贝叶斯机器学习前沿进展
摘要:随着大数据的快速发展,以概率统计为基础的机器学习在近年来受到工业界和学术界的极大关注,并在视觉、语音、自然语言、生物等领域获得很多重要的成功应用,其中贝叶斯方法在过去20多年也得到了快速发展,成为非常重要的一类机器学习方法。总结了贝叶斯方法在机器学习中的最新进展,具体内容包括贝叶斯机器学习的基础理论与方法、非参数贝叶斯方法及常用的推理方法、正则化贝叶斯方法等。最后,还针对大规模贝叶斯学习问题进行了简要的介绍和展望,对其发展趋势作了总结和展望。
关键词:贝叶斯机器学习;非参数方法;正则化方法;大数据学习;大数据贝叶斯学习

机器学习是人工智能及模式识别领域的共同研究热点,其理论和方法已被广泛应用于解决工程应用和科学领域的复杂问题.2010年的图灵奖获得者为哈佛大学的LeslieValliant 授,其获奖工作之一是建立了概率近似正确(probably approximate correct,PAC)学习理论;2011年的图灵奖获得者为加州大学洛杉矶分校的JudeaPearl教授,其主要贡献为建立了以概率统计为理论基础的人工智能方法,其研究成果促进了机器学习的发展和繁荣。
机器学习的一个重要分支是贝叶斯机器学习,贝叶斯方法最早起源于英国数学家托马斯·贝叶斯在1763年所证明的一个关于贝叶斯定理的一个特例[1-2].经过多位统计学家的共同努力,贝叶斯统计在20世纪50年代之后逐步建立起来,成为统计学中一个重要的组成部分[2-3]。贝叶斯定理因为其对于概率的主观置信程度[4]的独特理解而闻名。此后由于贝叶斯统计在后验推理、参数估计、模型检测、隐变量概率模型等诸多统计机器学习领域方面有广泛而深远的应用[5-6]。从1763年到现在已有250多年的历史,这期间贝叶斯统计方法有了长足的进步[7]。在21世纪的今天,各种知识融会贯通,贝叶斯机器学习领域将有更广阔的应用场景,将发挥更大的作用。
1. 贝叶斯学习基础
本节将对贝叶斯统计方法进行简要的介绍[5]:主要包括贝叶斯定理、贝叶斯模型的推理方法、贝叶斯统计学的一些经典概念。
1.1 贝叶斯定理
用 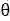
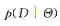
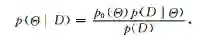
其中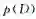
贝叶斯定理已经广为人知,这里介绍一种与贝叶斯公式等价但很少被人知道的表现形式,即基于优化的变分推理:
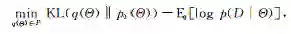
其中P为归一化的概率分布空间。可以证明,式(2)中的变分优化的最优解等价于式(1)中的后验推理的结果[8]。这种变分形式的贝叶斯定理具有两方面的重要意义:1)它为 变分贝叶斯方法[9](variational Bayes)提供了理论基础;2)提供了一个很好的框架 以便于引用后验约束,丰富贝叶斯模型的灵活性[10]。这两点在后面的章节中将具体阐述。
1.2 贝叶斯机器学习
贝叶斯方法在机器学习领域有诸多应用,从单变量的分类与回归到多变量的结构化输出预测、从有监督学习到无监督及半监督学习等,贝叶斯方法几乎用于任何一种学习任务.下面简要介绍较为基础的共性任务。
1)预测。给定训练数据D,通过贝叶斯方法得到对未来数据x的预测[5]:
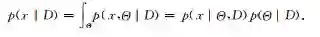
需要指出的是,当模型给定时,数据是来自于独立同分布的抽样,所以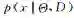
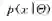
2)模型选择。另一种很重要的贝叶斯方法的应用是模型选择[11],它是统计和机器学习领域一个较为基础的问题。用M表示一族模型(如线性模型),其中每个元素Θ是一个具体的模型。贝叶斯模型选择通过比较不同族模型的似然函数来选取最优的:
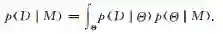
当没有明显先验分布的情况下,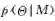
关于贝叶斯统计和贝叶斯学习更为详细的内容,有些论文和教材有更进一步的说明]。
2 非参数贝叶斯方法
在经典的参数化模型中模型的参数个数是固定的,不会随着数据的变化而变化.以无监督的聚类模型为例,如果能通过数据本身自动学习得到聚类中心的个数,比参数化模型(如K均值、高斯混合模型等)根据经验设定一个参数要好得多;这也是非参数模型一个较为重要的优势。相比较参数化贝叶斯方法,非参数贝叶斯方法(nonparametric Bayesian methods)因为其先验分布的非参数特性,具有描述数据能力强的优点[13],非参数贝叶斯方法因此在2000年以后受到较多关注[14]。例如具有未知维度的隐式混合模型[15]和隐式特征模型[16]、描述连续函数的高斯过程[17]等。需要强调的是非参数化贝叶斯方法并不是指模型没有参数,而是指模型可以具有无穷多个参数,并且参数的个数可以随着数据的变化而自适应变化,这种特性对于解决大数据环境下的复杂应用问题尤其重要,因为大数据的特点之一是动态多变。下面将主要针对其中的一些较为重要的模型和推理方法进行简要介绍。
2.1 狄利克雷过程
狄利克雷过程(Dirichletprocess, DP)是统计学家Ferguson于1973年提出的一个定义在概率测度Ω上的随机过程[18],其参数有集中参数α>0和基底概率分布
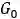
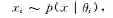
其中,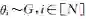
与狄利克雷过程等价的一个随机过程是中国餐馆过程(Chinese restaurant process, CRP)[19]。中国餐馆过程是定义在实数域上的具有聚类特性的一类随机过程,也因为其特有的较好展示特性而被经常使用。如图1所示,在中国餐馆过程中,假设有无限张餐桌和若干客人;其中第1名顾客选择第1张餐桌,之后的顾客按照多项式分布选择餐桌,其中选择每张餐桌的概率正比于该餐桌现在所坐的人数,同时以一定概率(正比于参数α)选择一个没人的餐桌.可以看到,当所有的客人选择完毕餐桌,我们可以按照餐桌来对客人进行一个划分.这里每张餐桌代表一个聚类,每个客人代表一个数据点。
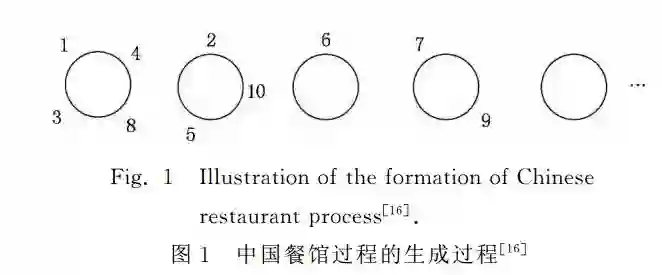
可以证明所有的聚类点参数θ可以通过式(6)得到:
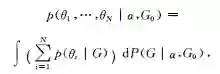
将狄利克雷混合模型中的G积分即可得到中国餐馆过程,这也说明了两个随机过程的关系.这种简洁的表述也很有利于马尔可夫蒙特卡洛方法的采样[20]。
另一种构造性的狄利克雷过程的表述是截棍过程(stickbreaking construction)[21].具体地说,将一根单位长度的棍,第k次切割都按照剩下的长度按照贝塔分布的随机变量,按比例切割:
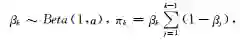
即如图2所示,对于一根长度为单位1的棍,第1次切割
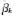
2.2 印度自助餐过程
与混合模型中每一个数据点只属于一个聚类不同,在特征模型中每一个数据点可以拥有多个特征,这些特征构成了数据生成的过程。这也符合实际情况中样本数据点有多个属性的实际需求。经典的特征模型主要有因子分析(factor analysis)、主成分分析(principal component analysis)[24-25]等。在传统的特征模型中,特征的数目是确定的,这给模型的性能带来一定限制.印度自助餐过程(indian buffet process, IBP)是2005年提出的[26],因其非参数特性能从数据中学习得到模型中的特征个数,使得模型能够更好地解释数据,已经在因子分析、社交网络链接预测等重要问题中应用[27-29]。
以二值(“0”或“1”)特征为例,假设有N个数据点,所有数据点的特征向量组成一个特征矩阵,IBP的产生式过程可以形象地类比为N个顾客到一个无穷多个餐品的自助餐馆进行选餐的过程,用“1”表示选择,“0”表示不选择,具体描述如图3所示的方法进行:
1)第1名顾客选择个
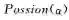
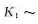
2)第2名及以后的顾客有两种情况:1. 对于已经被选过的餐品,按照选择该餐品的人数成正比的概率选择该餐品;2. 选择
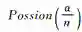
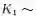
与中国餐馆过程类似,印度自助餐过程也有其对应的截棍过程[30].这里不再赘述,仅列出其构造性表述如下:
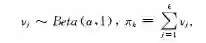
但是与中国餐馆过程的截棍过程不同的是棍的长度之和并不为1.印度自助餐过程也有其对应的采样方法和变分优化求解方法[16,30-31]。

2.3 应用及扩展
贝叶斯方法特别是最近流行的非参数贝叶斯方法已广泛应用于机器学习的各个领域,并且收到了很好的效果[32]。这里简要提出几点应用和扩展;对于大规模贝叶斯学习的相关应用将在第5节介绍,也可查阅相关文献[13-14,33]。
经典的非参数化贝叶斯方法通常假设数据具有简单的性质,如可交换性或者条件独立等;但是,现实世界中的数据往往具有不同的结构及依赖关系。为了适应不同的需求,发展具有各种依赖特性的随机过程得到了广泛关注。例如,在对文本数据进行主题挖掘时,数据往往来自不同的领域或者类型,我们通常希望所学习的主题具有某种层次结构,为此,层次狄雷克利过程(hierarchical Dirichlet process, HDP)[34]被提出,可以自动学习多层的主题表示,并且自动确定主题的个数.另外,具有多个层次的IBP过程也被提出[35],并用于学习深层置信网络的结构,包括神经元的层数、每层神经元的个数、层间神经元的连接结构等。其他的例子还包括具有马尔可夫动态依赖关系的无限隐马尔可夫模型[36]、具有空间依赖关系的狄雷克利过程[37]等。
另外,对于有监督学习问题,非参数贝叶斯模型最近也受到了广泛的关注.例如,社交网络数据建模和预测是一个重要的问题,近期提出的基于IBP的非参数化贝叶斯模型[27,29]可以自动学习隐含特征,并且确定特征的个数,取得很好的预测性能。使用DP混合模型同时作聚类和分类任务也取得了很好的结果[38]。
3 贝叶斯模型的推理方法
贝叶斯模型的推理方法是贝叶斯学习中重要的一环,推理方法的好坏直接影响模型的性能。具体地说,贝叶斯模型的一个关键性的问题是后验分布通常是不可解的,使得式(3)和式(4)中的贝叶斯积分也是不可解的。这时,就需要一些有效的推理方法。一般而言,主要有两类方法:变分推理方法(varia-tional inference)和蒙特卡洛方法(Monte Carlo methods)。这两类方法都在贝叶斯学习领域有广泛的应用,下面分别介绍这两类方法。
3.1 变分推理方法
变分法是一种应用较广的近似优化方法[39-40],在物理、统计学、金融分析、控制科学领域解决了很多问题。在机器学习领域,变分方法也有较多应用:通过变分分析,可以将非优化问题转化成优化问题求解,也可以通过近似方法对一些较难的问题进行变分求解[41]。
在变分贝叶斯方法中,给定数据集D和待求解的后验分布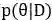
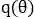
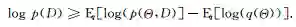
通过最大化该对数似然下界:
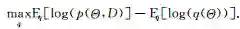
或者最小化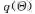
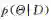
很多时候,模型Θ中往往有一些参数θ和隐变量h。这时变分问题可以通过变分期望最大化方法求解(variational EM algorithm):通过引入平均场假设(mean-fieldassumption)
3.2 蒙特卡洛方法
蒙特卡洛方法是一类通过利用模拟随机数对未知的概率分布进行估计;当未知分布很难直接估计或者搜索空间太大、计算太复杂时,蒙特卡洛方法就成为重要的推理和计算方法[45-46]。例如,贝叶斯机器学习通常需要计算某个函数在某种分布(先验或者后验)下的期望,而这种计算通常是没有解析解的。假设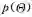

蒙特卡洛方法的基本思想是使用如下估计来近似I:

其中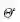
上面描述的是蒙特卡洛方法的基本原理,但实际过程中p的采样并不是很容易就可以得到,往往采用其他的方法进行,常用的方法有重要性采样(importance sampling)、拒绝采样(rejection sampling)、马尔可夫蒙特卡洛方法(Markov Chain Monte Carlo, MCMC)等。前两者在分布相对简单时比较有效,但是对于较高维空间的复杂分布效果往往不好,面临着维数灾难的问题。下面重点介绍MCMC方法,它在高维空间中也比较有效。
MCMC方法的基本思想是构造一个随机的马尔可夫链,使得其收敛到指定的概率分布,从而达到推理的目的[47]。一种较为常用的MCMC方法是Metropolis-Hastings算法[48](MH算法)。在MH算法中,通过构造一个从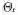
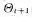
1)根据
2)计算接受概率:
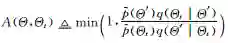
3)从0-1均匀分布中采样得到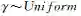
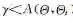
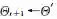

另一种常用的MCMC方法是吉布斯采样(Gibbs sampling)[46,49],它是MH算法的一种特例,吉布斯采样已广泛应用在贝叶斯分析的推理中。吉布斯采用是对多变量分布中每一个变量在其他已经观察得到采样的变量已知的条件下依次采样,更新现有的参数,最后收敛得到目标后验分布。假设需要采样的多元分布为,即每次选出一个维度j:1≤j≤d,其中d是多元分布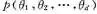
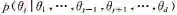
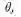
有很多贝叶斯模型都采用了MCMC的方法进行推理,取得了很好的效果[20,30,50]。除此之外,还有一类非随机游走的MCMC方法———LangevinMCMC[51]和Hybrid MonteCarlo[52]。这一类方法往往有更快的收敛速度,但是表述的复杂程度较大,因此受欢迎程度不及吉布斯采样,但是,最近在大数据环境下发展的基于随机梯度的采样方法非常有效,后文将会简要介绍。
4 正则化贝叶斯理论及应用举例
在第2节中提到了贝叶斯方法的两种等价表现方式,一种是后验推理的方式,另一种是基于变分分析的优化方法,其中第2种方式在近年有了较大发展.基于这种等价关系,我们近年来提出了正则化贝叶斯(regularized Bayesian inference, RegBayes)理论[10]:如图4所示,在经典贝叶斯推理过程中,后验分布只能从两个维度来获得,即先验分布和似然函数;而在正则化贝叶斯推理中,后验推理转化成一种变分优化的方式,通过引入后验正则化,为贝叶斯推理提供了第3维自由度,极大地丰富了贝叶斯模型的灵活性。在RegBayes理论的指导下,我们系统研究了基于最大间隔准则的判别式贝叶斯学习以及结合领域知识的贝叶斯学习等,取得了一系列的成果[]。

正则化贝叶斯推理的基本框架可以简述如下,在式(2)的基础上,引入后验正则化项,考虑领域知识或者期望的模型属性:
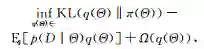
其中是一个凸函数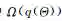
问题1.后验正则化从何而来.后验正则化是一个通用的概念,可以涵盖任何期望影响后验分布的信息。比如,在有监督学习任务(如图像/文本分类)中,我们期望后验分布能够准确地预测,这种情况下我们可以将分类错误率(或者某种上界)作为优化目标,通过后验正则化引用到学习过程中,典型的例子包括无限支持向量机[38](infinite SVM)、无限隐式支持向量机[56](infinitelatent SVM)、最大间隔话题模型[57](maximummargin supervised topic model, MedLDA)等,这些方法均采用了最大间隔原理,在贝叶斯学习过程中直接最小化分类错误率的上界(即铰链损失函数),在测试数据上取得显著的性能提升。
另外,在一些学习任务中,一些领域知识(如专家知识或者通过众包方式收集到的大众知识)可以提供数据之外的一些信息,对提高模型性能有很大帮助。在这种情况下,可以将领域知识作为后验约束,与数据一起加入模型中,实现高效贝叶斯学习。需要指出的是大众知识往往存在很大的噪音,如何采取有效的策略过滤噪音实现有效学习是问题的关键。在这方面,我们提出了将使用逻辑表达的领域知识鲁棒地引入贝叶斯主题模型,实现了更优秀的模型效果[58]。
问题2.先验分布、似然函数以及后验正则化之间有何关系。先验分布是与数据无关的,基于先验知识的概率分布不能反映数据的统计特性;似然函数则是基于数据产生的概率分布,反映了数据的基本性质,通常定义为具有良好解析形式的归一化的概率分布。而后验正则化项同样是利用数据的特性来定义的,但是,它具有更广泛灵活的方式,不受归一化的约束,因此,可以更方便准确地刻画问题的属性或者领域知识,如问题1中所举的最大间隔学习以及领域知识与贝叶斯统计相结合等示例。甚至可以证明,一些后验分布不可以通过贝叶斯定理得到,但是可以通过后验正则化得到[10]。因此,RegBayes是比经典贝叶斯方法更灵活更强大的方法。
问题3.如何求解优化问题。虽然正则化贝叶斯具有极强的灵活性,其学习算法仍然可以使用变分方法或者蒙特卡洛方法进行求解,具体的求解方法请阅读相关论文。下面介绍的大数据贝叶斯学习理论和算法均可以应用到快速求解正则化贝叶斯模型[55],这也是目前的研究热点。
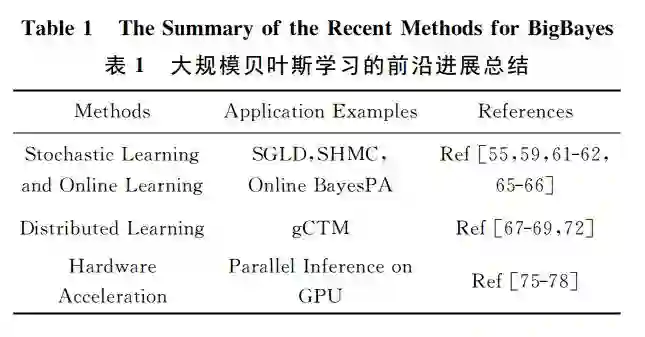
5 大数据贝叶斯学习
随着互联网技术的发展,研究面向大数据的机器学习理论、算法及应用成为当前研究的热点[[59]59],得到学术界和工业界的广泛关注。贝叶斯模型有较好的数据适应性和可扩展性,在很多经典问题上都取得了很好的效果,但是,传统贝叶斯模型的一个较大的问题在于其推理方法通常较慢,特别是在大数据背景下很难适应新的模型的要求。因此,如何进行大规模贝叶斯学习方法是学术界的重要挑战之一。可喜的是近期在大数据贝叶斯学习(big Bayesian learning, BigBayes)方面取得了显著的进展。下面简单介绍在随机算法及分布式算法方面的进展,并以我们的部分研究成果作为示例。表1所示为对目前的若干前沿进展简要总结:
5.1 随机梯度及在线学习方法
当数据量较大时精确的算法往往耗时较长,不能满足需要。一类常用的解决方案是采用随机近似算法[60-61]。这类算法通过对大规模数据集的多次随机采样(random subsampling),可以在较快的时间内收敛到较好的结果。这种思想已经在变分推理和蒙特卡洛算法中广泛采用,简要介绍如下。
在变分推理方面,如前所述,其核心是求解优化问题,因此,基于多次随机降采样的随机梯度下降算法成为很自然的选择。具体地说,随机梯度下降算法(stochastic gradient descent, SGD)[62]每次随机选取一个数据子集,并用该子集上计算的梯度估计整个数据集上的梯度,对要求解的参数进行更新:
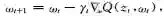
其中Q是待优化的目标函数,是数据的第t个子集。值得注意的是,欧氏空间中的梯度并非最优的求解变分分布的方向;对于概率分布的寻优,自然梯度往往取得更快的收敛速度[63]。近期的主要进展包括随机变分贝叶斯方法[61]以及多种利用模型特性的快速改进算法[64][64]。
在蒙特卡洛算法方面,可以将随机梯度的方法用于改进对应的基于梯度的采样算法,如随机梯度朗之万动力学采样方法(stochastic gradient langevin dynamics, SGLD)[65]、随机梯度哈密尔顿蒙特卡洛(stochasticHamiltonian Monte Carlo, SHM)[66][66]。这些算法加快了蒙特卡洛采样的速度、有较好的效果。
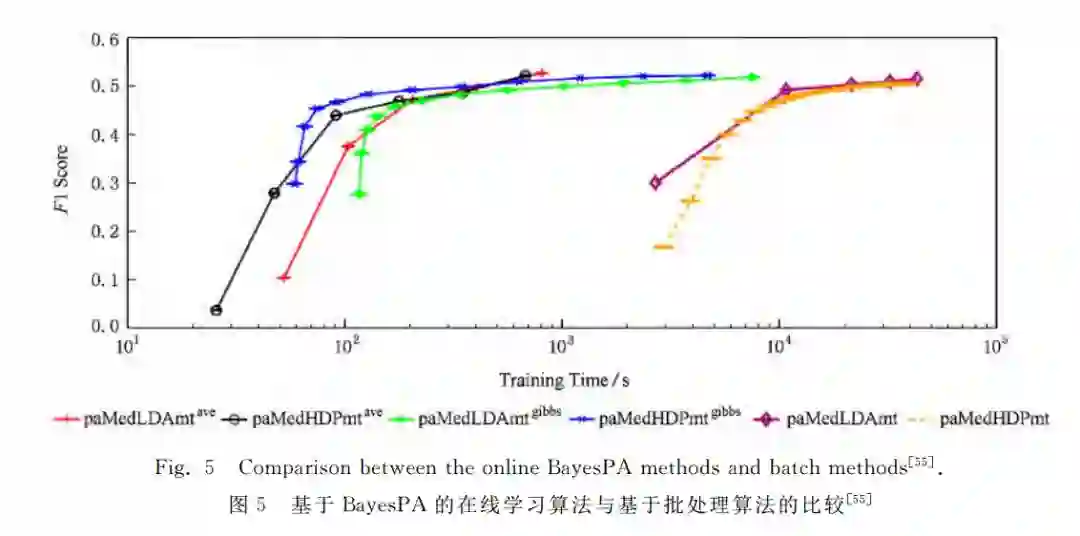
例1.为了适应动态流数据的处理需求,基于在线学习的大规模贝叶斯推理算法也成为近期的研究热点,主要工作包括流数据变分贝叶斯[67]等。我们近期提出了在线贝叶斯最大间隔学习(online Bayesian passive-aggressive learning, Online BayesPA )框架,显著提高了正则化贝叶斯的学习效率,并且给出了在线学习后悔值的理论界[55]。在100多万的维基百科页面数据上的部分实验结果如图5所示,可以看出,基于在线学习的算法比批处理算法快100倍左右,并且不损失分类的准确率。
5.2 分布式推理算法
另一种适用于大规模贝叶斯学习问题的算法是基于分布式计算的[68],即部署在分布式系统上的贝叶斯推理算法。这类算法需要仔细考虑算法的实际应用场景,综合考量算法计算和通信的开销,设计适合于不同分布式系统的推理算法。
一些算法中的部分参数之间不需要交换信息,只需要计算得到最后结果汇总即可;对于这类问题,只需要对原算法进行适当优化,部署在系统上即可有较好的效果。但是,还有更多算法本身并不适合并行化处理,这就意味着算法本身需要修改,使得其可以进行分布式计算,这也是大规模贝叶斯学习的研究热点之一,并且已经取得很多重要进展,包括分布式变分推理[67]和分布式蒙特卡洛方法[69]等。
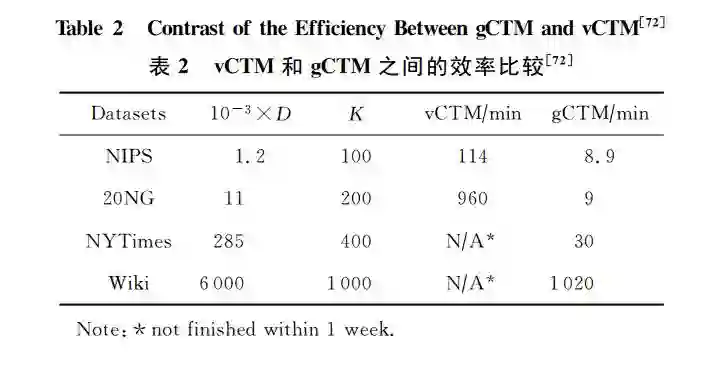
例2.以主题模型为例,经典的模型使用共轭狄利克雷先验,可以学习大规模的主题结构[70],但是,不能学习主题之间的关联关系。为此,使用非共轭 Logistic-Normal先验的关联主题模型(correlated topic model, CTM)[71]被提出。CTM的缺点是其推理算法比较困难,已有的算法只能处理几十个主题的图结构学习。为此,笔者课题组近期提出了CTM的分布式推理算法[72],可以处理大规模的数据集,学习上千个主题之间的图结构。该算法的部分结果如表2所示,其中D表示数据集大小,K表示主题个数。由表2可以看出分布式推理算法(即gCTM)极大地提高了模型可以承载的数据量(如600万的维基百科网页)和更多的主题个数(如1000)。这个项目的代码及更多信息已经公布,读者可以自行浏览[73]。
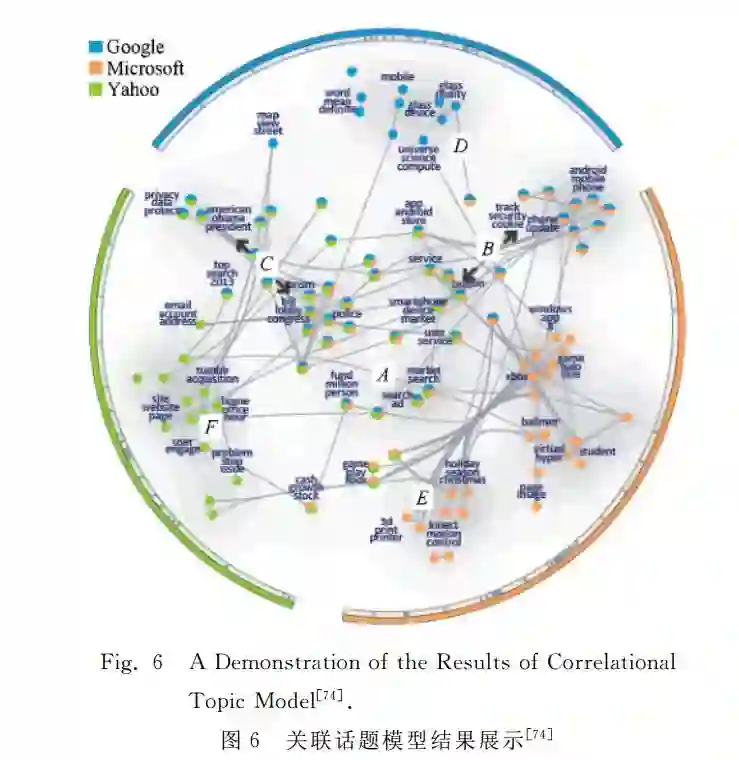
在上述大规模主题图结构的学习基础上,进一步开发了“主题全景图”(TopicPanorama)可视化界面,它可以将多个主题图结构进行融合,并且以用户友好的方式展现在同一个界面上,如图6所示,其中每个节点代表一个主题,节点之间的边代表相关联关系,边的长度代表关联强度,所用数据集为微软、谷歌、雅虎等3个IT公司相关的新闻网页。该可视化工具具有多种交互功能,用户可以使用放大或缩小功能对主题图的局部进行仔细查看,同时,也可以修改图的结构并反馈给后台算法进行在线调整。多位领域专家一致同意该工具可以方便分析社交媒体数据。更多具体描述参见文献[74]。
5.3 基于硬件的加速
随着硬件的发展,使用图形处理器(graphics processing units, GPU)、现场可编程逻辑门阵列(field-programmablegate array, FPGA)等硬件资源对贝叶斯学习方法进行加速也是最近兴起的研究热点。例如,有研究者利用GPU技术对话题模型的变分方法[75]和MCMC算法[76-77]进行加速,还有一些研究者利用FPGA对蒙特卡洛算法[78]进行加速。利用强大的硬件设备,搭配适当的模型和算法架构,可以起到事半功倍的效果。
6 总结与展望
贝叶斯统计方法及其在机器学习领域的应用是贝叶斯学习的重要研究内容。因为贝叶斯理论的适应性和可扩展性使得贝叶斯学习得到广泛的应用.非参数贝叶斯方法和正则化贝叶斯方法极大地发展了贝叶斯理论,使其拥有更加强大的生命力。
近年来,大数据贝叶斯学习成为人们关注的焦点,如何加强贝叶斯学习的灵活性以及如何加快贝叶斯学习的推理过程,使其更加适应大数据时代的挑战成为人们考虑的问题。在这一时期许多新的方法和理论将被提出,贝叶斯学习也与其他许多方面的知识相结合,如并行计算、数据科学等,产生很多新的成果。可以预想,贝叶斯学习肯定会有更多更新更好的成果,也会在将来有更广泛的应用。





Zhu Jun. born in 1983. Associateprofessor and PhD supervisor in Tsinghua University. His current researchinterests include machine learning, Bayesian statistics, and large-scalelearning algorithms and applications.

Hu Wenbo, born in 1992.PhDcandidate in Tsinghua University. His current research interests includemachine learning and scalable Bayesian learningmethods(hwb13@mails.tsinghua.edu.cn).
本文摘自《计算机研究与发展》2015.52(1)

架构文摘
ID:ArchDigest
互联网应用架构丨架构技术丨大型网站丨大数据丨机器学习

更多精彩文章,请点击下方:阅读原文


