EasyCV开源|开箱即用的视觉自监督+Transformer算法库

一 导读
二 什么是EasyCV
1 项目背景
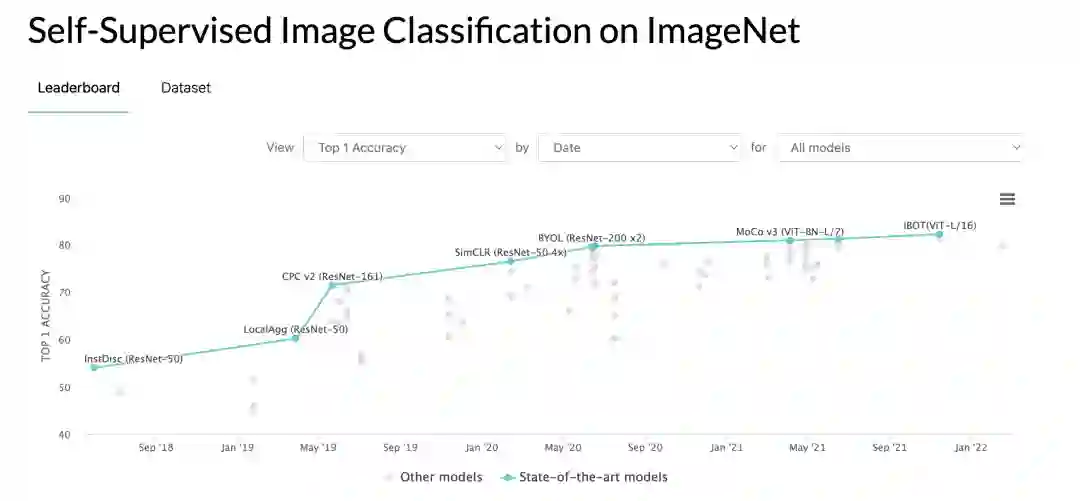
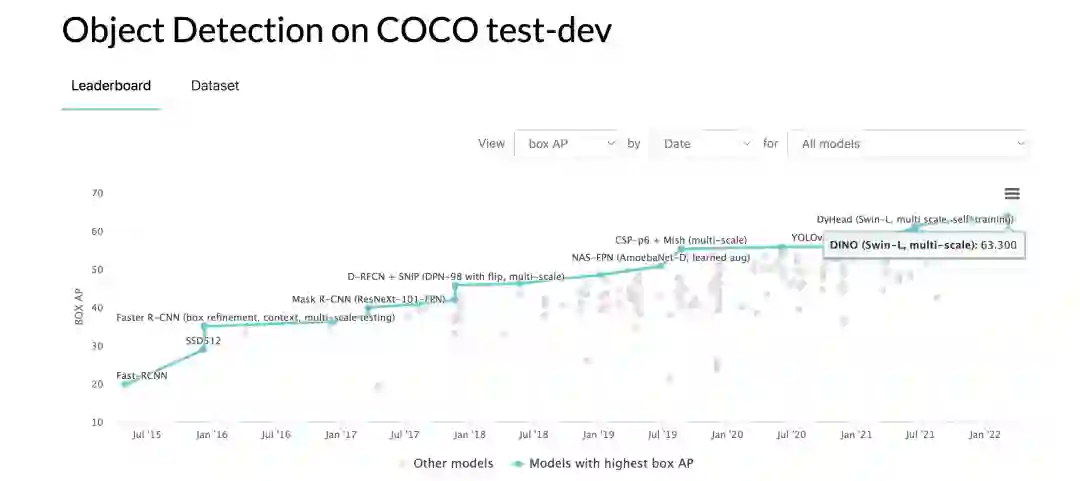
2 主要特性
-
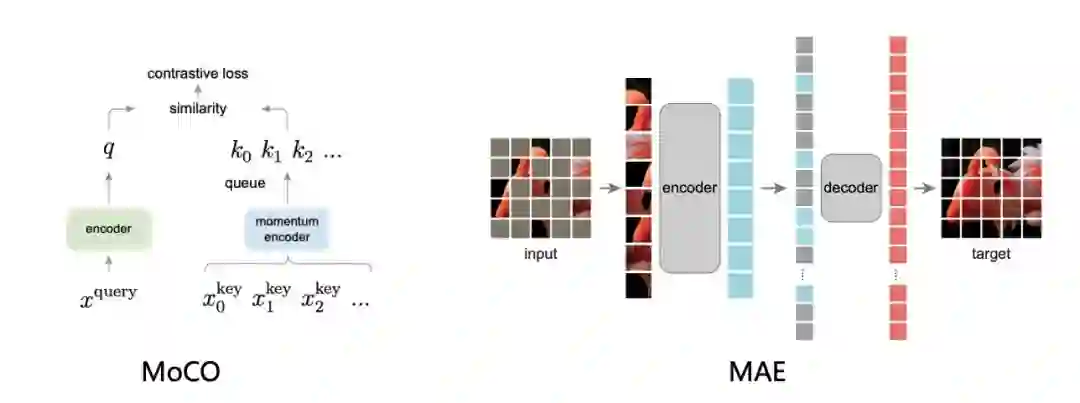
丰富完善的自监督算法体系:囊括业界有代表性的图像自监督算法SimCLR, MoCO, Swav, Moby, DINO等,以及基于mask图像预训练方法MAE,同时提供了详细的benchmark工具及复现结果。
-
丰富的预训练模型库:提供丰富的预训练模型,在以transformer模型为主的基础上,也包含了主流的CNN 模型, 支持ImageNet预训练和自监督预训练。兼容 PytorchImageModels 支持更为丰富的视觉Transformer backbone。
-
易用性和可扩展性 :支持配置方式、API调用方式进行训练、评估、模型导出;框架采用主流的模块化设计,灵活可扩展。
-
高性能 :支持多机多卡训练和评估,fp16训练加速。针对自监督场景数据量大的特点,利用DALI和TFRecord文件进行IO方面的加速。对接阿里云机器学习PAI平台训练加速、模型推理优化。
三 主要技术特点
1 技术架构
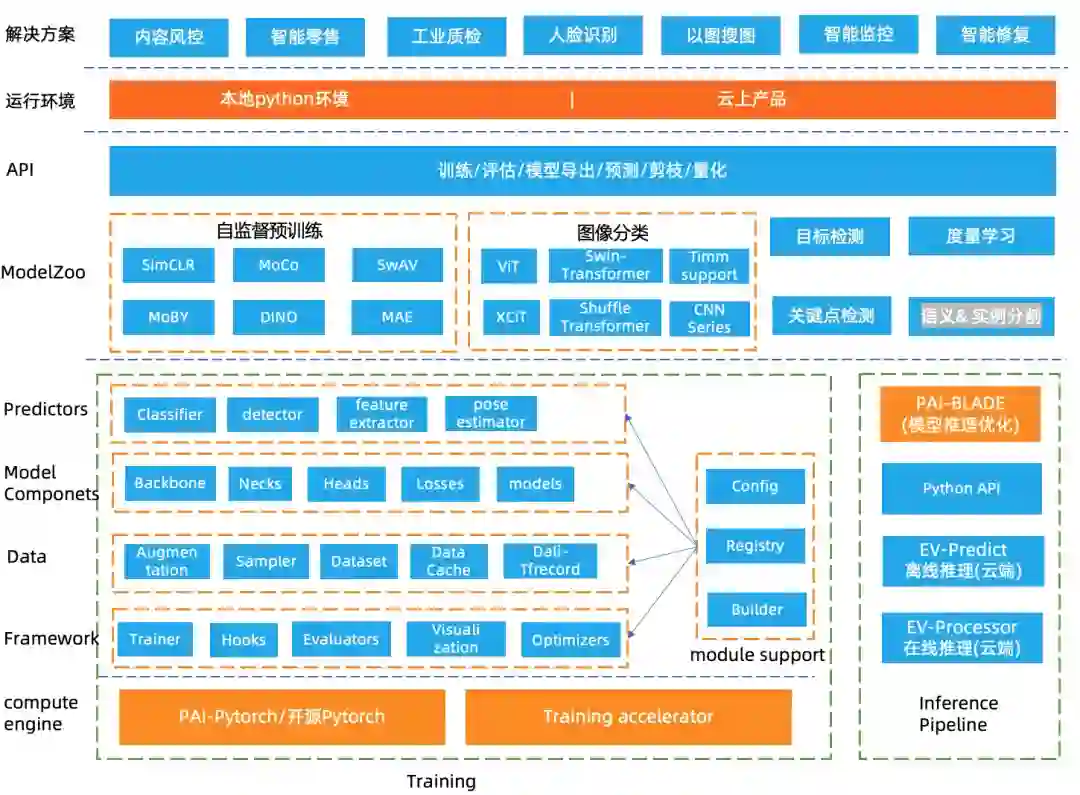
-
框架层:框架层复用目前开源领域使用较为广泛的 openmmlab/mmcv 接口,通过Trainer控制训练的主要流程,自定义Hooks进行学习率控制、日志打印、梯度更新、模型保存、评估等操作,支持分布式训练、评估。Evaluators模块提供了不同任务的评估指标,支持多数据集评估,最优ckpt保存,同时支持用户自定义评估指标。可视化支持预测结果可视化、输入图像可视化。
-
数据层:提供了不同数据源(data_source)的抽象,支持多种开源数据集例如Cifar、ImageNet、CoCo等,支持raw图片文件格式和TFrecord格式,TFrecord格式数据支持使用DALI进行数据处理加速,raw格式图片支持通过缓存机制加速数据读取。数据预处理(数据增强)过程抽象成若干个独立的pipeline,支持配置文件方式灵活配置不同的预处理流程。
-
模型层:模型层分为模块和算法,模块提供基础的backbone,常用的loss,neck和各种下游任务的head,模型ModelZoo涵盖了自监督学习算法、图像分类、度量学习、目标检测和关键点检测算法,后续会继续扩充支持更多的high-level算法。
-
推理:EasyCV提供了端到端的推理API接口,支持PAI-Blade进行推理优化,并在云上产品支持离在线推理。
-
API层:提供了统一的训练、评估、模型导出、预测的API。
2 完善的自监督算法体系
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
3 丰富的预训练模型库
4 易用性
-
框架提供参数化方式和python api接口启动训练、评估、模型导出,并且提供了完备的预测接口支持端到端推理。
# 配置文件方式python tools/train.py configs/classification/cifar10/r50.py --work_dir work_dirs/classification/cifar10/r50 --fp16
# 简易传参方式python tools/train.py --model_type Classification --model.num_classes 10 --data.data_source.type ClsSourceImageList --data.data_source.list data/train.txt
import easycv.toolsconfig_path = 'configs/classification/cifar10/r50.py'easycv.tools.train(config_path, gpus=8, fp16=False, master_port=29527)
推理示例
import cv2from easycv.predictors.classifier import TorchClassifier
output_ckpt = 'work_dirs/classification/cifar10/r50/epoch_350_export.pth'tcls = TorchClassifier(output_ckpt)
img = cv2.imread('aeroplane_s_000004.png')# input image should be RGB orderimg = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)output = tcls.predict([img])print(output)
-
框架目前focus在high-level视觉任务,针对分类检测分割三大任务,基于内容风控、智能零售、智能监控、同图匹配、商品类目预测、商品检测、商品属性识别、工业质检等应用场景,基于阿里巴巴内部的业务实践和服务阿里云外部客户的经验,筛选复现效果SOTA算法,提供预训练模型,打通训练、推理以及端侧部署流程, 方便用户进行各个场景应用的定制化开发。例如在检测领域,我们复现了 YOLOX 算法,集成了 PAI-Blade 的剪枝、量化等模型压缩功能,并能导出MNN模型进行端侧部署,详细可以参考模型 压缩量化tutorial 。
5 可扩展性
model = dict( type='Classification', pretrained=None, backbone=dict( type='ResNet', depth=50, out_indices=[4], # 0: conv-1, x: stage-x norm_cfg=dict(type='SyncBN')), head=dict( type='ClsHead', with_avg_pool=True, in_channels=2048, num_classes=1000))
eval_config = dict(initial=True, interval=1, gpu_collect=True)eval_pipelines = [ dict( mode='test', data=data['val1'], dist_eval=True, evaluators=[dict(type='ClsEvaluator', topk=(1, 5))], ), dict( mode='test', data=data['val2'], dist_eval=True, evaluators=[dict(type='RetrivalEvaluator', topk=(1, 5))], )]
class Projection(nn.Module): """Customized neck.""" def __init__(self, input_size, output_size): self.proj = nn.Linear(input_size, output_size) def forward(self, input): return self.proj(input)
model = dict( type='Classification', backbone=dict(...), neck=dict( type='Projection', input_size=2048, output_size=512 ), head=dict( type='ClsHead', embedding_size=512, num_classes=1000)
6 高性能
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
四 应用场景
-
公有云某客户利用物体检测组件定制化模型训练,完成其业务场景工人安装是否合格的智能审核。
-
某推荐用户使用自监督训练组件,使用其大量的无标注广告图片,训练图像表征模型,进而把图像特征接入推荐模型,结合推荐模型优化,ctr提升10+%。
-
某面板研发厂商基于EasyCV定制化瑕疵检测模型,完成云端训练、端侧部署推理。
五 Roadmap
-
Transformer 分类任务训练性能优化 & benchmark -
自监督学习增加检测&分割benchmark -
开发更多基于Transformer的下游任务,检测 & 分割 -
常用图像任务数据集下载、训练访问接口支持 -
模型推理优化功能接入
-
更多领域模型的端侧部署支持
-
自监督技术和Transformer结合,探索更高效的预训练模型
-
轻量化Transformer,基于训练推理的联合优化,推动Transformer在实际业务场景落地
-
基于多模态预训练,探索统一的transformer在视觉high-level 多任务上的应用
1、模型压缩量化tutorial :https://github.com/alibaba/EasyCV/blob/master/docs/source/tutorials/compression.md
2、PAI-Blade:
https://www.aliyun.com/activity/bigdata/blade
3、相似图匹配解决方案:
https://help.aliyun.com/document_detail/313270.html
4、PAI产品页面:
https://www.aliyun.com/product/bigdata/learn?spm=5176.19720258.J_3207526240.78.e9392c4aJWW64C
低代码音视频开发教程
点击阅读原文查看详情
登录查看更多
相关内容


相关VIP内容
相关资讯