SCRDet:遥感旋转目标检测方法解读
点击上方“CVer”,选择加"星标"或“置顶”
重磅干货,第一时间送达

作者:yangxue(论文一作)
https://zhuanlan.zhihu.com/p/107400817
本文已由原作者授权,不得擅自二次转载
一、 遥感目标检测
遥感目标检测其实是一个比较有意思的研究领域。由于遥感图像是俯瞰拍摄的,其包含的空间场景更大更复杂,包含的种类和数量更多。从检测框形式划分,遥感目标的检测可以分成水平检测和旋转检测两种。遥感目标检测难点主要包括小目标 (small objects)、密集 (cluttered arrangement)、方向任意(arbitrary orientations),我将结合自己ICCV2019的一篇文章进行介绍,文章链接如下:
http://openaccess.thecvf.com/content_ICCV_2019/papers/Yang_SCRDet_Towards_More_Robust_Detection_for_Small_Cluttered_and_Rotated_ICCV_2019_paper.pdf

二、SCRDet检测器
首先,文章认识到了遥感目标检测所面临的以上三个问题,针对这些问题进行改进:
对于小目标:通过特征融合和anchor采样角度出发设计了一个特征融合结构。
对于密集排列问题:设计了一个有监督的多维注意力网络以减少背景噪声的不利影响。
对于任意方向问题:通过添加IoU常数因子设计了一种改进的平滑L1损失,该因子专门用于解决旋转边界框回归的边界问题。
整个框架是基于Faster RCNN的,主要包含SF-Net、MDA-Net和IoU-Smooth L1 Loss,结构图如下:

1. SF-Net
小目标检测一直是较难克服的一个问题,这在遥感图像中尤其突出。文章认为特征融合和有效的采样是较好检测小目标的关键。对于anchor-based来说,anchor的铺设方式直接影响正样本采样率。经典的anchor铺设方式和特征图的分别率有关,也就是anchor铺设的步长(C2-C5上的anchor步长分别是4,8,16,32)。随着网络加加深,特征图分辨率下降,anchor的步长扩大,常常会导致小目标的采样丢失,如下图所示:
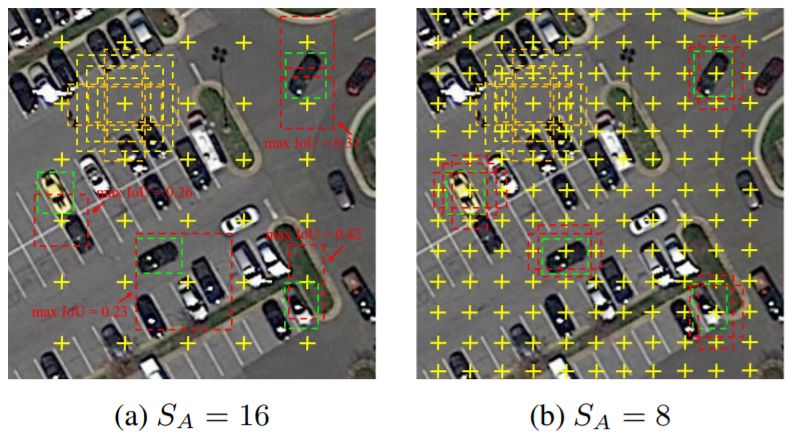
通过这样的发现,文章通过resize的方式选取了一个合适的特征图分别率,尽可能保证小目标都被采样到,再加上简单的特征融合保证丰富的语义信息和位置信息。在这里之所以不使用C2,是因为遥感目标检测会设置较多的尺度和比例,那么在C2这个特征图上面的anchor就变得太多了,而且在遥感数据集中最小的目标一般也都在10像素以上(特指DOTA1.0,DOTA1.5则给出了像素10以下的标注)。
SF-Net的结构图如下:
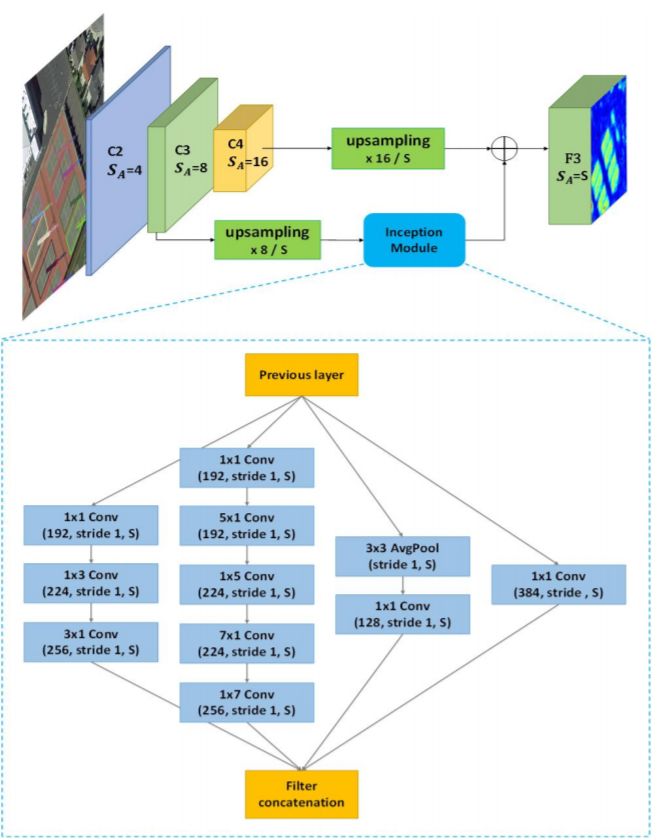
由于论文是基于Faster RCNN出发的,因此没有考虑FPN这种做法。但是在实际的应用过程中,用了这么多检测方法我还是觉得FPN真香,顺便给出两个我自己写的基于TF的两个代码(Faster RCNN和FPN),非常适合需要入门的人使用,欢迎star:
https://github.com/DetectionTeamUCAS/Faster-RCNN_Tensorflow
https://github.com/DetectionTeamUCAS/FPN_Tensorflow
虽然SF-Net这个结构真的挺土的,但是对于我来说在遥感检测尤其是小目标检测还是有一些启发的,就是anchor-based方法要充分保证RPN的召回。增加anchor这种做法是暴力的,一个较大的副作用就是检测器变得非常慢,因此我对anchor-free方法在遥感上的应用还是很期待的,目前我的师弟在这方法已经有了初步的进展:
https://arxiv.org/abs/1912.10694
https://arxiv.org/abs/2001.02988
2. MAD-Net
由于遥感图像背景的复杂性,RPN产生的建议区域可能引入大量噪声信息,如下图所示。
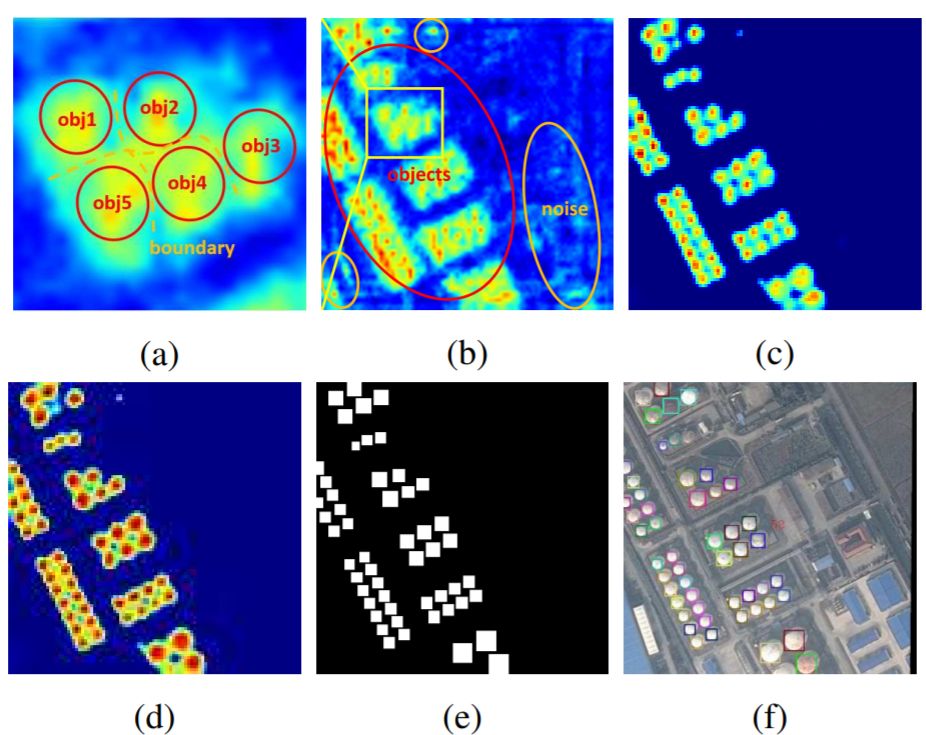
过多的噪音可能会混淆物体信息,物体之间的界限将变得模糊,导致漏检并增加虚警。因此,有必要增强物体特征并削弱非物体特征。为了更有效地捕捉复杂背景下小物体的特征,文章设计了一种有监督的多维注意力网络(MDA-Net),如下图所示。具体来说,在基于像素的注意网络中,特征图F3通过具有不同大小卷积核进行卷积运算,学习得到双通道的显著图(参见上图d)。这个显著图显示了前景和背景的分数。选择显著图中的一个通道与F3相乘,得到新的信息特征图A3(参见上图c)。需要注意的是,Softmax函数之后的显着图的值在[0,1]之间。换句话说,它可以降低噪声并相对的增强对象信息。由于显著图是连续的,因此不会完全消除背景信息,这有利于保留某些上下文信息并提高鲁棒性。
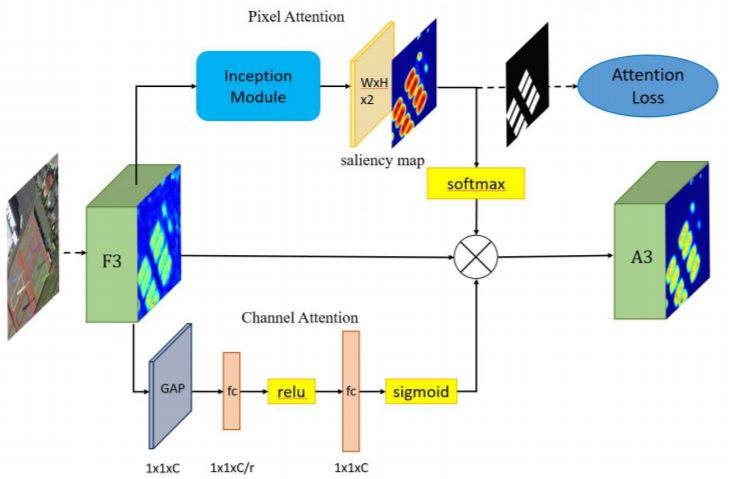
其实这个模块现在也是被用的比较烂了,就是空间注意力加通道注意力的组合。但在实际的应用过程中,空间注意力在遥感检测真的是非常有用的,我在打比赛的时候基本会加上。讲到这里其实就是我投CVPR2019的文章(R2CNN++: Multi-Dimensional Attention Based Rotation Invariant Detector with Robust Anchor Strategy),结果当然是被惨拒,在ICCV2019也是被说是增量性的贡献。我当然是比较同意的,这本就是我早期刷DOTA榜单的一个总结,ICCV2019之所以会中主要是因为第三个部分。
3. IoU-Smooth L1 Loss
首先我们要先了解一下两种旋转边界框的两种常见的方式。
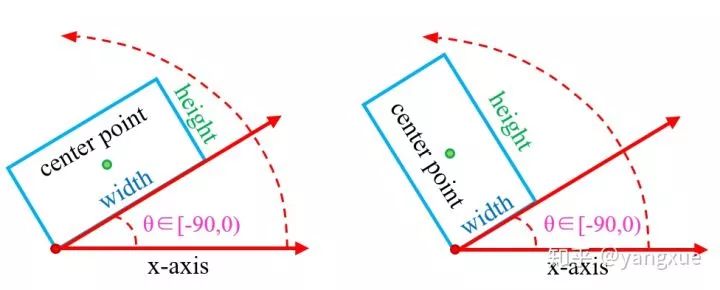
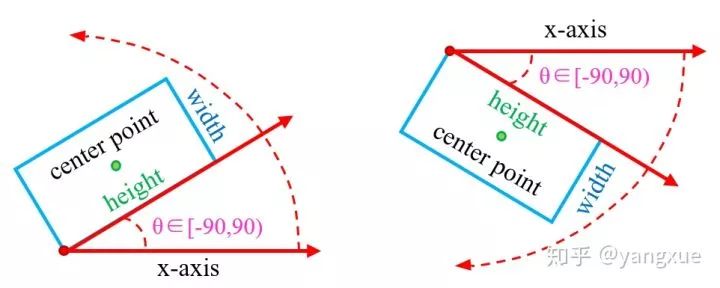
SCRDet是采用的opencv 表示法。在当前常用的旋转检测框的角度定义下,由于存在旋转角度的边界问题,会产生不必要的损失,如下图所示:
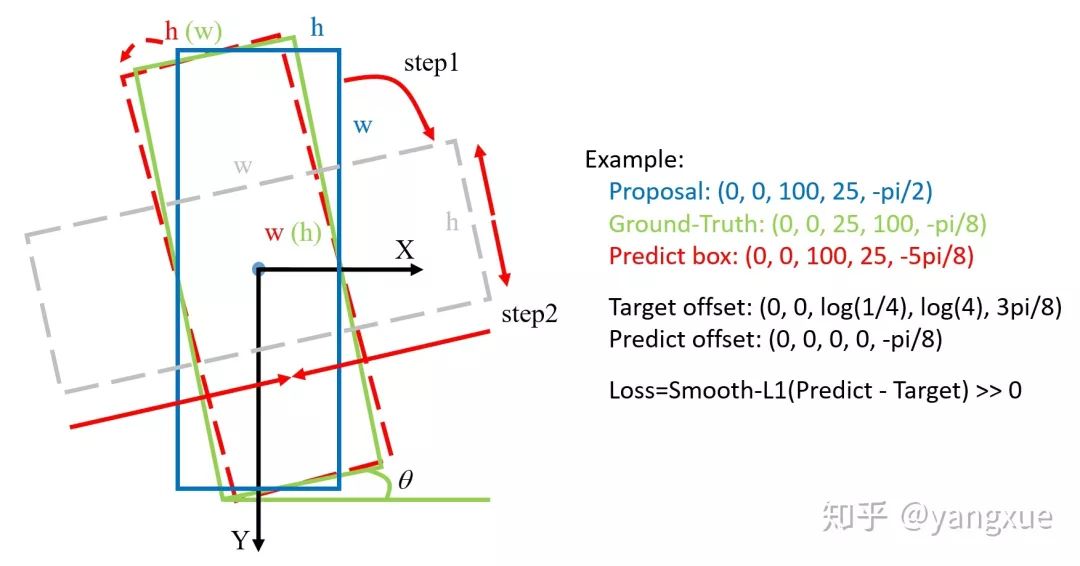
最理想的角度回归路线是由蓝色框逆时针旋转到红色框,但由于角度的周期性,导致按照这个回归方式的损失非常大(参见上图右边的Example)。此时模型必须以更复杂的形式回归(例如蓝色框顺时针旋转,同时缩放w和h),增加了回归的难度。为了更好地解决这个问题,我们在传统的smooth L1 损失函数中引入了IoU常数因子。在边界情况下,新的损失函数近似等于0,消除了损失的突增。新的回归损失可分为两部分,smooth L1回归损失函数取单位向量确定梯度传播的方向,而IoU表示梯度的大小,这样loss函数就变得连续。此外,使用IoU优化回归任务与评估方法的度量标准保持一致,这比坐标回归更直接和有效。IoU-Smooth L1 loss公式如下:
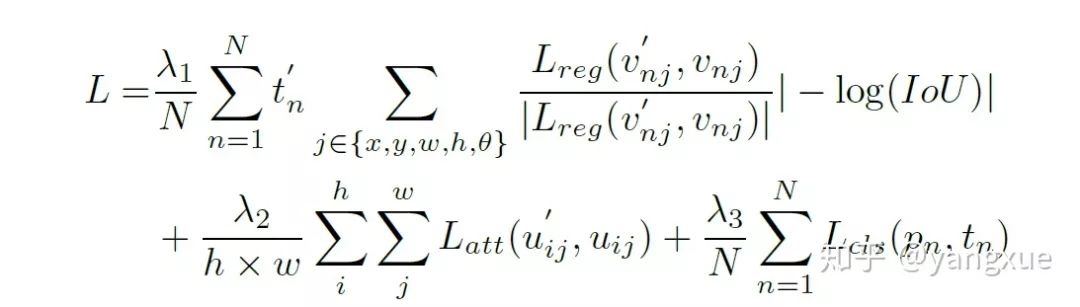
可以看一下两种loss在边界情况下的效果对比:
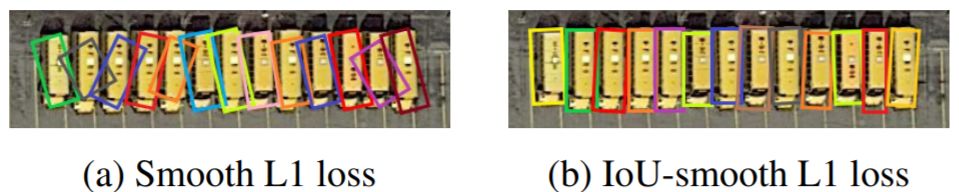
导致这种原因的根本原因我觉得是角度的预测超出了所定义范围。其实解决这种问题的方法并不唯一,RRPN和R-DFPN在论文的loss公式中就判断了是不是在定义范围内,通过加减 
关于IoU-Smooth L1 Loss,我是在转投ICCV2019的ddl之前临时加的,没想到成为中稿的关键,真的是无心插柳柳成荫。因此我将SCRDet拆成R2CNN++和IoU-Smooth L1 Loss两部分单独开源:
https://github.com/DetectionTeamUCAS/R2CNN-Plus-Plus_Tensorflow
https://github.com/DetectionTeamUCAS/RetinaNet_Tensorflow_Rotation
IoU-Smooth L1 Loss是在RetinaNet旋转检测代码上进行检验的,发现效果出奇的好,从62.25涨到68.65,但也发现稍微改动配置文件就NAN,难搞。
4. 实验结果
最终实验主要是在DOTA数据集上进行的,在当时也算是SOTA的论文。
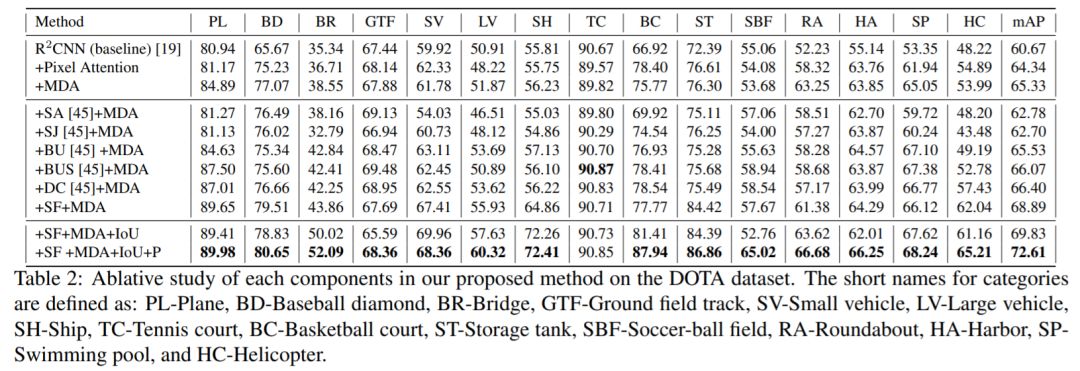
消融实验:
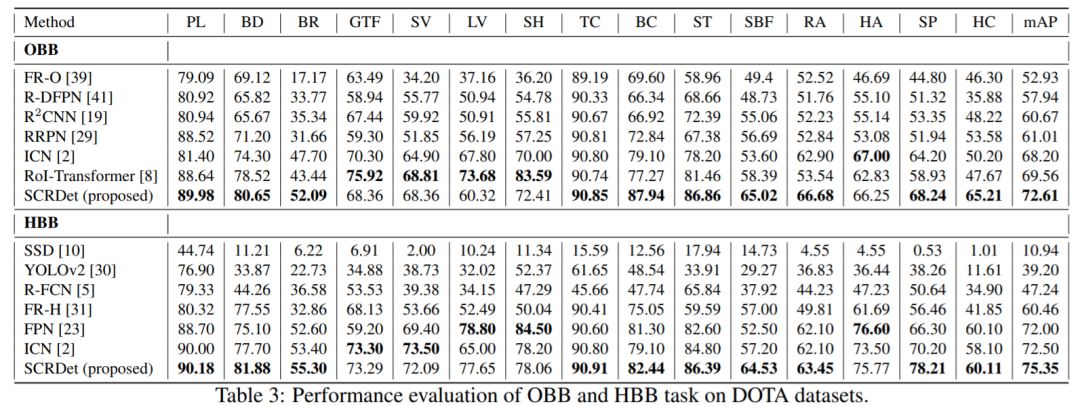
对比实验:
对于DOTA感兴趣的朋友,可以关注我的一个repo,这里面记录了关于DOTA的论文以及相关代码统计,如果没有统计到的也可以直接提issue,我会及时加上。
https://github.com/SJTU-Thinklab-Det/DOTA-DOAI
三、 总结
总的来说,这篇文章并不算是让我满意的文章,但也算是为遥感检测敲开CV大门做了一点小贡献,并特别感谢DOTA数据集为遥感进军CV领域做出的巨大贡献。我也会在之后陆续介绍我在遥感目标检测领域新的想法和研究成果。
重磅!CVer-目标检测微信交流群已成立
扫码添加CVer助手,可申请加入CVer-目标检测交流群。同时还可以申请加入大群和细分方向技术群,细分方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索等群。
一定要备注:研究方向+地点+学校/公司+昵称(如目标检测+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群

▲长按加群

▲长按关注我们
麻烦给我一个在看!



