基于深度学习的图像目标检测(下)
依然要感激如此美丽的封面图片。 在“基于深度学习的图像目标检测(上)”里面, 我们详细介绍了R-CNN走到端到端模型的Faster R-CNN的进化流程。 这里, 我们介绍, 后续如何变得更快、更强!
前言
天下武功唯快不破!
所以在如何让检测更快? 主要有两种思路:
1. 把好的方法改进的更快!
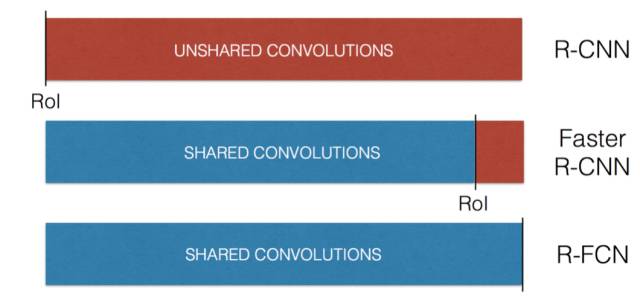
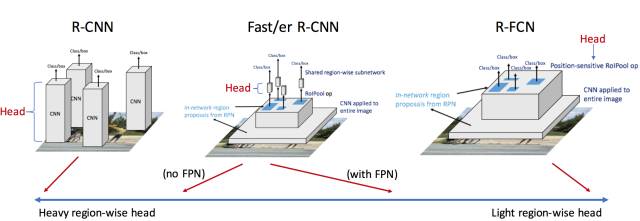
前面我们提到了从R-CNN到Faster R-CNN主要的技术思想就是避免特征计算浪费。 所以要把ConvNet特征计算前移,只做一次计算。 而把区域操作后移。 我们也提到Faster R-CNN在RoI之后还有部分ConvNet的计算。 有没有可能把ROI之上的计算进一步前移? R-FCN(Region-based Fully Convolutional Networks) 基于这个思路,做到了,所以更快, 某种意义上,是Fatest R-CNN。
R-FCN
2. 把快的方法,改进的更好!
前面我们谈到overfeat的效果一般, 但是overfeat基于滑动窗口和回归思想的速度很快。 从效果上来说, overfeat 的效果一般, 对于重叠情况很多不能识别的情况。 如何将基于回归的思想,做到逼近区域推荐的效果?YOLO把分而治之和IoU的思想集成进来了。 而SSD把多尺度Anchor Box的思想集成进来了。
除了快还有什么?当然是做优做强
Faster R-NN有三大主要部件, RPN 做区域推荐, RoI Pooling类似特征Pyramid,改善极大极小重叠, 分类和Box回归的Log 加 Smoothed L1 损失, 针对定位修正。 如何要做优做强?
能否比RPN做的更优?
前面我们提到RPN能够达到Selective Search的效果, 那么假如还要更好, 怎么能够做到?AttractioNet利用了NMS(non-maxima suppression)效果。 AttentionNet利用了弱注意力集中的机制。
能否比RoI Pooling做的更优?
前面我们提到RoI Pooling能够做到和HoG Pyramid和DPM空间限制类似的SPM的效果, 那么加入还要更好, 怎么能够做到? ION(Inside-Outside Net)提出了四方向上下文的思想, FPN提出了特征Pyramid网络。
能否比RoI Pooling做的更强?
前面我们提到RoI Pooling是建立在RoI基础上的, 对应的区域推荐, 如何进一步对齐到像素点? Mask R-CNN提出了RoI Align的思想。 在误差计算中,除了分类, Box回归基础上再加入像素点Mask Branch距离的思想。
那么, 什么是FCN(Fully Convolutional Networks), IoU, NMS, Weak Attention Narrowing, ION, FPN, RoI Align 和 Mask Branch思想?理解了这些, 你对厦门这个图,就不再陌生!

下面, 开启下半场的路程!
R-FCN
前面我们提到, Faster R-CNN打通前后端成为端到端的模型的同时, ConvNet模型也换成了VGG-16的模型。 但是在GoogLeNet和ResNet网络结构上, 全连接FC层就只有一层了, 最后一层,为Softmax分类服务了。
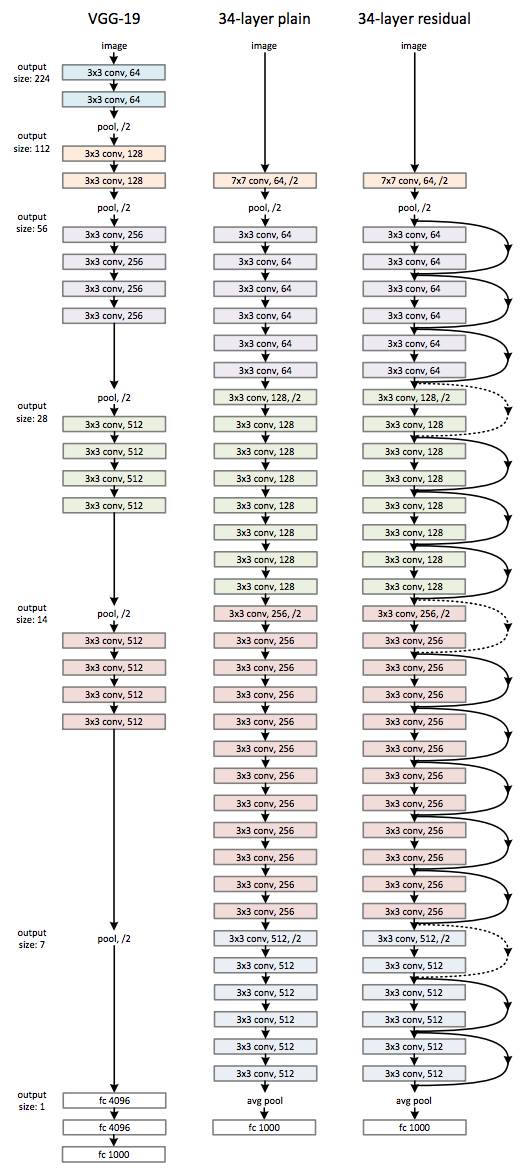
那么, 如果要把GoogLeNet和ResNet应用到Faster R-CNN中去,就面临一个现象,去掉最后一层FC层, 因为那是用来做分类的。 需要换到新的尾部网络, 能够兼容分类和Box回归。
这样, 我们再来看RoI Pooling的使用, 那么RoI Pooling后面的FC层也要换成卷积层。 这样, 卷积层就被RoI Pooling层隔断了。 而且这种隔断使得RoI Pooling后面的ConvNet重复计算了。
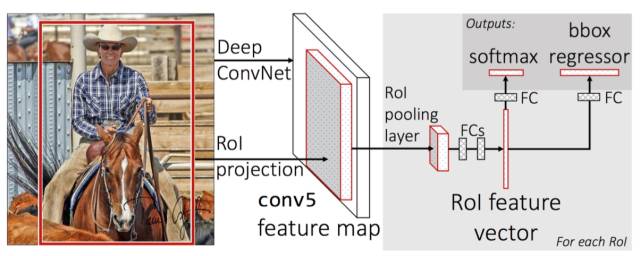
一个问题, 能不能直接把后面FCs变成ResNet之后的ConvNet直接丢弃? 不行, 这样的效果会打折扣, 为什么? 我们在Fast R-CNN继承SPPNet的SPM技术, 演绎出RoI Pooling的时候讲了,RoI Pooling只是相当于最细分的区域固定, 那么粗粒度的部分, 可以由后续的多层FCs来达到类似的效果。 如果去掉, 就少了金字塔结构了,或者少了深度了。
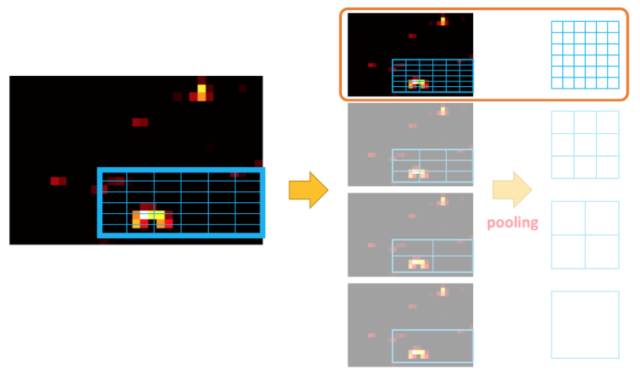
那么, 如何把RoI后面的卷积计算也移到前面去?就是R-FCN解决的问题!一方面要保留空间限制, 另一方面要有一定特征层次。 R-FCN提出了Position-Sensitive RoI Pooling。
Position-Sensitive RoI Pooling的思想, 正式将位置并行起来, 是一种结合了空间信息的的注意力机制。 每个小的子框数据来源一个和特点位置绑定的ConvNet特征层。
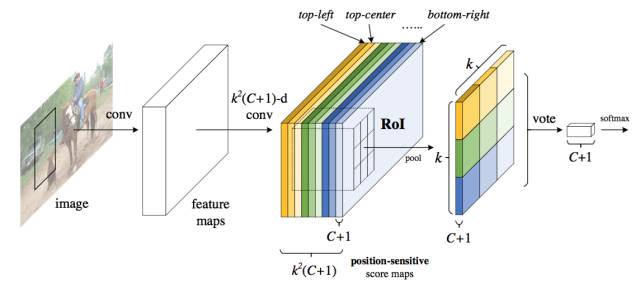
一旦和位置绑定了, 那么特征计算, 就从以前的中心点, 变成了一系列从上下左右的不同子框去看的特征图。 那么再把这些组合起来。 即暗含了不同空间信息。类别的说,就是你先上下左右的看这个山峰, 回头把看的拼接起来, 判断山峰有没有认错。 选择好不同位子的特征,再整合起来, 得到在不同位子点确认的特征, 再做Pooling, 通过Pooling进行投票。
转自:AI2ML人工智能to机器学习
完整内容请点击“阅读原文”


