计算机安全深度学习的白盒解释方法

随着深度学习在计算机安全领域越来越受到重视,不同类型的神经网络已被集成到安全系统中,以完成恶意软件检测,二进制分析,以及漏洞发现等多种任务。然而,神经网络的预测结果难以得到解释,例如难以确定输入数据的哪些特征对预测结果产生贡献,这一定程度上影响到了深度学习方法的应用。已有研究人员通过近似神经网络的决策函数来确定不同特征对预测结果的贡献,如LEMNA方法,并已在不同的安全应用中取得了良好的效果。该方法是一种忽略神经网络结构的黑盒方法,因此也损失了部分能够用来解释预测结果的重要信息。通常情况下,预测和解释都是基于同一个神经网络,因此神经网络的结构信息通常是已知的。在此基础上,可以尝试使用白盒解释方法来理解预测结果,并将这类方法应用于计算机安全领域。
本文介绍了一项深入研究白盒解释方法在计算机安全深度学习中应用的工作,这一工作来自于2020年In Proc. of Euro S&P的一篇论文。
在解释神经网络决策的过程中,需要考虑的两个重要方面分别是神经网络架构和解释策略。在安全领域,多层感知器(MLP)、卷积神经网络(CNN)和递归神经网络(RNN)三种架构比较流行。MLP已成功应用于各种安全问题,如入侵和恶意软件检测。在卷积神经网络中,由于卷积层中的神经元只接收来自前一层的局部邻域的输入,这些相邻区域重叠并产生感受野,为识别图像和数据中的空间结构提供了强大的能力,因此CNN已被用于直接从原始Dalvik字节码检测Android恶意软件。RNN是一个具有循环结构的神经网络,即部分神经元连接成一个回路,能够对数据序列进行操作,已成功应用于识别本机程序代码中的功能或发现软件中的漏洞。
另一个重要的方面是解释策略的选择。在给定一个神经网络N、一个输入向量x = (x1,…, xd)和一个神经网络的预测结果fN(x)= y的情况下,解释方法的目标是理解为什么神经网络的预测值为标签y。这种解释通常用向量r=(r1,…,rd)表示,它描述了x的不同维度与预测结果的相关性,这一向量可以与输入叠加,从而突出显示与预测结果相关的特征。
大多数解释方法可以分为黑盒和白盒两类,白盒解释方法假设神经网络的所有参数都是已知的,可以用来解释神经网络的输出结果。因此,这类方法不依赖于近似,可以直接根据神经网络的结构计算出函数fN的解释。例如,Gradients方法[2]使用简单的梯度来表示相关性r,
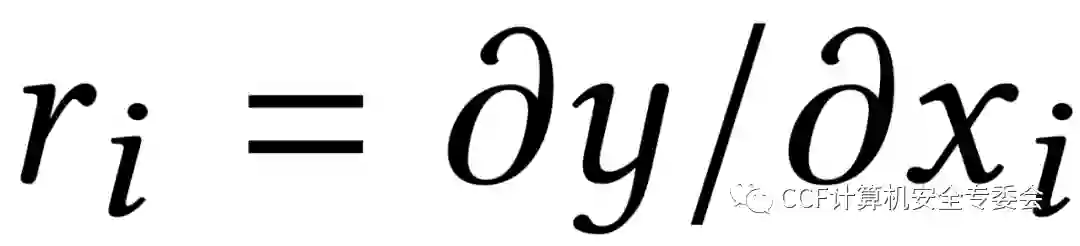
Integrated Gradients (IG) 方法[3]则在此基础上引入了基线(比如一个零向量),计算从x到基线的最短距离,随后计算xi的梯度在路径上的累积值,作为xi的相关性,
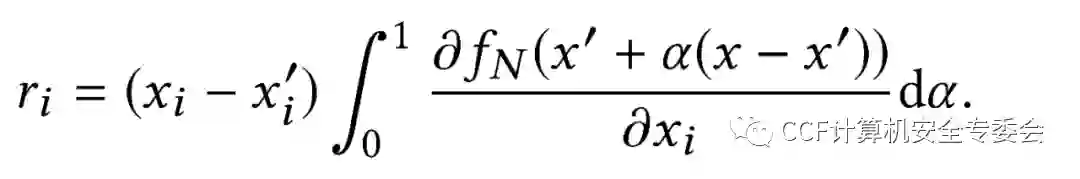
分层关联传播 (Layer-wise Relevance Propagation, LRP) [4]则是通过在神经网络中执行反向传播来确定预测的相关性,从输出层开始执行计算,直到到达输入层。LRP的核心思想是使用守恒性质,使得相关性的加和在向后传播的过程中保持不变,
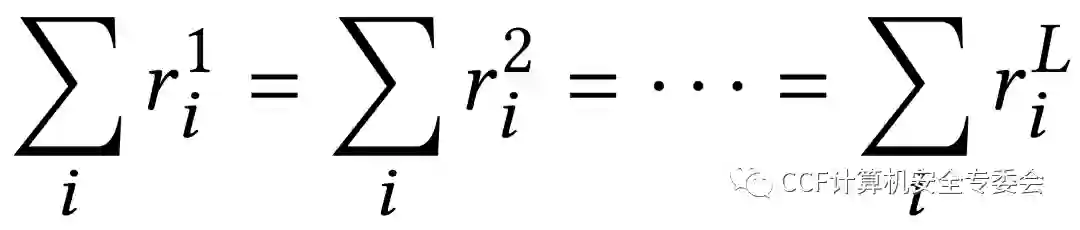
上述三种方法均支持解释前馈、卷积和递归神经网络的决策。
黑盒解释方法假设研究人员不了解神经网络的结构及参数,因此需要依赖于对函数fN的近似来估计x对预测值的贡献。作者在论文中使用的是LIME,KernelSHAP和LEMNA三种黑盒解释方法,前两种方法均希望通过创建x的一系列扰动l来近似决策函数fN,这一扰动是通过将向量x中的元素随机设置为0实现的。LIME通过加权线性回归模型逼近决策边界,
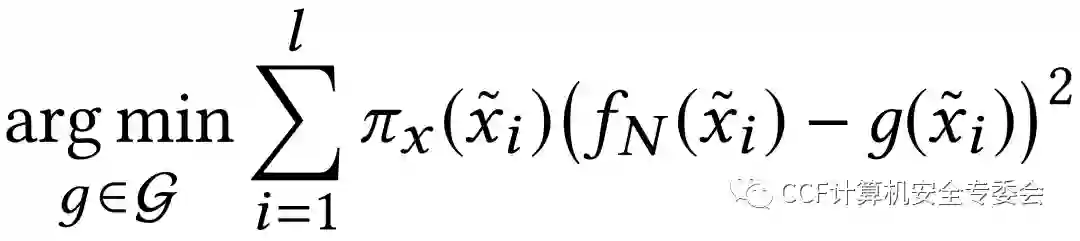
KernelSHAP方法是在LIME理论基础上应用了博弈论的概念,而LEMNA方法则使用混合回归模型进行近似。
作者在论文中使用了四个深度学习安全系统来测试白盒和黑盒解释方法的性能,包括两个Android恶意软件检测系统:Drebin+是用于识别Android恶意软件的多层感知器、DAMD可以识别恶意Android应用程序;一个恶意PDF检测系统(Mimicus+)和一个安全漏洞预测的系统(VulDeePecker)。为了验证代码实现的正确性,以上四种安全系统均在相应的原始数据集上进行了训练,所得结果均与文献报道保持一致。

表1. 测试使用的安全系统。
此外,作者引入了Brute-force方法作为本实验的基线。该方法通过设置xi为零,测量softmax概率的差异来计算相关度ri,
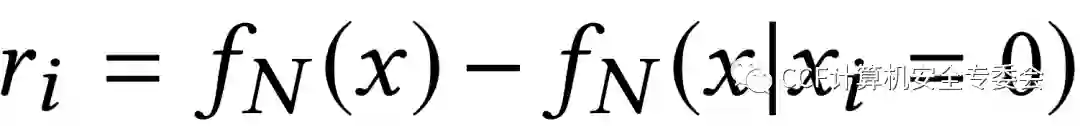
为了定量地评估和比较解释方法的性能,论文中引入了四个指标:
为了定量的衡量解释方法的简洁性,论文中计算了平均剩余精度(ARA)来表示移除特征对分类结果的影响。ARA的计算方法是从样本中去除k个最相关的特征,然后再次运行神经网络进行预测。连续删除相关特征后,由于神经网络用于做出正确预测的信息较少,因此ARA将不断降低。解释方法给出的结果简洁性越高,则ARA下降得越快。
通过将相关向量除以其绝对值的最大值可以对所有方法得到的解释进行归一化,以便每个样本的值介于−1和1之间。因此,稀疏性的要求在于期望解释方法只为少数特征分配高相关性系数,并将大多数特征的相关性设置为0。通过绘制相关性数值的标准化直方图,并计算零周围的质量(MAZ),可以定量的表征解释结果的稀疏性。
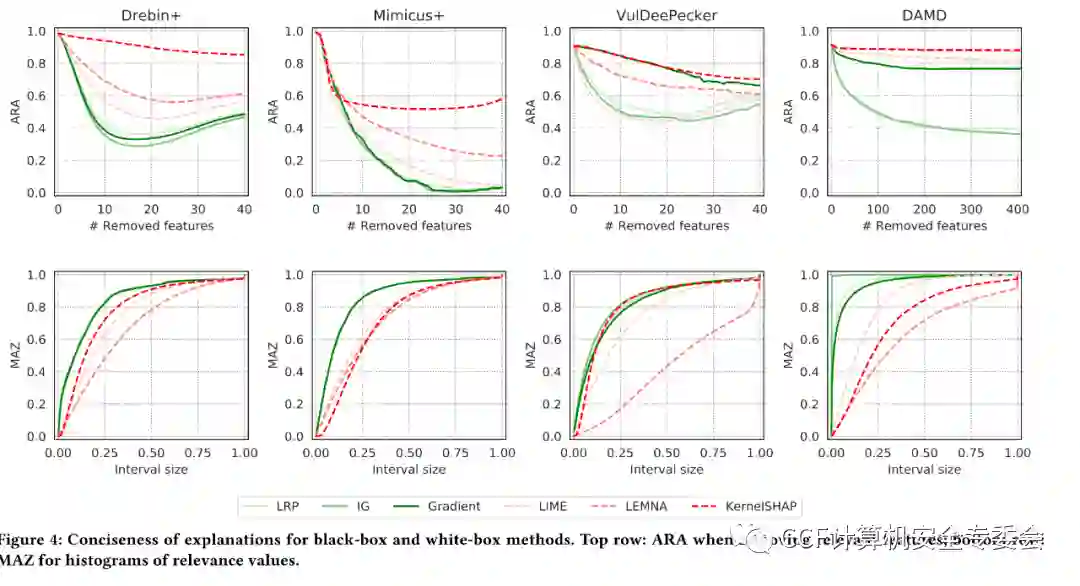
图1. 白盒和黑盒解释方法的简洁性和稀疏性。第一行的图表示移除相关特征后的ARA,第二行则表示相关性数值的标准化直方图的MAZ。
如图1所示,通过计算曲线下面积(AUC)可知,白盒解释方法的简洁性平均比黑盒方法高30%,且白盒方法的效果总是接近甚至优于Brute-force方法。在稀疏性方面,白盒解释方法的稀疏度比黑盒方法高19%,白盒方法为更多特征分配了接近于零的值,而黑盒解释方法给出的特征的相关性值在零附近的分布更广,从而使MAZ的斜率更小,接近于0。此外,该论文也对解释方法的完整性和效率进行了评估。白盒方法在四个安全系统中均适用,而黑盒方法则存在受到限制和无法给出有意义结果的情况。白盒方法比Brute-force方法快得多,黑盒则与之效率较为接近。计算四个指标的平均值可以系统性地比较上述6种方法(表2),可知只有白盒解释方法在所有的指标中都被评为了“强”的等级。
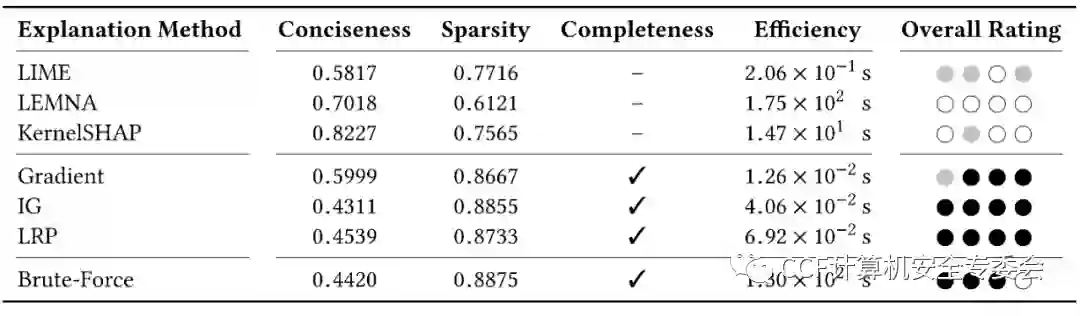
表2. 解释方法得到的四个指标的平均结果。最后一列总结了由三个级别组成的评级,圆圈的颜色为黑、灰和白,分别表示“强”、“中”和“弱”的等级。
为了可视化解释的相关向量,图表中均将支持决策的特征标记为绿色,与决策相矛盾的特征标记为红色,颜色的亮度则反映了特征的重要性。图2中展示了使用白盒和黑盒解释方法对深度学习系统VulDeePecker决策的解释。白盒解释方法提供了相关特征的细粒度表示,而黑盒方法则产生了不清晰的解释,难以帮助研究人员理解神经网络是如何做出决策的。然而,使用上述两种方法均会将与安全漏洞无关的标点符号突出展示出来,如函数调用后的分号或括号。在研究的四个深度学习系统中,均发现了这类与安全无关但对预测结果有较大贡献的特征。因此,作者认为解释方法需要与深度学习的安全系统相结合,不仅可以用于理解神经网络生成的决策,还可以识别和消除学习过程中的干扰因素。

图2. 使用白盒(上)和黑盒(下)方法对VulDeePecker系统的决策进行解释。
根据表2的结果可知,在白盒和黑盒解释方法中,效果最好的分别是IG和LIME。以IG和LIME对Mimicus+预测结果的解释为例,可以发现恶意软件的分类中主要包含count_javascript和count_js这两个特征,它们都代表文档中Javascript对象标记的数量(表3)。不同之处在于,IG将更多特征的相关性设置为接近零,仅标记具有强相关性的少数特征,而LIME将相关性分布在更多的特征上。这两种方法识别出的JavaScript的较强影响是有意义的,因为JavaScript在恶意PDF文档中常被使用。然而,两种解释方法在恶意类别中还找到了一些不相关的特征,例如,count_trailer和count_box_letter等特征与安全性几乎没有关系,这一结果也体现了神经网络学习过程中干扰因素的影响。

表3. 使用IG和LIME为Mimicus+预测的恶意PDF文档进行解释。
在良性PDF文档类别中,作者发现count_font(字体对象标记计数),producer_mismatch和title_num(标题中数字字符的数目)均排在两种解释方法给出的前几个特征中,而这些特征很少出现在恶意样本中(表4)。此外,LIME还突出显示了pos_eof_min(最后一个eof标记的标准化位置)特征,然而这一特征在良性和恶意文档中均较为常见。IG则将title_uc(title中大写字母的计数)特征排在了前列,这一特征在良性样本中更常见。基于以上观察结果,恶意文档的作者可以通过在文档中使用字体对象标记,在姓名和文档标题中使用数字、大写字母,或避免使用JavaScript,从而轻松规避Mimicus+的检测。
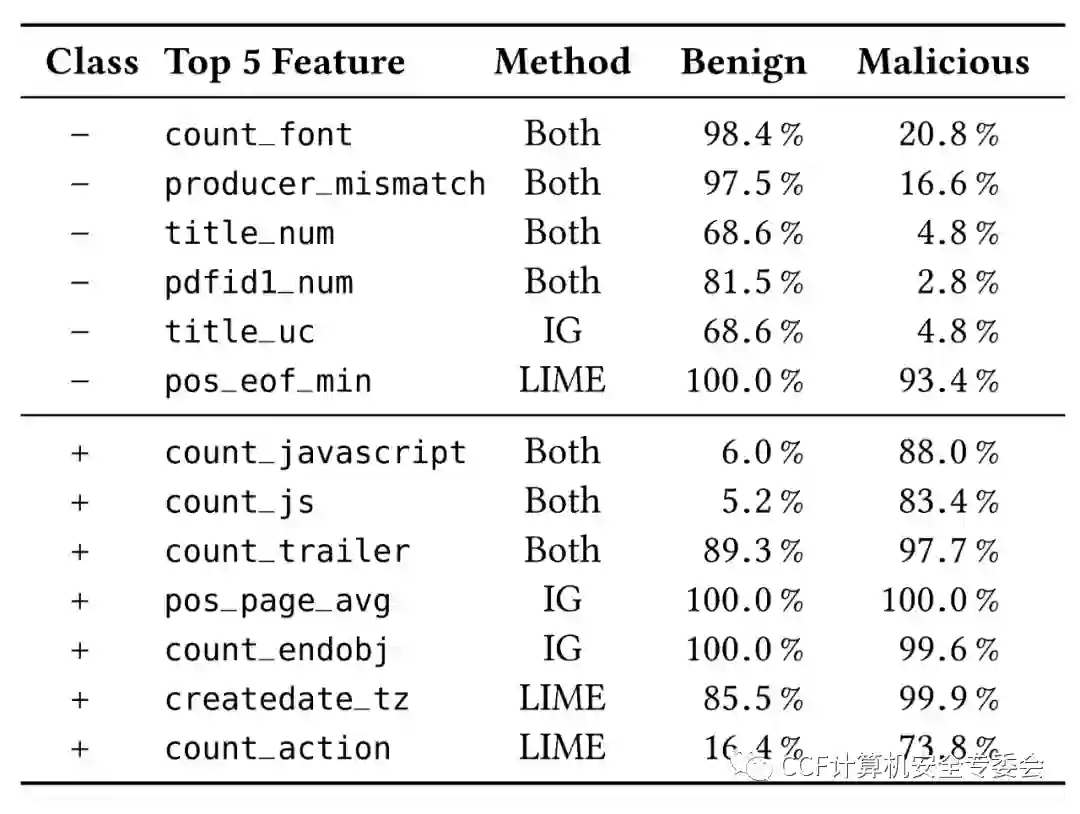
表4. 解释方法筛选出Mimicus+数据集中良性和恶意类中的最显著特征。
深度学习在安全领域的广泛应用使得对决策结果的解释变得至关重要。根据是否掌握神经网络的架构和参数,可以选择使用白盒或者黑盒的解释方法来理解系统的决策。该工作的研究结果表明,在可以获取神经网络的架构和参数的条件下,白盒解释方法可以高效地生成更加简洁、完整和有效的结果,与黑盒解释方法相比具有显著优势。
根据解释方法筛选出的特征通常可以追溯到特定的安全上下文,从而有助于评估神经网络的预测效果,并深入了解其决策过程。此外,在论文测试的所有系统中,应用解释方法均会识别出对预测有实质性贡献但与安全任务完全无关的特征,这是深度学习在安全领域的应用中普遍存在的问题。虽然这一问题可能来源于底层数据的特性,但很明显,目前所使用的神经网络倾向于应用数据,而不是解决底层任务。因此,有效的解释方法需要成为深度学习系统中的一个组成部分,以便识别和消除学习过程中的干扰因素。
参考文献
[1] Alexander Warnecke, Daniel Arp, Christian Wressnegger,and Konrad Rieck. Don’t paint it black: White-box explanations for deeplearning in computer security. In Proc.of Euro S&P, 2020.
[2] K. Simonyan, A. Vedaldi, and A. Zisserman. Deep insideconvolutional networks: Visualising image classification models and saliencymaps. In Proc. of the International Conference on Learning Representations(ICLR), 2014.
[3] M. Sundararajan, A. Taly, and Q. Yan. Axiomatic attributionfor deep networks. In Proceedings of the 34th International Conference onMachine Learning, pages 3319–3328, 2017.
[4] S. Bach, A. Binder, G. Montavon, F. Klauschen, K.-R. Müller,and W. Samek. On pixel-wise explanations for non-linear classifier decisions bylayer-wise relevance propagation. PLoS ONE, 10(7), July 2015.
作者:绿盟科技天枢实验室
天枢实验室聚焦安全数据、AI攻防等方面研究,以期在“数据智能”领域获得突破。



