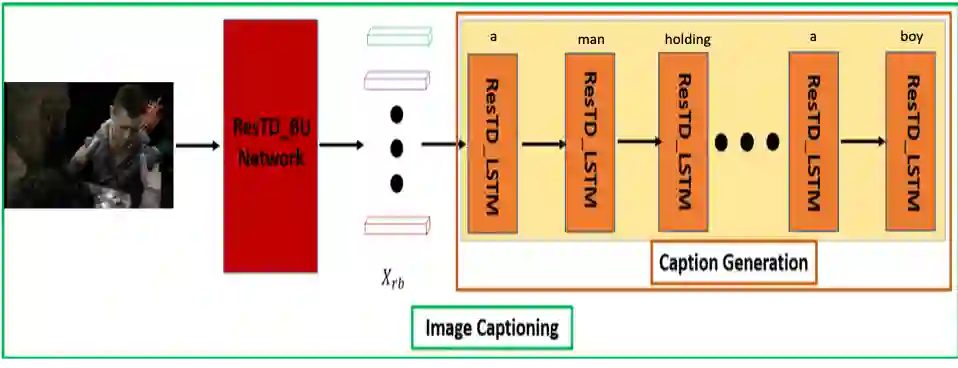
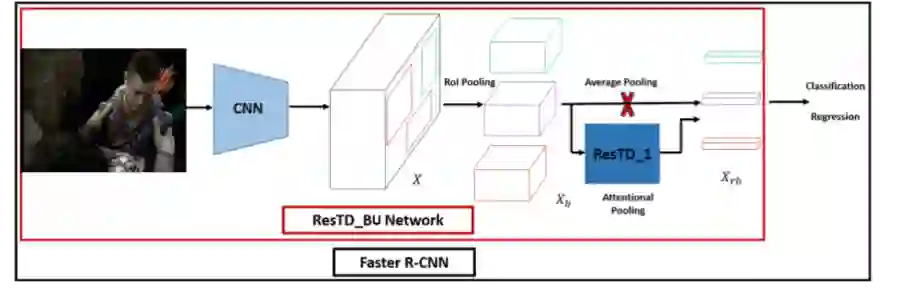
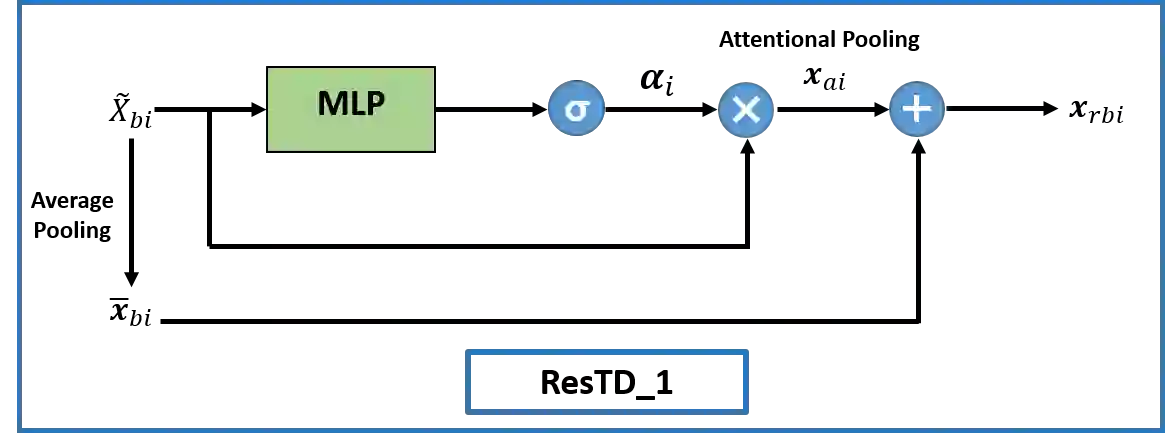
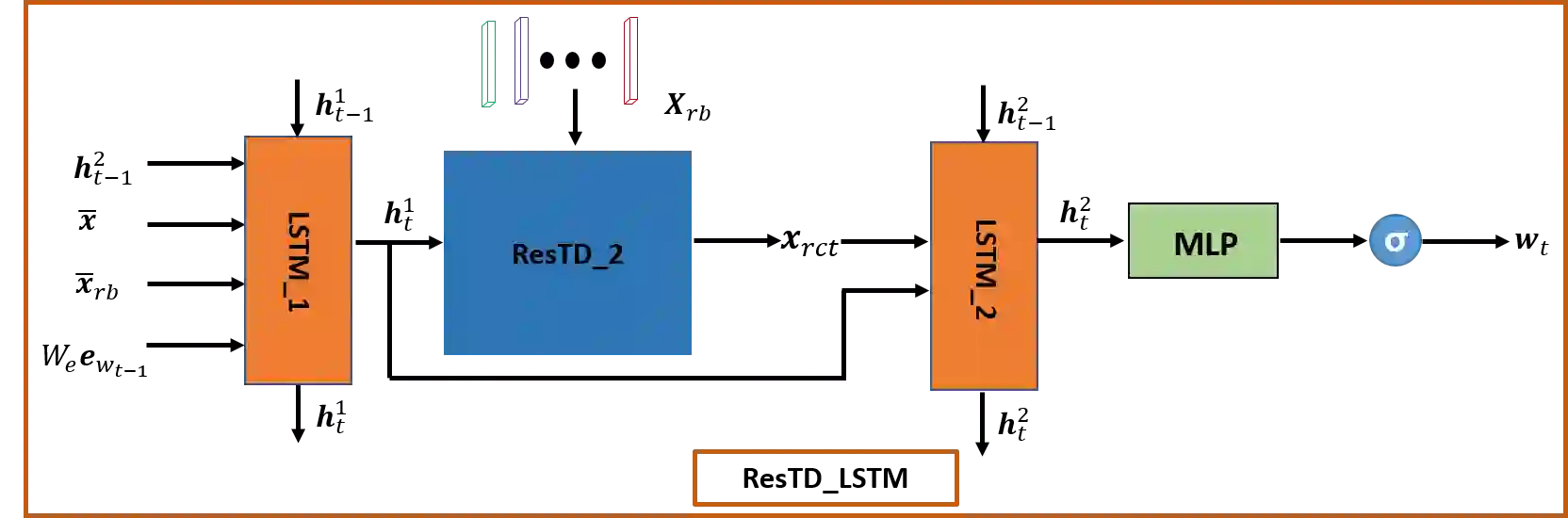
Image captioning has attracted considerable attention in recent years. However, little work has been done for game image captioning which has some unique characteristics and requirements. In this work we propose a novel game image captioning model which integrates bottom-up attention with a new multi-level residual top-down attention mechanism. Firstly, a lower-level residual top-down attention network is added to the Faster R-CNN based bottom-up attention network to address the problem that the latter may lose important spatial information when extracting regional features. Secondly, an upper-level residual top-down attention network is implemented in the caption generation network to better fuse the extracted regional features for subsequent caption prediction. We create two game datasets to evaluate the proposed model. Extensive experiments show that our proposed model outperforms existing baseline models.
翻译:图像字幕近年来引起了相当大的注意。 但是,在游戏图像字幕方面几乎没有做多少工作,这具有一些独特的特点和要求。 在这项工作中,我们提出了一个新的游戏图像字幕模型,将自下而上的关注与一个新的多层次剩余自上而下关注机制相结合。 首先,在快速R-CNN基于自下而上的自上关注网络中增加了一个较低层次的剩余自上而下关注网络,以解决后者在提取区域特征时可能失去重要空间信息的问题。 其次,在字幕生成网络中安装了一个上层剩余自上而下关注网络,以便更好地将提取的区域特征结合到随后的字幕预测中。我们创建了两个游戏数据集来评估拟议的模型。广泛的实验表明,我们提议的模型优于现有基线模型。