决策树
点击上方
Datartisan数据工匠
可以订阅哦!
引子
每一天生活中有很多事情需要我们做出决定,降温了就要加衣服,衣服旧了就该买新的,虽然这些事情非常的多,但是并不是非常的复杂,已经存在一些基本的逻辑,只要套用上面的关系,就能够得出答案了,这就是生活给我们的套路。例如过春节的时候,总能碰上七大姑八大姨的,不管这么聊,我们总是成为这些七大姑八大姨调侃的对象。难道他们也有自己的套路吗?总结如下:
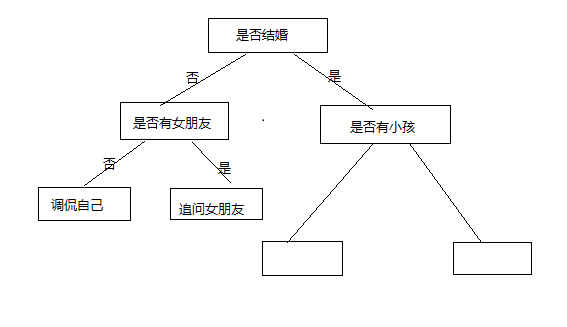
这就是一棵决策树了,通过一个个条件来得出,你到底是属于哪一类,适合怎么样的跟你聊天,你谈论的重点是什么。决策树是机器学习中非常常见的一种方法,因为他很简洁,而且也非常的容易知道为什么被归为这个分类的,他相当于一个专家,里面有非常多的规则,决定了我们该往哪个方向去走。但问题是没有专家啊,哪里来的那么多的专家,但是如果有大量 的数据,如果在大数据中,总结出规律,建立自己的规则呢?
创建决策树
如何对数据进行区分,如何找到规则,这是一个重点,先用一维的数据来进行标示,在坐标轴中,分类如下:
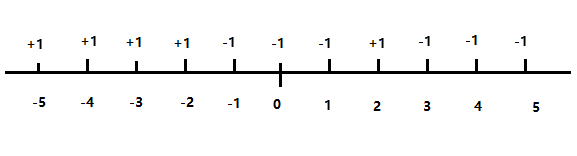
用数据来表示,如下的分类

在这个坐标系中,用肉眼是比较容易看出来应该要怎么样来分类的,例如在x轴的-1.5中做一个分割线,把这组数据分为两类,一类中+1比较多,一类中-1比较多,这样的分法是比较可取的,因为这样分开的话,在各个分类中被错误分类的个数比较少。
但是回头再想,我们分类的规则能不能抽出一种更普遍的理论呢?
每个分类中,最好是存在一种类型,不希望掺入太多不同类型的,也就是说一个分类中它的纯度要高,杂质要少。在信息论中,香农定理就能表示数据的纯度,简单的解释是这样的,如果一组数据中有1,1,1,1,1,1,1,1,1这里有9个1,如果使用一种压缩算法简单的可以写成9:1数据就别压缩了,而如果是1,1,1,1,0,1,1,1,0,用压缩算法就得写成7:1,2:0,这样就需要用更多的数据量来表示这个这段信息,通常来讲这也叫做信息增益,或者叫做熵。
这里也可以看出,信息较纯的数据,他的信息增益是比较小的,杂质越多,信息增益越大,可以拿过来用到我们该如果进行分类上。我们可以遍历各种不同的分类结果,找到信息增益最小的那个分类,就是数据该如何进行分类。通过已有的历史信息自动的找出分类的规则,找到熵最小的做法是怎么样的一种分法。
信息的定义如下:
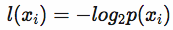
信息熵定义为:
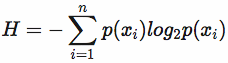
计算信息熵的过程如下:

通过遍历各个分类可能找出最小信息增益的分类可能:
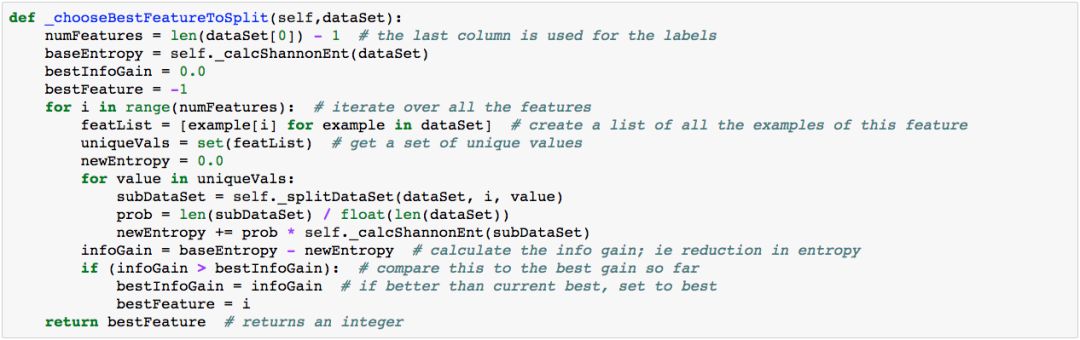
通过递归的方式,把数据做归档,建立起决策树:
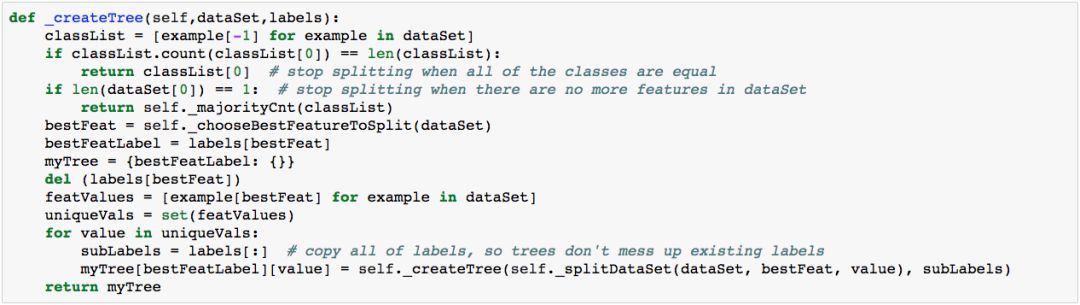
建立起决策树关键是如何建立起决策树的规则,而通过数据的分类时较为关键的是如何判断分出的类型是最好的,这就是为何需要使用到信息增益或熵的概念。决策树的理论较为简单,但在实际的使用中,经常会用到,因为决策树有着非常好的可视化,能够明明白白的告诉你,为什么你是属于这个分类下的。
绘制决策树
通过决策树的绘制,我们可以更加清楚的了解我们是如何进行分类的,一组数据经过决策树以后是如何一步一步的得出决策数据的。每一次进行决策的时候,通过选取是分类结果到达分类最纯的标签,这样如此的反复下去。通过把决策过程的树绘制出来,会更容易进行理解。
绘制决策树,我们使用的是graphviz,关于graphviz的 使用可以先看看如下系类的graphviz文章。
在了解了graphviz的绘制以后,决策树就容易很多了。

通过绘制节点,并连接相关的节点,在碰到节点为树的情况下进行递归操作,能够绘制完整棵树。
预测未知数据的决策
创建完决策树以后,使用决策树来对未知的数据进行预测,预测的算法也较为明显,通过一步一步树的不同走向,得出最后不同的结果。

决策树完整的代码在这里,决策树。
实例
常见一组简单的实验数据,训练符合决策树,通过决策树预测未知的数据。
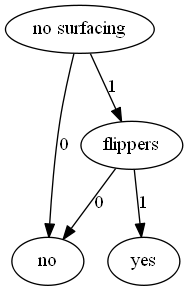
绘制的决策树如下:
sklearn 下的决策树
sklearn同样的也有决策树的实现,使用的是sklearn.tree下的DecisionTreeClassifier。 在如下的例子中,使用的数据是sklearn自带的 iris 数据,把数据分为两部分,前面120个数据用来作为训练数据,其余30个数据用来做测试,最后测出决策树的准确率。

同样的sklearn也可以使用graphviz,进行决策树的绘制,export_graphviz方法也很简单。
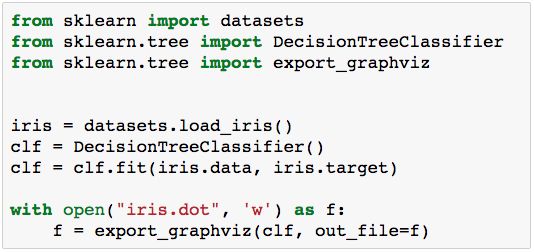
输出iris.dot文件,文件的内容如下:

使用命令:

结果图如下:
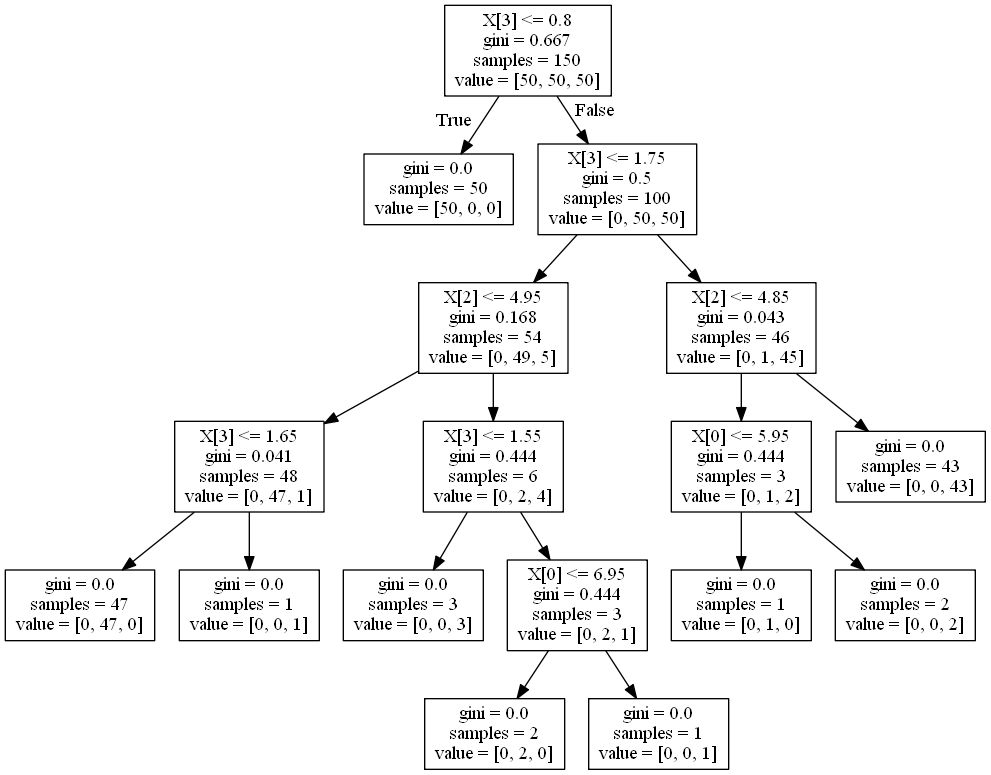
是不是很清楚,明明白白每一步是如何走的。
有了决策树,有了树,就会有森林。在现实中森林中是由许多的树组成的。关键的问题在于如何构建这些树。在集成算法中有一种方法叫做Bagging算法。 Bagging算法是最符合评分系统的算法,在Bagging算法中,包原始的数据集分为S份,在S个数据集建好之后,用某个学习算法对数据集进行训练,得出S个分类器。最具有代表性的是随机森林算法(random forest),这种算法较容易用各种语言实现。
转载请标明来之:阿猫学编程
更多教程:阿猫学编程-python基础教程

更多课程和文章尽在微信号:
「datartisan数据工匠」





