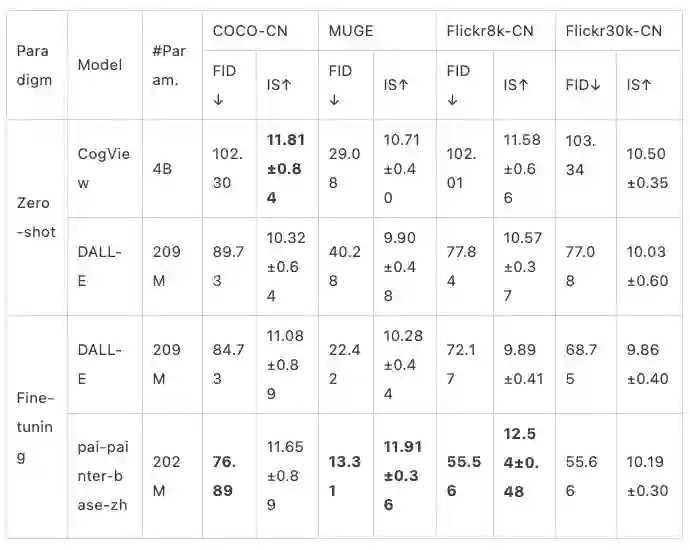
开源模型参数设置
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
模型实现
self.first_stage_model = VQModel(ckpt_path=vqgan_ckpt_path).eval()self.transformer = GPT(self.config)
# in easynlp/appzoo/text2image_generation/model.py
@torch.no_grad()def encode_to_z(self, x): quant_z, _, info = self.first_stage_model.encode(x) indices = info[2].view(quant_z.shape[0], -1) return quant_z, indices
x = inputs['image']x = x.permute(0, 3, 1, 2).to(memory_format=torch.contiguous_format)# one step to produce the logits_, z_indices = self.encode_to_z(x) # z_indice: torch.Size([batch_size, 256])
# in easynlp/appzoo/text2image_generation/model.py
@torch.no_grad()def decode_to_img(self, index, zshape): bhwc = (zshape[0],zshape[2],zshape[3],zshape[1]) quant_z = self.first_stage_model.quantize.get_codebook_entry( index.reshape(-1), shape=bhwc) x = self.first_stage_model.decode(quant_z) return x
# sample为训练阶段的结果生成,与预测阶段的generate类似,详解见下文generateindex_sample = self.sample(z_start_indices, c_indices, steps=z_indices.shape[1], ...)x_sample = self.decode_to_img(index_sample, quant_z.shape)
# in easynlp/appzoo/text2image_generation/model.py
def forward(self, inputs): x = inputs['image'] c = inputs['text'] x = x.permute(0, 3, 1, 2).to(memory_format=torch.contiguous_format) # one step to produce the logits z_indices = self.encode_to_z(x) # z_indice: torch.Size([batch_size, 256]) c_indices = c if self.training and self.pkeep < 1.0: mask = torch.bernoulli(self.pkeep*torch.ones(z_indices.shape, device=z_indices.device)) mask = mask.round().to(dtype=torch.int64) r_indices = torch.randint_like(z_indices, self.transformer.config.vocab_size) a_indices = mask*z_indices+(1-mask)*r_indices else: a_indices = z_indices cz_indices = torch.cat((c_indices, a_indices), dim=1) # target includes all sequence elements (no need to handle first one # differently because we are conditioning) target = z_indices # make the prediction _ = self.transformer(cz_indices[:, :-1]) # cut off conditioning outputs - output i corresponds to p(z_i | z_{<i}, c) logits = logits[:, c_indices.shape[1]-1:] return logits, target
# in easynlp/appzoo/text2image_generation/predictor.py
def preprocess(self, in_data): if not in_data: raise RuntimeError("Input data should not be None.")
if not isinstance(in_data, list): in_data = [in_data] rst = {"idx": [], "input_ids": []} max_seq_length = -1 for record in in_data: if "sequence_length" not in record: break max_seq_length = max(max_seq_length, record["sequence_length"]) max_seq_length = self.sequence_length if (max_seq_length == -1) else max_seq_length
for record in in_data: text= record[self.first_sequence] try: self.MUTEX.acquire() text_ids = self.tokenizer.convert_tokens_to_ids(self.tokenizer.tokenize(text)) text_ids = text_ids[: self.text_len] n_pad = self.text_len - len(text_ids) text_ids += [self.pad_id] * n_pad text_ids = np.array(text_ids) + self.img_vocab_size
finally: self.MUTEX.release()
rst["idx"].append(record["idx"]) rst["input_ids"].append(text_ids) return rst
# in easynlp/appzoo/text2image_generation/model.py
def generate(self, inputs, top_k=100, temperature=1.0): cidx = inputs sample = True steps = 256 for k in range(steps): x_cond = cidx _ = self.transformer(x_cond) # pluck the logits at the final step and scale by temperature logits = logits[:, -1, :] / temperature # optionally crop probabilities to only the top k options if top_k is not None: logits = self.top_k_logits(logits, top_k) # apply softmax to convert to probabilities probs = torch.nn.functional.softmax(logits, dim=-1) # sample from the distribution or take the most likely if sample: ix = torch.multinomial(probs, num_samples=1) else: ix = torch.topk(probs, k=1, dim=-1) # append to the sequence and continue cidx = torch.cat((cidx, ix), dim=1) img_idx = cidx[:, 32:] return img_idx
模型效果
经典案例
|
|
|


|


|
|
|
|


|


|
|
|
|


|


|
|
|
|


|


|
除了支持特定领域的应用,文图生成也极大地辅助了人类的艺术创作。使用训练得到的模型,我们可以秒变“中国国画艺术大师”,示例如下所示:


使用教程
安装EasyNLP
数据准备
import base64from io import BytesIOfrom PIL import Image
img = Image.open(fn)img_buffer = BytesIO()img.save(img_buffer, format=img.format)byte_data = img_buffer.getvalue()base64_str = base64.b64encode(byte_data) # bytes
# trainhttps://atp-modelzoo-sh.oss-cn-shanghai.aliyuncs.com/release/tutorials/painter_text2image/MUGE_train_text_imgbase64.tsv
# validhttps://atp-modelzoo-sh.oss-cn-shanghai.aliyuncs.com/release/tutorials/painter_text2image/MUGE_val_text_imgbase64.tsv
# testhttps://atp-modelzoo-sh.oss-cn-shanghai.aliyuncs.com/release/tutorials/painter_text2image/MUGE_test.text.tsv
模型训练
easynlp \ --mode=train \ --worker_gpu=1 \ --tables=MUGE_val_text_imgbase64.tsv,MUGE_val_text_imgbase64.tsv \ --input_schema=idx:str:1,text:str:1,imgbase64:str:1 \ --first_sequence=text \ --second_sequence=imgbase64 \ --checkpoint_dir=./finetuned_model/ \ --learning_rate=4e-5 \ --epoch_num=1 \ --random_seed=42 \ --logging_steps=100 \ --save_checkpoint_steps=1000 \ --sequence_length=288 \ --micro_batch_size=16 \ --app_name=text2image_generation \ --user_defined_parameters=' pretrain_model_name_or_path=alibaba-pai/pai-painter-large-zh size=256 text_len=32 img_len=256 img_vocab_size=16384
模型批量推理
easynlp \ --mode=predict \ --worker_gpu=1 \ --tables=MUGE_test.text.tsv \ --input_schema=idx:str:1,text:str:1 \ --first_sequence=text \ --outputs=./T2I_outputs.tsv \ --output_schema=idx,text,gen_imgbase64 \ --checkpoint_dir=./finetuned_model/ \ --sequence_length=288 \ --micro_batch_size=8 \ --app_name=text2image_generation \ --user_defined_parameters=' size=256 text_len=32 img_len=256=16384
使用Pipeline接口快速体验文图生成效果
# 直接构建pipelinedefault_ecommercial_pipeline = pipeline("pai-painter-commercial-base-zh")
# 模型预测data = ["宽松T恤"]results = default_ecommercial_pipeline(data) # results的每一条是生成图像的base64编码
# base64转换为图像def base64_to_image(imgbase64_str): image = Image.open(BytesIO(base64.urlsafe_b64decode(imgbase64_str))) return image
# 保存以文本命名的图像for text, result in zip(data, results): imgpath = '{}.png'.format(text) imgbase64_str = result['gen_imgbase64'] image = base64_to_image(imgbase64_str) image.save(imgpath) print('text: {}, save generated image: {}'.format(text, imgpath))
除了电商场景,我们还提供了以下场景的模型:
自然风光场景:“pai-painter-scenery-base-zh”
中国山水画场景:“pai-painter-painting-base-zh”
在上面的代码当中替换“pai-painter-commercial-base-zh”,就可以直接体验,欢迎试用。
# 加载模型,构建pipelinelocal_model_path = ...text_to_image_pipeline = pipeline("text2image_generation", local_model_path)
# 模型预测data = ["xxxx"]results = text_to_image_pipeline(data) # results的每一条是生成图像的base64编码
未来展望
Reference
1、Chengyu Wang, Minghui Qiu, Taolin Zhang, Tingting Liu, Lei Li, Jianing Wang, Ming Wang, Jun Huang, Wei Lin. EasyNLP: A Comprehensive and Easy-to-use Toolkit for Natural Language Processing. arXiv
2、Aditya Ramesh, Mikhail Pavlov, Gabriel Goh, Scott Gray, Chelsea Voss, Alec Radford, Mark Chen, Ilya Sutskever. Zero-Shot Text-to-Image Generation. ICML 2021: 8821-8831
3、Ming Ding, Zhuoyi Yang, Wenyi Hong, Wendi Zheng, Chang Zhou, Da Yin, Junyang Lin, Xu Zou, Zhou Shao, Hongxia Yang, Jie Tang. CogView: Mastering Text-to-Image Generation via Transformers. NeurIPS 2021: 19822-19835
4、Han Zhang, Weichong Yin, Yewei Fang, Lanxin Li, Boqiang Duan, Zhihua Wu, Yu Sun, Hao Tian, Hua Wu, Haifeng Wang. ERNIE-ViLG: Unified Generative Pre-training for Bidirectional Vision-Language Generation. arXiv
5、Peng Wang, An Yang, Rui Men, Junyang Lin, Shuai Bai, Zhikang Li, Jianxin Ma, Chang Zhou, Jingren Zhou, Hongxia Yang. Unifying Architectures, Tasks, and Modalities Through a Simple Sequence-to-Sequence Learning Framework. ICML 2022
6、Aditya Ramesh, Prafulla Dhariwal, Alex Nichol, Casey Chu, Mark Chen. Hierarchical Text-Conditional Image Generation with CLIP Latents. arXiv
7、Van Den Oord A, Vinyals O. Neural discrete representation learning. NIPS 2017
8、Esser P, Rombach R, Ommer B. Taming transformers for high-resolution image synthesis. CVPR 2021: 12873-12883.
9、Chitwan Saharia, William Chan, Saurabh Saxena, Lala Li, Jay Whang, Emily Denton, Seyed Kamyar Seyed Ghasemipour, Burcu Karagol Ayan, S. Sara Mahdavi, Rapha Gontijo Lopes, Tim Salimans, Jonathan Ho, David J. Fleet, Mohammad Norouzi: Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding. arXiv
10、Jiahui Yu, Yuanzhong Xu, Jing Yu Koh, Thang Luong, Gunjan Baid, Zirui Wang, Vijay Vasudevan, Alexander Ku, Yinfei Yang, Burcu Karagol Ayan, Ben Hutchinson, Wei Han, Zarana Parekh, Xin Li, Han Zhang, Jason Baldridge, Yonghui Wu. Scaling Autoregressive Models for Content-Rich Text-to-Image Generation. arXiv
11、https://zhuanlan.zhihu.com/p/528476134
大数据知识图谱—基于DataWorks搭建新零售数据中台
本篇文章向大家分享新零售企业如何基于DataWorks搭建数据中台,从商业模式及业务的设计,到数据中台的架构设计与产品选型,再到数据中台搭建的最佳实践,最后利用数据中台去反哺业务,辅助人工与智能的决策。 内容贡献:李启平(首义),盒马从初创至今的数据研发负责人,有非常资深的数仓及数据中台建设的经验,原阿里巴巴国际业务数仓负责人。
点击阅读原文查看详情。

