CVPR 2018 | 华中科技大学提出多向文本检测方法:基于角定位与区域分割
选自arXiv
作者:Pengyuan Lyu等
机器之心编译
参与:Nurhachu Null、李泽南
在计算机视觉的应用场景里,对图像中的文本进行准确识别是重要而相对困难的任务。来自华中科技大学的研究者们近日提出了一种全新的多项文本检测方法,大幅提高了机器学习的识别准确度。该研究已被即将于 6 月 18 日在美国盐湖城举行的 CVPR 2018 大会接收。
简介
最近,由于现实世界应用(如产品搜索 [4],图像检索 [19],以及自动驾驶)需求的增长,从自然场景图像中提取文本信息的研究正变得越来越流行。场景文本检测(Scene text detection)在各种文本读取系统中起着重要的作用 [34, 10, 47, 5, 20, 13, 7, 25],它的目标是在自然图像中定位出文本。
由于外部因素和内部因素,场景文本检测具有一定的挑战性。外部因素源自环境,例如噪声、模糊和遮挡,它们也是一般目标检测中存在的主要问题。内部因素是由场景文本的属性和变化引起的。与一般目标检测相比,场景文本检测更加复杂,因为:1)场景文本可能以任意方向存在于自然图像中,因此边界框可能是旋转的矩形或者四边形;2)场景文本边界框的长宽比变化比较大;3)因为场景文本的形式可能是字符、单词或者文本行的形式,所以在定位边界的时候算法可能会发生混淆。

图 1. 顶行和底行中的图像分别是左上角、右上角、右下角和左下角的预测角点和位置敏感图。
在过去几年中,随着一般目标检测和语义分割的快速发展,场景文本检测得到了广泛的研究 [10, 5, 49, 20, 43, 52, 39, 42],并且在最近取得了明显的进展。基于一般目标检测和语义分割模型,几个精心设计的模型使得文本检测能够更加准确地进行。这些文本检测器可以被划分为两个分支。第一个分支以一般目标检测器(SSD [30],YOLO [37] 和 DenseBox [18])为基础,例如 TextBoxes [27],FCRN [14] 以及 EAST [53] 等,它们直接预测候选的边界框。子二个分支以语义分割为基础,例如 [52] 和 [50],它们生成分割映射,然后通过后处理生成最终的文本边界框。
与前面的方法不同,来自华中科技大学的研究人员结合了目标检测和语义分割的思想,并将它们以一种可替代的方式进行了应用。新研究的动机主要来源于两方面的观察:1)不管矩形的大小如何、长宽比如何、方向如何,它都可以由角点决定;2)区域分割图可以提供有效的文本位置信息。所以,我们可以首先检测文本的角点(左上角、右上角、右下角和左下角)(如图 1 所示),而不是直接检测文本边界框。此外,我们预测位置敏感分割图(如图 1 所示),而不是像 [52] 和 [50] 中提到的文本/非文本图。最后,我们再通过角点进行采样和分组,以生成候选边界框,并通过分割信息消除不合理的边框。新的方法的处理流程如图 2 所示:

图 2. 方法概览。给定一幅图像,网络通过角点检测和位置敏感语义分割输出角点。然后通过对角点进行采样和分组得到候选的边框。最后,通过分割图对候选边框进行打分,并使用非极大抑制(NMS)对边框进行抑制。
新方法的关键优势如下:1)因为我们是通过对角点进行采样和分组来检测场景文本的,所以新的方法能够处理任意方向的文本;2)因为我们检测的是角点,而不是边界框,所以新的方法可以自然地避免边框比较大的问题;3)因为使用了位置敏感分割,所以无论是字符、单词,还是文本行,我们都能够较好地分割文本实例;4)在新方法中,候选边框的边界是由角点决定的。
研究人员在来自公共基准测试集上的水平文本、定向文本、长定向文本以及多语言文本中验证了该方法的有效性。结果显示新提出的算法在准确率和速度方面均有优势。具体而言,新方法在 ICDAR2015 [22] 上的 F-Measures 分别为 84.3 %、81.5 % 和 72.4 %,这显著优于现有的方法。此外,新方法在效率上也很有竞争力。它每秒可以处理 10.4 张以上的图像 ( 512×512 )。
该研究的主要贡献有四个方面:
(1)提出了一种融合目标检测和分割思想的场景文本检测器,这个场景文本检测器可以以端到端的方式进行训练和测试。
( 2 ) 在位置敏感 ROI 池化 [ 9] 的基础上,提出了一种旋转的位置敏感 ROI 平均池化层,可以处理任意方向的请求。
( 3 ) 新提出的方法可以同时处理多方向场景文本中的诸多挑战(如旋转、宽高比变化、非常闭合的实例)。
( 4 ) 新方法在精度和效率上均取得了较好或有竞争力的结果。
网络结构
新方法所用的网络全部是卷积神经网络,它扮演着特征提取器、角检测和位置敏感分割的角色。网络结构如图 3 所示。给定一张图片,网络会生成候选的角点和分割图。

图 3. 网络结构。网络包含三个部分:主干网络,角点检测器和位置敏感图预测器。主干网络来自于 DSSD [ 11 ]。角检测器是基于多特征层(紫色的模块)建立的。位置敏感分割预测器与角检测器共享了一些特征(紫色的模块)。

图 6. 检测结果的一些示例。从左到右依次是: ICDAR2015, ICDAR2013, MSRA-TD500, MLT, COCO-Text。
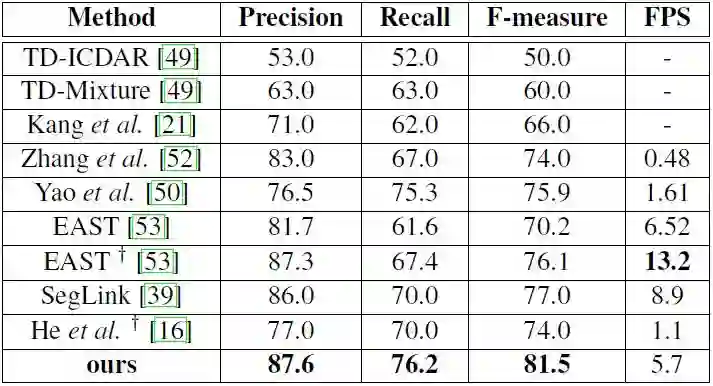
表 4. MSRA-TD500 上的测试结果。有†表示的模型不基于 VGG16。
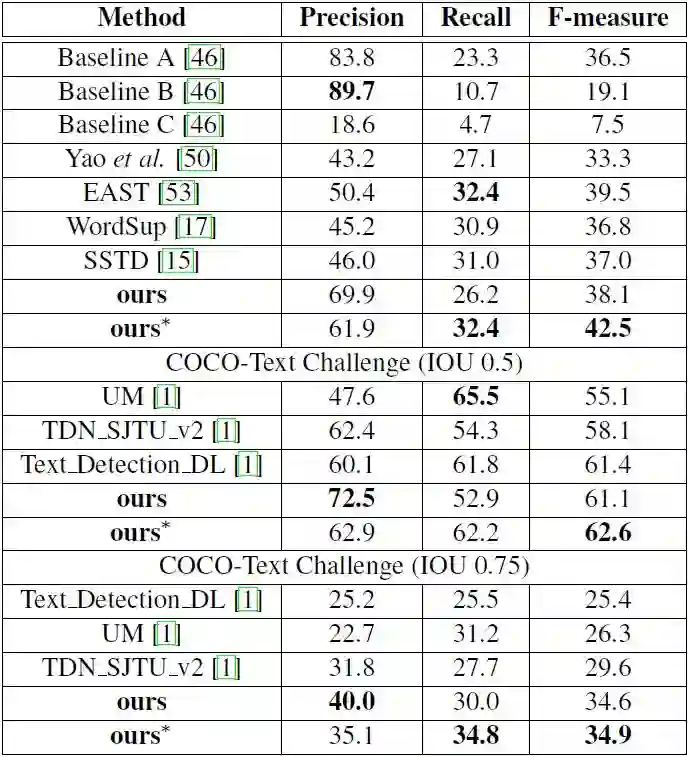
表 6. COCO-Text 上的测试结果。∗代表多尺度。
论文:Multi-Oriented Scene Text Detection via Corner Localization and Region Segmentation

论文链接:https://arxiv.org/abs/1802.08948
摘要:此前基于深度学习的场景文本检测方法可以被粗略地分为两大类别。第一类将场景文本识别视作一种一般的目标检测问题,这类方法遵循一般目标检测的范式,通过回归文本框来定位场景文本,但是会受到任意方向和较大变化的长宽比的场景文本的困扰。第二类将文本区域进行直接分割,但是大都需要复杂的后处理过程。在这篇论文中,我们提出了一种能将这两类方法的思想进行结合,同时能够避免它们各自弱点的新方法。我们提出了通过定位文本边界框的角点,并在相对位置分割文本区域来检测场景文本的方法。在推理阶段,候选边框通过对角点的采样和分组得到,候选边框进一步通过分割图进行打分,然后使用非极大值抑制(NMS)方法对边框进行抑制。与之前的方法相比,我们的方法能够自然地处理长定向文本,并且不需要复杂的后处理过程。在 ICDAR2013、ICDAR2015、MSRA-TD500、MLT 和 COCO-Text 上的实验证明我们提出的方法能够在准确率和效率方面同时达到更好或者更具竞争力的结果。基于 VGG16,我们的方法在 ICDAR2015 上实现了 84.3% 的 F-measure,在 MSRA-TD500 上达到了 81.5% 的 F-measure。

本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):hr@jiqizhixin.com
投稿或寻求报道:editor@jiqizhixin.com
广告&商务合作:bd@jiqizhixin.com



