我删掉了Transformer中的这几层…性能反而变好了?

极市导读
本文解读了一篇论文,关于利用contribution score和criticality score评价模型中各个模块的重要性,了解模块的重要性程度后对不重要的模块进行剪枝或者参数回卷,使模型得到优化。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
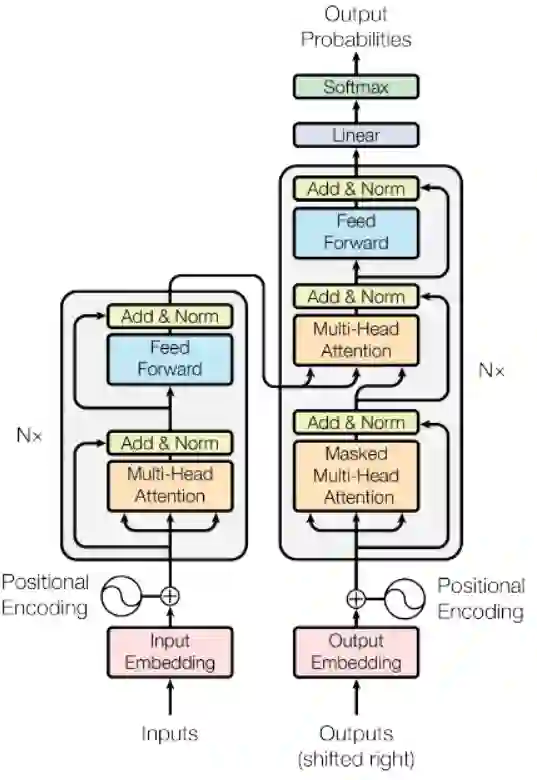
基于Transformer结构的各类语言模型(Bert基于其encoder,Gpt-2基于其decoder)早已经在各类NLP任务上大放异彩,面对让人眼花缭乱的transformer堆叠方式,你是否也会感到迷茫?没关系,现在让我们回到最初,再次看看transformer 本来的模样——Rethinking the Value of Transformer Components。该文收录已于COLING 2020。
众所周知,一个完整的transformer结构可以切分成Encoder-self attention(“E:SA”), Encoder-Feed Forward(“E:FF”), Decoder-Self Attention(“D:SA”), Decoder-Encoder Attention(“D:EA”) 和 Decoder-Feed Forward(“D:FF”) 5个sub-layer结构。文中作者采用了两种度量方式确认这些sub-layer的重要程度。
方法稍后再谈,先上干货,实验结果表明:
-
Decoder self-attention layers是最不重要的,而 Decoder feed-forward layers是最重要的; -
离模型的输入和输出越近的sub-layer要比其他的重要些; -
在 decoder里越靠后的encoder-attention layer要比之前的重要。
这些结果对不同的度量方法,数据集,初始化种子以及模型容量都能保持一致性。
论文题目:
Rethinking the Value of Transformer Components
论文链接:
https://arxiv.org/pdf/2011.03803.pdf_Arxiv
模块重要性分析
所谓的重要性究竟是什么呢?论文认为,这主要包括两个方面:
-
Contribution in information Flow,对于模型信息流的贡献程度 -
Criticality in Representation Generalization,模型的模块对参数的扰动表现出不同的鲁棒性
Contribution in Information Flow
Transformer 最初是用来做机器翻译任务的。所谓的information flow就是指数据如何从源语言经过Transformer的encoder和decoder最终成为目标语言的。如何衡量模型的每个部分对information flow做出的贡献呢? 最直观的想法就是去掉那个部分看看同样条件下模型的效果如何。如果去掉那个部分,模型效果没什么变化,那就说明该部分没做什么贡献,反之,如果删掉该部分,模型效果显著降低则说明它贡献卓著,没它不行。作者采用了如下的量化方法:
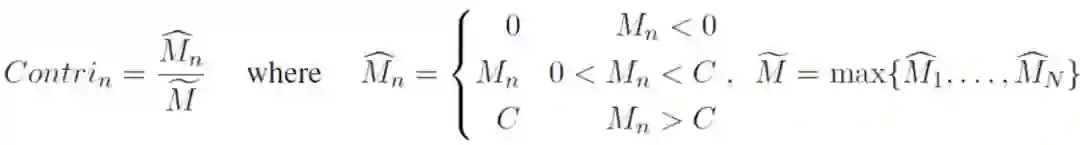
公式中指的是去除第n个部分后模型整体的BLEU得分降。为了避免出现重要性指数出现负值和爆炸性下跌,作者将的值设定在[0,C]之间(真的会出现负重要性指数吗?那样倒挺好——模型变小,效果更好)。然后通过除以最大的得分降将的值进行了归一化,这里作者设置的上限C值为基线模型的BLEU得分的1/10.
Criticality in Representation Generalization
这里说的criticality指的是模型的模块对参数的扰动表现出不同的鲁棒性。比方说,如果将某个模块的参数重置为初始化参数,模型的表现变差,那么这个模块就是critical的,否则就是non-critical的。有人在理论上将这个criticality给公式化了,而且他们表明这个criticality可以反映神经网络的泛化能力。作者便是参考了这个工作,对网络的第n个模块,定义
即初始权重和最终权重的一个凸组合。那么第n个部分的criticality score就可以表示为
这个式子定量的说明了criticality是最小的能使模型在阈值的情况下保持性能。这个值越小说明该模块越不重要,这里取的是 0.5 BLEU分。两种度量方法虽然都是基于模块对模型表现的影响的,但是又有不同之处。Contribution score可以看成是 hard metric(完全删除模块),而 Criticality score可以看成是一种soft metric,它衡量的是在保证模型表现的前提下模块参数能多大程度的回卷。
实验
实验是在WMT2014 English-German(En-De)和English-French(En-Fr)两个机器翻译数据集上进行的,作者使用的Transformer模型和Transformer的那篇原始文献(Vaswani et al.,2017)是一样的。Transformer model 一共6层编码器和解码器,layer size是512,feed-forward sub-layer的size是2048,attention head的数值是8,dropout是0.1,initialization seed设置为1。
观察模块的重要性
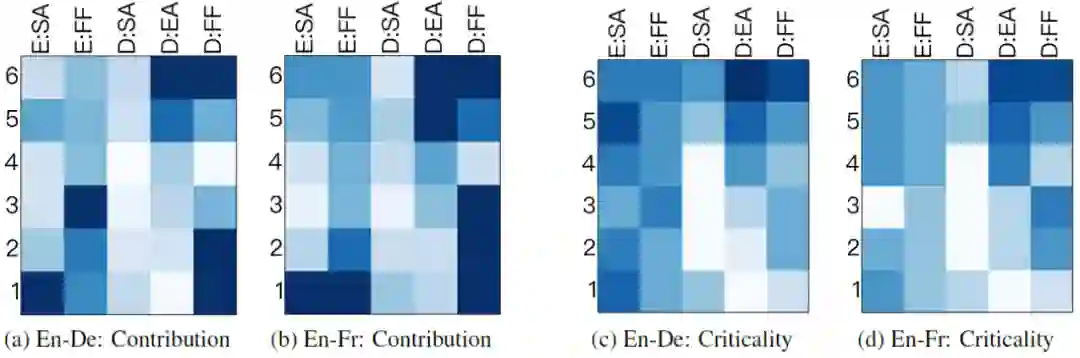
上图是采用两种度量方式在两个数据集上的实验结果,其中X轴代表的是模块类型,Y轴表示的是layer id。其中颜色越深就越重要。可以看出两种度量方式的结果很大程度上是一致的,比方说:
-
the decoder self-attention(D:SA)是最不重要的,而the decoder feed-forward layers(D:FF)是最重要的。 -
编码器里越靠前(E:SA和E:FF)和解码器里越靠后(D:EA和D:FF)是更重要的。这个其实很直观,因为这些模块离数据的输入和输出更近,所以对输入句子的理解和输出句子的生成要更加重要些。 -
在解码器里越靠后的encoder-attention(D:EA)layers要比之前的encoder-attention layers重要。
分析不重要的模块
更低的dropout比例和更多的训练数据会让不重要的模块变得更少(dropout是一种常见的用来防止过拟合的手段)。为了保证模型的效果,当我们使用dropout的时候其实说明模型本身有一定程度上的冗余。在不降低模型效果的前提下,小的dropout比例刚好说明模型的冗余越少,也就是不重要的模块更少。大规模的训练数据本身就自带更多的patterns。需要充分发挥transformer的各个模块才能有效地学习到。
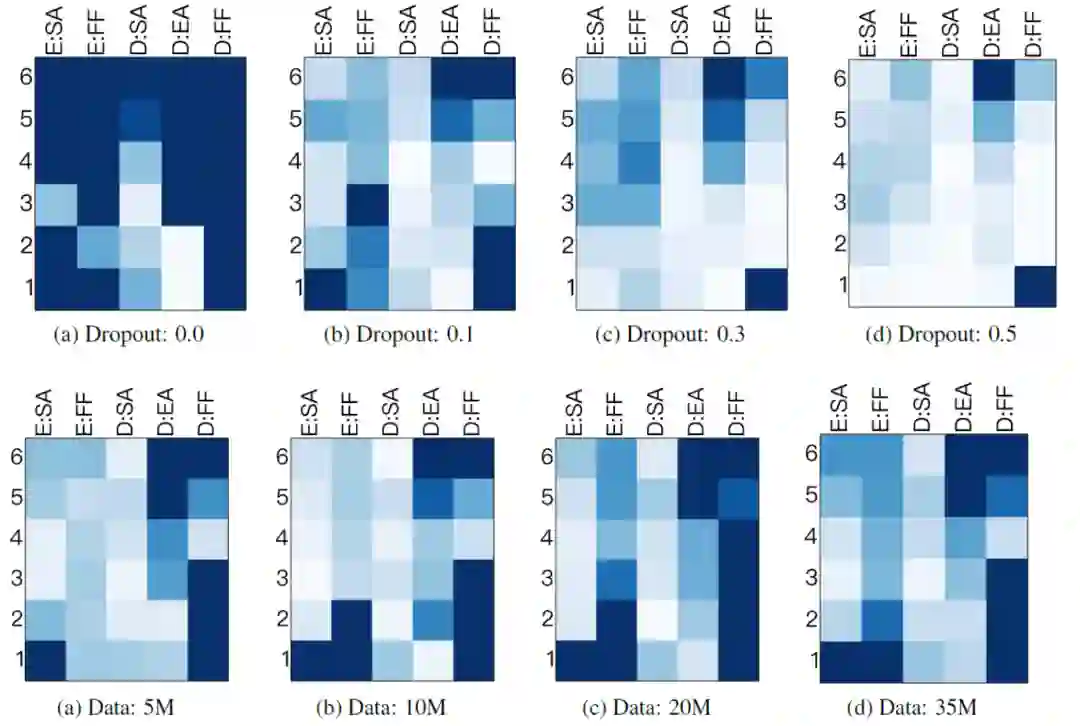
从上面两张图可以明显的看出:当使用更小的dropout和更大的数据集时,颜色深的版块明显变得更多。此外之前所得到的结论这里依然成立。
区分和利用一批不重要的模块
之前的结果都是只删除一个模块得到,那我们一次性删除多个模块呢?
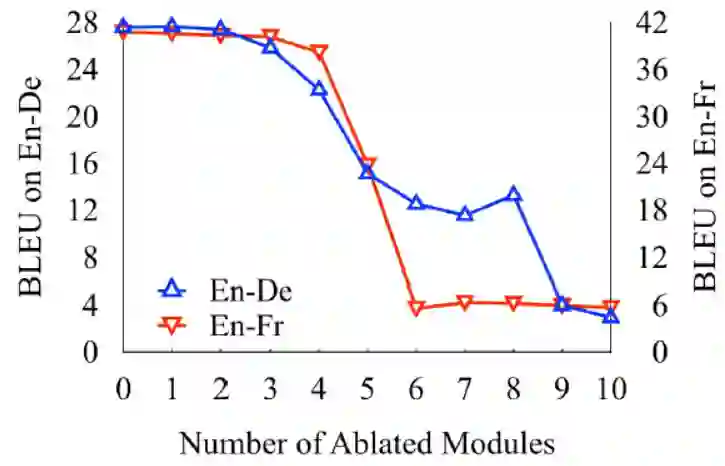
上图显示当我们删除3到4个不重要的模块时,模型效果并没有明显降低。但是当删的更多了之后,模型的效果会受到较大的影响。那么我们是否可以利用这些不怎么重要的模块去对模型进行优化呢?作者采用了两种方式:一个是模块剪枝,另一个是模块回卷。模块剪枝就是将不重要的模块直接删掉,因为删掉了相应模块使得模型的参数变小,作为对比作者在相同参数量下使用了一个浅层的decoder模型结果如表:
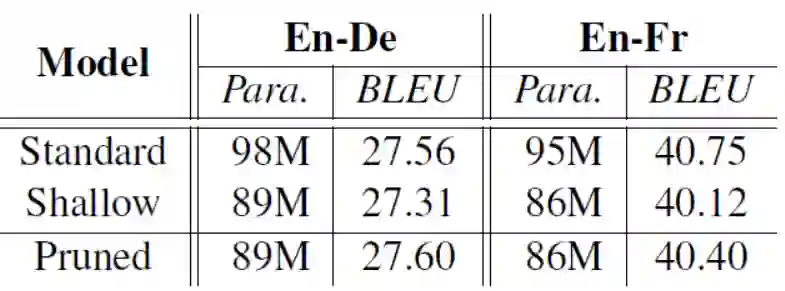
可以看出剪枝后的模型要比同样参数下的浅层模型结果要好,而且也能达到和原始模型相应的效果,有的甚至更好(还真有)。模块回卷就是将不重要的模块参数回卷到初始化状态,再和其他模块一起微调一下得到的训练结果要比原始模型好一点。
总结
我们可以利用contribution score和criticality score评价模型中各个模块的重要性,知晓了模块的重要性程度后我们可以对不重要的模块进行剪枝或者参数回卷都能在一定程度上让原有模型得到优化。

# CV技术社群邀请函 #

备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~





