北大张志华:机器学习就是现代统计学

大数据文摘出品
内容来源:智源论坛
数学最重要的魅力在于帮助我们提出解决问题的思路或途径。
而机器学习在一定程度上正是数学和工程的完美结合,毕竟用数学里面的概率论、随机分析等工具研究AI早已不是什么新鲜事情。例如机器学习的四个基本原则性的问题,即泛化性、稳定性、可计算性和可解释性就可以用数学工程手段来解决。
在5月 9日的北京智源人工智能研究院主办的“智源论坛——人工智能的数理基础”系列报告中,北京⼤学的张志华教授对机器学习和数学工程的内在关系进行了阐述。在报告中,他提到:统计为求解问题提供了数据驱动的建模途径;概率论、随机分析、微分方程、微分流形等工具可以引入来研究 AI 的数学机理等等。
除此之外,张志华教授还回顾了机器学习发展的⼏个重要阶段,以及重点强调机器学习和人工智能之间并不能画等号,毕竟机器学习实际上是研究算法的学科,而人工智能志在模拟人的思维和行为。
在回答现成观众问题的时候,其也提到机器学习就是统计学的一个分支,机器学习比统计学更接地气。
以下张志华教授的演讲速记,文摘菌做了有删改的整理,请欣赏~
机器学习发展现状的认识
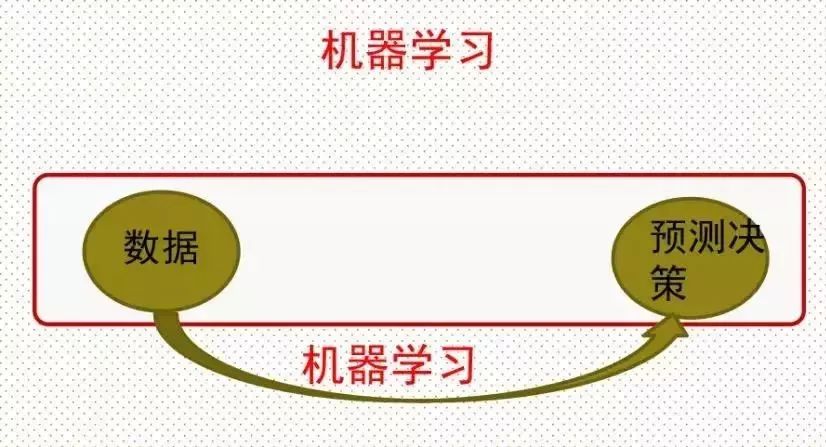
机器学习与人工智能有着本质上的不同,前者志不在模拟人的思维和行为,主要是想通过经验和交互的方式改善性能,是基于规则的学习。机器学习实际上是研究算法的学科,算法是基于数据型算法,然后反馈到数据中去。 可以简单地把机器学习的过程看作这样一个思路,然后可以基于此看看机器学习发展的历程:
传统方法:基于规则学习
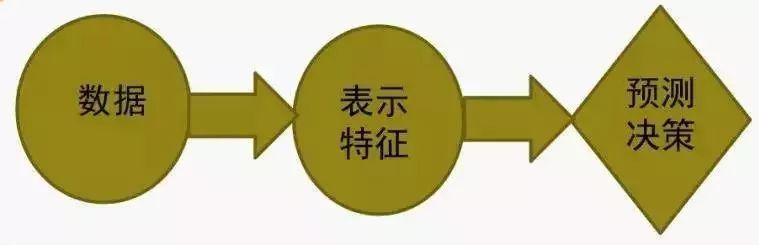
第一个历程是基于规则的学习,它的目的就是为了规则,有规则它就可以做预测。但是重点不是怎么形成规则,而是数据到表示,即通过认知的手段,把人对数据的认识过程,用计算机记录下来。从而成一种形式化的方式,自然而然就有一种规则和逻辑的方式去做预测。它主要代表有两个,一个是专家系统,包括知识库和推理基,其中重点就是知识库。另外一个是句法模式识别,模式的目的也是怎么样把一个对象通过一种形式化的方式表示出来。
但这一阶段也暴露出一些问题,其一便是基于规则学习的方法虽然对于浅层推理比较有效,但遇上深层推理需求,如果形成规则过多,在其中搜索就容易出现前面的分享提到过的维数灾难问题。
为了解决问题,一个用一个强大的非线性学习模型来弱化数据到表示过程的作用,基于这样的理论,机器学习发展至第二个阶段。
统计机器学习黄金发展的十年
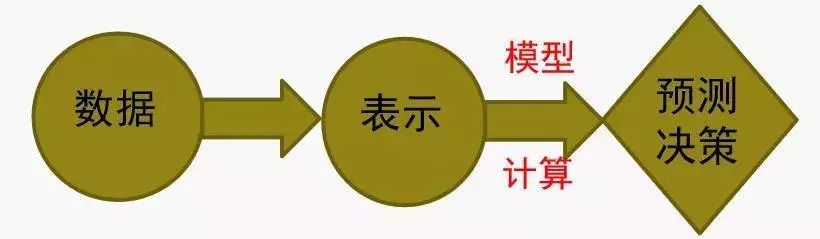
第二阶段是90年代中期到2005年左右十年的时间。在这一阶段为了解决维数灾难,出现了一个数论:即基于规则的方式,环成一个非线性的一种模型,或者用计算的手段运作模型,然后反过来可以弱化数据到表示的过程。
这一阶段的神经网络(80 年代就已经出现神经网络模型)则相对趋于比较低落的时期,表现平平,发展遇冷。主要原因在于时期的机器学习方法比神经网络要更为简单,性能也要更好,属性性质相对完美,自然而然地就取代了神经网络。
但随着统计方法发展到一定阶段,大家发现“数据到表示”这件事情还是绕不过去。而应对这一问题地一个简单的思路就是通过学习的途径来求解表示问题,从而弱化研究者对于领域背景高度掌握的要求,也就是通过一个自动化的方式来解决这一问题。
基于深度表示的学习
大模型+大数据+大计算使得这种思路变得可行,机器学习也进入了第三阶段。AlexNet 网络的提出在后来为问题带来了突破性进展,很多做计算机视觉的人在网络方面不停跟进,这些发展主要是基于视觉的。
那么在机器翻译、自然语言处理,自然而然也想到深度学习既然可以解决视觉问题,当然就可以把深度学习拿到机器学习来,所以现在在机器学习里面它的主要的模型也是基于深度。虽然模型可能不是卷积神经网络,但是核心确是LSTM这种东西。但是不管怎么样,相对于机器学习,自然语言处理深度学习,在自然语言处理它的效果或者它的作用远远没有那么好。
在上述时期,用深度学习它的目的还不是为了表示,主要是为了什么?还是为了非线性的拟合,在自然语言处理,个人理解目前为止还没有找到一种非常有效的,像卷积神经网络有效表示图像的网络,所以导致自然语言处理没有像图像那么强大。
那这整个过程,知道都是在一个有监督的方式里面去做的,本质上就是把数据到表示用一个模型和计算的方式做。而表示到预测、决策也是通过模型计算的,整个可以看到从数据到预测是端到端的优化学习过程。
深度学习目前现状:无监督问题突出
深度学习发展到现在,主要讲是有监督的学习,但是现在很多问题是无监督的,就是无监督的问题远远比有监督的问题要多,而且要复杂。那么一个简单的思想就是要把无监督的问题要形成与有监督类似的学习的过程,有一个优化的过程,用机器学习的方法解决事情,在统计里面,现在假设X要生成它,那么如果X是连续的,可以假设X是高斯,但是如果X来自高斯假设很强,但是可以说X是来自什么?是一个高斯混合体,如果X是一个连续的向量,那它总是可以用一个高斯混合体去逼近它,是没有任何问题的。
但是时候发现X是一个抽象的数学意识,并没有具体的物理意义,那么自然神经网络这些技术能不能对一个图像进行生成了,对语言进行生成,而不是对数学意义上的X去生成。现在发展比如有一个生成对抗网络,它就是解决这样的问题,它的目的不是为了生成一个抽象数学意义上的X,是生成一个真正的图像或者语言,那么它的框架实际上就是怎么样形成一个优化问题。
强化学习目前的复兴是因为深度学习
另一个发展方向是强化学习,强化学习是什么呢?它利用规则与环境交互或者奖赏,然后形成一个学习优化问题,形成一个优化问题。
对于强化学习,不是最近才发明出来的。其主要的数学手段是马尔可夫决策过程,它通过马尔可夫决策过程去描述问题,描述问题之后要去解问题,发现问题最优解,最后把它定成贝尔曼方程,那么解贝尔曼方程的话发现是可以用不动点定理来描述贝尔曼方程。那么有了不动点定理支撑,现在主要是有两个思路,第一个思路是基于Value,也就是用Value迭代找到最优值。另外一种就是Polic迭代,因为本质上不是找Value,是找Polic,所以就直接在Polic方面去做迭代。
现在很多实际问题实际上对环境是不会已知的,也就是说对卷积概率是不会知道的。这时候发展就是一个所谓的Q-Learning,实际上Q-Learning定义了一个新的函数叫Q函数。那么在Q-Learning基础上,就发展出来深度的Q网络,目前现在主要做的比如像Polic的梯度方法,这是强化学习或者深度强化学习目前发展的一个主要结点。
机器学习的技术路线
机器学习的技术路线
机器学习有三个问题。一个是有监督、无监督和强化学习。原来认为机器学习是统计的分支,现在认为机器学习就是现代统计学。机器学习和统计还有微妙的关系,机器学习是分类问题,而统计是回归问题,分类和回归也没有太本质的区别。
第二,机器学习往往会形成优化问题。刚才说要形成优化过程,它跟优化是什么区别?一个优化的学者,或者优化领域里面它纯粹就关注找到最优值。但是对于机器学习的学者来说,最紧急的是要找到预测数据。
现在看来,现代的机器学习它主要成功就在于表示,就是深度学习是一个表示,它不是单纯的是一个非线性模型,主要是一个非线性的表示。当然想到机器学习它的目的是预测,而预测是通过计算得出。
但是深度学习也遇到很多挑战,第一个是需要大数据的要求,大家网络是非常多,所以往往导致过参数的问题。另外就是在做表述是基于多层的表述,所以问题是高度的非凸化。
另外,现在机器学习要关注的重点问题有四个方面。第一个是可预测性、第二个可计算性、第三个是稳定性、第四个就是可解释性。可能现在认为主要重点就是在稳定性和泛化性方面,因为觉得神经网络没有可解释性。
最后,张志华教授就机器学习和数学工程之间的关系给出了这样的阐述:
统计为求解问题提供了数据驱动的建模途径;
概率论、随机分析、微分方程、微分流形等工具可以引入来研究 AI 的数学机理;
无论从统计角度还是从数学角度来研究 AI,其实际性能最后都要通过计算呈现出来:
1.数值分析,即求解连续数学问题的算法;
2.离散算法,即求解离散结构问题的算法;
3.大规模计算架构
实习/全职编辑记者招聘ing
加入我们,亲身体验一家专业科技媒体采写的每个细节,在最有前景的行业,和一群遍布全球最优秀的人一起成长。坐标北京·清华东门,在大数据文摘主页对话页回复“招聘”了解详情。简历请直接发送至zz@bigdatadigest.cn





