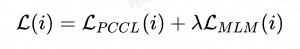![]()
一 导读
随着BERT、Megatron、GPT-3等预训练模型在NLP领域取得瞩目的成果,越来越多团队投身到超大规模训练中,这使得训练模型的规模从亿级别发展到了千亿甚至万亿的规模。然而,这类超大规模的模型运用于实际场景中仍然有一些挑战。首先,模型参数量过大使得训练和推理速度过慢且部署成本极高;其次在很多实际场景中数据量不足的问题仍然制约着大模型在小样本场景中的应用,提高预训练模型在小样本场景的泛化性依然存在挑战。为了应对以上问题,PAI团队推出了EasyNLP中文NLP算法框架,助力大模型快速且高效的落地。
EasyNLP背后的技术框架如何设计?未来有哪些规划?今天一起来深入了解。
二 EasyNLP简介
EasyNLP是PAI算法团队基于PyTorch开发的易用且丰富的中文NLP算法框架,支持常用的中文预训练模型和大模型落地技术,并且提供了从训练到部署的一站式NLP开发体验。EasyNLP提供了简洁的接口供用户开发NLP模型,包括NLP应用AppZoo和预训练ModelZoo,同时提供技术帮助用户高效的落地超大预训练模型到业务。除此之外EasyNLP框架借助PAI团队在通信优化、资源调度方面的深厚积累,可以为用户提供大规模、鲁棒的训练能力,同时可以无缝对接PAI系列产品,例如PAI-DLC、PAI-DSW、PAI-Designer和PAI-EAS,给用户带来高效的从训练到落地的完整体验。
EasyNLP已经在阿里巴巴内部支持10多个BU的业务,同时在阿里云上提供了NLP解决方案和ModelHub模型帮助用户解决业务问题,也提供用户自定义模型服务方便用户打造自研模型。在经过内部业务打磨之后,我们将EasyNLP推向开源社区,希望能够服务更多的NLP算法开发者和研究者,也希望和社区一起推动NLP技术特别是中文NLP的快速发展和业务落地。
EasyNLP is a Comprehensive and Easy-to-use NLP Toolkit[1]
EasyNLP主要特性如下:
三 EasyNLP框架特点
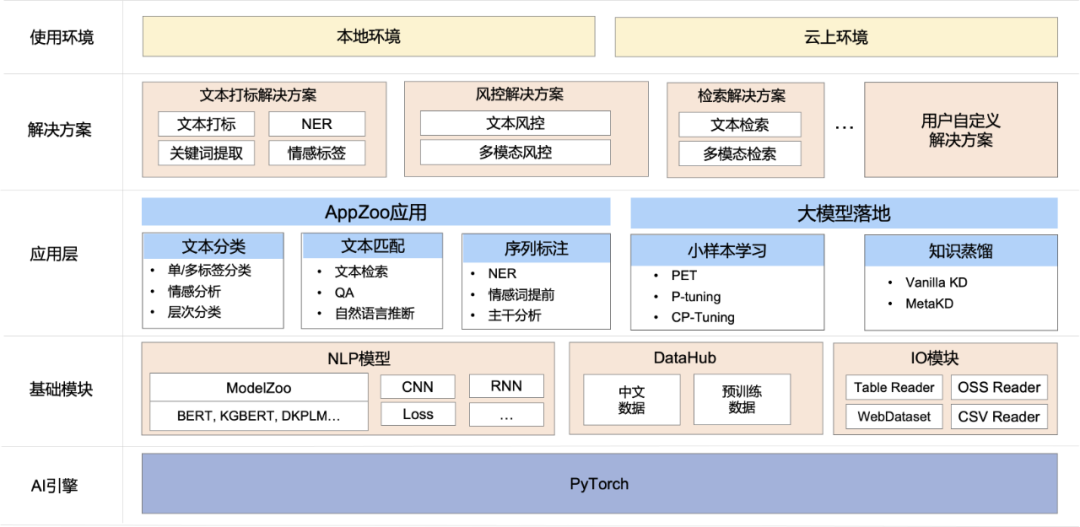
1 整体架构
![]()
如图所示,EasyNLP架构主要有如下几个核心模块:
2 大模型知识蒸馏技术
随着BERT等预训练语言模型在各项任务上都取得SOTA效果,大规模预训练模型已经成为 NLP学习管道中的重要组成部分,但是这类模型的参数量太大,而且训练和推理速度慢,严重影响到了需要较高QPS的线上场景,部署成本非常高。EasyNLP框架集成了经典的数据增强和知识蒸馏算法,使得训练出的小模型在相应任务行为上能够逼近大模型的效果。
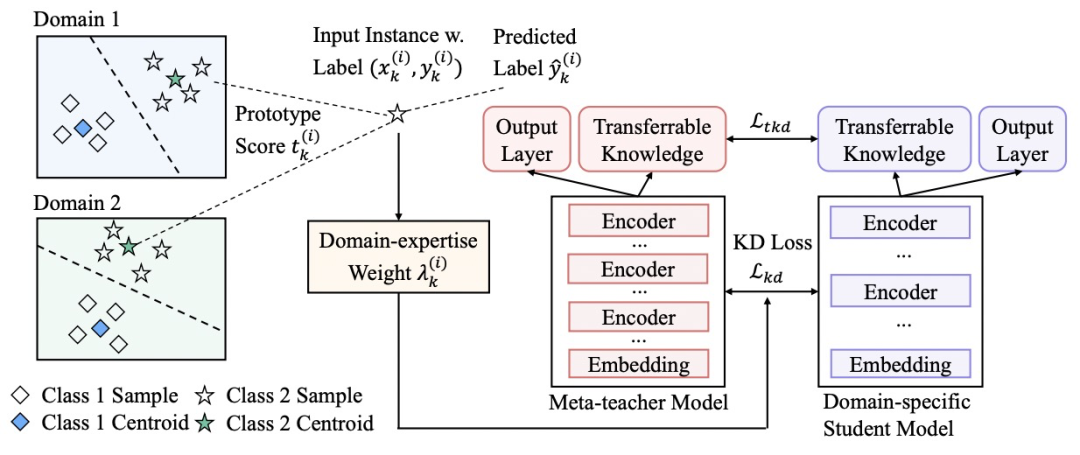
由于现有大部分的知识蒸馏工作都聚焦在同领域模型的蒸馏,而忽略了跨领域模型对目标蒸馏任务效果的提升。PAI团队进一步提出了元知识蒸馏算法MetaKD(Meta Knowledge Distillation),将跨领域的可迁移知识学出,在蒸馏阶段额外对可迁移的知识进行蒸馏。MetaKD算法使得学习到的学生模型在相应的领域的效果显著提升,逼近教师模型的效果。这一算法的核心框架图如下所示:
其中,MetaKD算法包括两个阶段。第一个阶段为元教师模型学习(Meta-teacher Learning)阶段,算法从多个领域的训练数据协同学习元教师模型,它对每个领域的样本都计算其典型得分(Prototype Score),使更具有跨领域典型性的样本在学习阶段有更大的权重。第二个阶段为元蒸馏(Meta-distillation)阶段,将元教师模型选择性地蒸馏到特定领域的学习任务上。由于元教师模型可能无法做到在所有领域上都有精确的预测效果,我们额外引入了领域专业性权重(Domain-expertise Weight),使元教师模型只将置信度最高的知识迁移到学生模型,避免学生模型对元教师模型的过拟合。
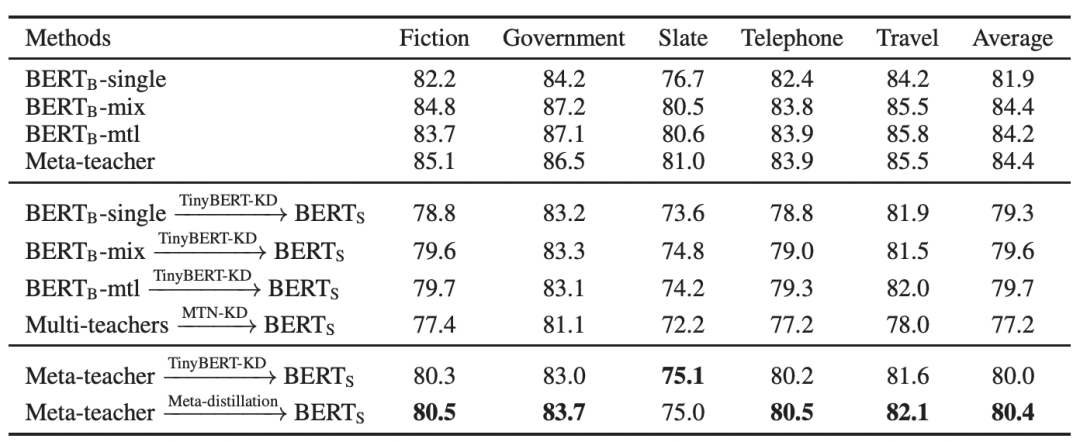
下图展示了MetaKD算法在MNLI的5个领域数据集的跨任务蒸馏效果。由结果可见,MetaKD蒸馏出的BERT-Small模型的和原始BERT模型相比,在保持模型精度值平均只下降1.5%的前提下参数减少了87%,大大减少了部署的压力。
目前,MetaKD算法也已经集成到EasyNLP框架中开源。
预训练语言模型规模的扩大,使得这一类模型在自然语言理解等相关任务效果不断提升。然而,这些模型的参数空间比较大,如果在下游任务上直接对这些模型进行微调,为了达到较好的模型泛化性,需要较多的训练数据。在实际业务场景中,特别是垂直领域、特定行业中,训练样本数量不足的问题广泛存在,极大地影响这些模型在下游任务的准确度。为了解决这一问题,EasyNLP框架集成了多种经典的小样本学习算法,例如PET、P-Tuning等,实现基于预训练语言模型的小样本数据调优,从而解决大模型与小训练集不相匹配的问题。
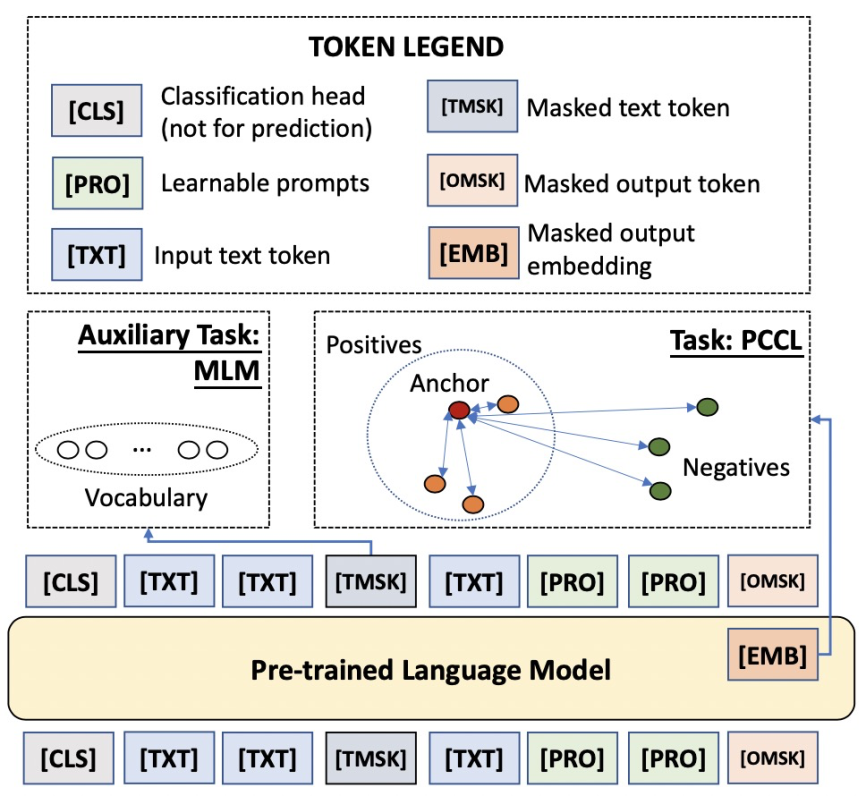
此外,PAI团队结合经典小样本学习算法和对比学习的思路,提出了一种不增添任何新的参数与任何人工设置模版与标签词的方案Contrastive Prompt Tuning (CP-Tuning)。这一算法的核心框架图如下所示:
如上图,CP-Tuning算法放弃了经典算法中以“[MASK]”字符对应预训练模型MLM Head的预测输出作为分类依据,而是参考对比学习的思路,将句子通过预训练模型后,以“[MASK]”字符通过预训练模型后的连续化表征作为features。在小样本任务的训练阶段,训练目标为最小化同类样本features的组内距离,最大化非同类样本的组间距离。在上图中,[OMSK]即为我们所用于分类的“[MASK]”字符,其优化的features表示为[EMB]。因此,CP-Tuning算法不需要定义分类的标签词。在输入侧,除了输入文本和[OMSK],我们还加入了模版的字符[PRO]。与经典算法不同,由于CP-Tuning不需要学习模版和标签词之间的对应,我们直接将[PRO]初始化为任务无关的模版,例如“it is”。在模型训练过程中,[PRO]的表示可以在反向传播过程中自动更新。除此之外,CP-Tuning还引入了输入文本的Mask,表示为[TMSK],用于同时优化辅助的MLM任务,提升模型在小样本学习场景下的泛化性。CP-Tuning算法的损失函数由两部分组成:
![]()
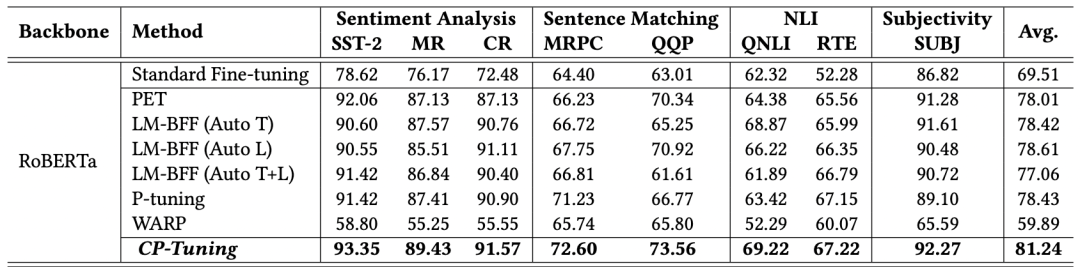
如上所示,两个部分分别为Pair-wise Cost-sensitive Contrastive Loss(PCCL)和辅助的MLM损失。我们在多个GLUE小样本数据集上进行了验证,其中训练集中每个类别限制只有16个标注样本。从下述结果可以看出,CP-Tuning的精确度超越了经典的小样本学习算法,也比标准Fine-tuning算法的精确度高10%以上。
目前,除了我们自研的CP-Tuning算法之外,EasyNLP框架中集成了多种经典小样本学习算法例如PET、P-tuning等。
4 大模型落地实践
下面我们给出一个示例,将一个大的预训练模型(hfl/macbert-large-zh)在小样本场景上落地,并且蒸馏到仅有1/100参数的小模型上。如下图所示,一个大模型(3亿参数)在一个小样本场景上原始的Accuracy为83.8%,通过小样本学习可以提升7%,达到90.6%。同时,如果用一个小模型(3百万参数)跑这个场景的话,效果仅有54.4%,可以把效果提升到71%(提升约17%),inference的时间相比大模型提升了10倍,模型参数仅为原来的1/100。
|
|
|
|
|
|
|
|
|
|
|
|
|
alibaba-pai/pai-bert-tiny-zh
|
|
|
|
|
|
alibaba-pai/pai-bert-tiny-zh
|
|
|
|
|
|
|
|
|
|
四 应用案例
EasyNLP支撑了阿里巴巴集团内10个BU20多个业务,同时过PAI的产品例如PAI-DLC、PAI-DSW、PAI Designer和PAI-EAS,给集团用户带来高效的从训练到落地的完整体验,同时也支持了云上客户自定定制化模型和解决业务问题的需求。针对公有云用户,对于入门级用户PAI-Designer组件来通过简单调参就可以完成NLP模型训练,对于高级开发者,可以使用AppZoo训练NLP模型,或者使用预置的预训练模型ModelZoo进行finetune,对于资深开发者,提供丰富的API接口,支持用户使用框架进行定制化算法开发,可以使用我们自带的Trainer来提升训练效率,也可以自定义新的Trainer。
下面列举几个典型的案例:
五 RoadMap
项目开源地址:https://github.com/alibaba/EasyNLP
参考文献
-
[AAAI 22] DKPLM: Decomposable Knowledge-enhanced Pre-trained Language Model for Natural Language Understanding.
https://arxiv.org/abs/2112.01047
-
[ACL 2021] Meta-KD: A Meta Knowledge Distillation Framework for Language Model Compression across Domains.
https://arxiv.org/abs/2012.01266
-
[arXiv] Making Pre-trained Language Models End-to-end Few-shot Learners with Contrastive Prompt Tuning:
https://arxiv.org/pdf/2204.00166
-
[AAAI 22] From Dense to Sparse: Contrastive Pruning for Better Pre-trained Language Model Compression.
https://arxiv.org/abs/2112.07198
-
[EMNLP 2021] TransPrompt: Towards an Automatic Transferable Prompting Framework for Few-shot Text Classification.
https://aclanthology.org/2021.emnlp-main.221/
-
[CIKM 2021]. EasyTransfer -- A Simple and Scalable Deep Transfer Learning Platform for NLP Applications.
https://github.com/alibaba/EasyTransfer
[1]https://github.com/alibaba/EasyNLP
[2]https://github.com/alibaba/EasyNLP/tree/master/examples/knowledge_distillation
[3]https://github.com/alibaba/EasyNLP/tree/master/examples/fewshot_learning
[4]https://github.com/alibaba/EasyNLP/tree/master/examples/landing_large_ptms
[5]达摩院NLP团队:
https://github.com/alibaba/AliceMind
[6]文本风控解决方案:https://help.aliyun.com/document_detail/311210.html
[7]通用文本打标解决方案:https://help.aliyun.com/document_detail/403700.html
Dubbo 3.0 服务治理最佳实践