【论文推荐】最新6篇图像描述生成相关论文—语言为枢纽、细粒度、生成器、注意力机制、策略梯度优化、判别性目标
【导读】专知内容组整理了最近六篇图像描述生成(Image Caption)相关文章,为大家进行介绍,欢迎查看!
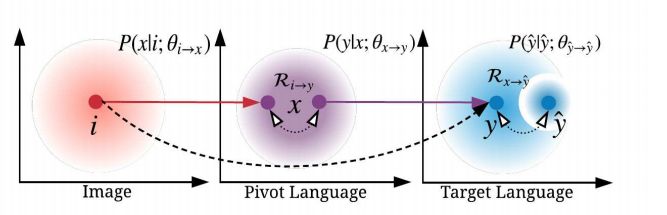
1. Unpaired Image Captioning by Language Pivoting(以语言为枢纽生成不成对图像的描述)
作者:Jiuxiang Gu,Shafiq Joty,Jianfei Cai,Gang Wang
机构:Alibaba AI Labs,Nanyang Technological University
摘要:Image captioning is a multimodal task involving computer vision and natural language processing, where the goal is to learn a mapping from the image to its natural language description. In general, the mapping function is learned from a training set of image-caption pairs. However, for some language, large scale image-caption paired corpus might not be available. We present an approach to this unpaired image captioning problem by language pivoting. Our method can effectively capture the characteristics of an image captioner from the pivot language (Chinese) and align it to the target language (English) using another pivot-target (Chinese-English) parallel corpus. We evaluate our method on two image-to-English benchmark datasets: MSCOCO and Flickr30K. Quantitative comparisons against several baseline approaches demonstrate the effectiveness of our method.
期刊:arXiv, 2018年3月15日
网址:
http://www.zhuanzhi.ai/document/6a166b05007d9eaf77d591039f9bf5a4
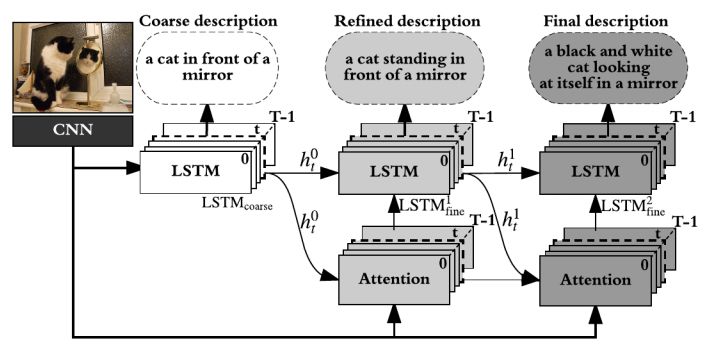
2. Stack-Captioning: Coarse-to-Fine Learning for Image Captioning(堆叠Captioning:对图像描述进行由粗粒度到细粒度的学习)
作者:Jiuxiang Gu,Jianfei Cai,Gang Wang,Tsuhan Chen
机构:Nanyang Technological University,Alibaba AI Labs
摘要:The existing image captioning approaches typically train a one-stage sentence decoder, which is difficult to generate rich fine-grained descriptions. On the other hand, multi-stage image caption model is hard to train due to the vanishing gradient problem. In this paper, we propose a coarse-to-fine multi-stage prediction framework for image captioning, composed of multiple decoders each of which operates on the output of the previous stage, producing increasingly refined image descriptions. Our proposed learning approach addresses the difficulty of vanishing gradients during training by providing a learning objective function that enforces intermediate supervisions. Particularly, we optimize our model with a reinforcement learning approach which utilizes the output of each intermediate decoder's test-time inference algorithm as well as the output of its preceding decoder to normalize the rewards, which simultaneously solves the well-known exposure bias problem and the loss-evaluation mismatch problem. We extensively evaluate the proposed approach on MSCOCO and show that our approach can achieve the state-of-the-art performance.
期刊:arXiv, 2018年3月14日
网址:
http://www.zhuanzhi.ai/document/260417b90f37d62c8c7fa1b70ef1dcd4
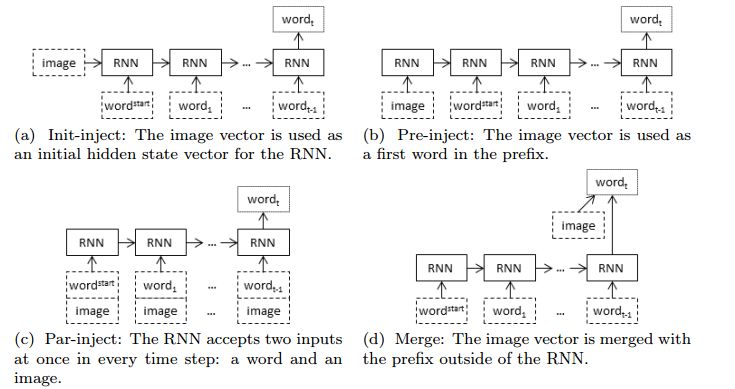
3. Where to put the Image inan Image Caption Generator(在图片标题生成器中放置图像的位置)
作者:Marc Tanti,Albert Gatt,Kenneth P. Camilleri
机构:University of Malta
摘要:When a recurrent neural network language model is used for caption generation, the image information can be fed to the neural network either by directly incorporating it in the RNN -- conditioning the language model by `injecting' image features -- or in a layer following the RNN -- conditioning the language model by `merging' image features. While both options are attested in the literature, there is as yet no systematic comparison between the two. In this paper we empirically show that it is not especially detrimental to performance whether one architecture is used or another. The merge architecture does have practical advantages, as conditioning by merging allows the RNN's hidden state vector to shrink in size by up to four times. Our results suggest that the visual and linguistic modalities for caption generation need not be jointly encoded by the RNN as that yields large, memory-intensive models with few tangible advantages in performance; rather, the multimodal integration should be delayed to a subsequent stage.
期刊:arXiv, 2018年3月14日
网址:
http://www.zhuanzhi.ai/document/2b67470e0a35c47c0cbaefb11548ac58
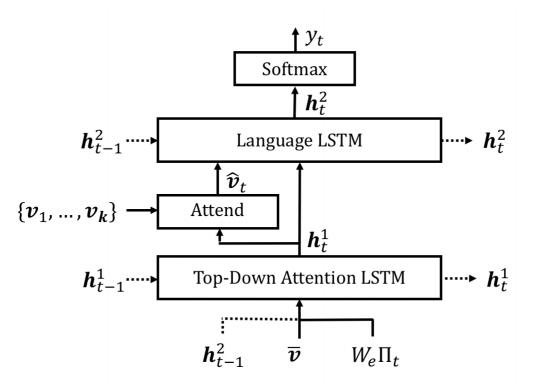
4. Bottom-Up and Top-Down Attention for Image Captioning and Visual Question Answering(用于图像描述和视觉问题回答的自底向上和自顶向下的注意力机制)
作者:Peter Anderson,Xiaodong He,Chris Buehler,Damien Teney,Mark Johnson,Stephen Gould,Lei Zhang
机构:Australian National University,JD AI Research,Microsoft Research,University of Adelaide,Macquarie University
摘要:Top-down visual attention mechanisms have been used extensively in image captioning and visual question answering (VQA) to enable deeper image understanding through fine-grained analysis and even multiple steps of reasoning. In this work, we propose a combined bottom-up and top-down attention mechanism that enables attention to be calculated at the level of objects and other salient image regions. This is the natural basis for attention to be considered. Within our approach, the bottom-up mechanism (based on Faster R-CNN) proposes image regions, each with an associated feature vector, while the top-down mechanism determines feature weightings. Applying this approach to image captioning, our results on the MSCOCO test server establish a new state-of-the-art for the task, achieving CIDEr / SPICE / BLEU-4 scores of 117.9, 21.5 and 36.9, respectively. Demonstrating the broad applicability of the method, applying the same approach to VQA we obtain first place in the 2017 VQA Challenge.
期刊:arXiv, 2018年3月14日
网址:
http://www.zhuanzhi.ai/document/ccf862349b06541be2dc5312a84fc2db
5. Improved Image Captioning via Policy Gradient optimization of SPIDEr(通过SPIDEr策略梯度优化来改进图像描述)
作者:Siqi Liu,Zhenhai Zhu,Ning Ye,Sergio Guadarrama,Kevin Murphy
机构:University of Oxford,Google
摘要:Current image captioning methods are usually trained via (penalized) maximum likelihood estimation. However, the log-likelihood score of a caption does not correlate well with human assessments of quality. Standard syntactic evaluation metrics, such as BLEU, METEOR and ROUGE, are also not well correlated. The newer SPICE and CIDEr metrics are better correlated, but have traditionally been hard to optimize for. In this paper, we show how to use a policy gradient (PG) method to directly optimize a linear combination of SPICE and CIDEr (a combination we call SPIDEr): the SPICE score ensures our captions are semantically faithful to the image, while CIDEr score ensures our captions are syntactically fluent. The PG method we propose improves on the prior MIXER approach, by using Monte Carlo rollouts instead of mixing MLE training with PG. We show empirically that our algorithm leads to easier optimization and improved results compared to MIXER. Finally, we show that using our PG method we can optimize any of the metrics, including the proposed SPIDEr metric which results in image captions that are strongly preferred by human raters compared to captions generated by the same model but trained to optimize MLE or the COCO metrics.
期刊:arXiv, 2018年3月13日
网址:
http://www.zhuanzhi.ai/document/3c8a48f7c82105723c248638211e4329
6. Discriminability objective for training descriptive captions(训练描述性标题的判别性目标)
作者:Ruotian Luo,Brian Price,Scott Cohen,Gregory Shakhnarovich
机构:Adobe Research
摘要:One property that remains lacking in image captions generated by contemporary methods is discriminability: being able to tell two images apart given the caption for one of them. We propose a way to improve this aspect of caption generation. By incorporating into the captioning training objective a loss component directly related to ability (by a machine) to disambiguate image/caption matches, we obtain systems that produce much more discriminative caption, according to human evaluation. Remarkably, our approach leads to improvement in other aspects of generated captions, reflected by a battery of standard scores such as BLEU, SPICE etc. Our approach is modular and can be applied to a variety of model/loss combinations commonly proposed for image captioning.

期刊:arXiv, 2018年3月13日
网址:
http://www.zhuanzhi.ai/document/cca5179bc6ebd044db9ca2d8737df846
-END-
专 · 知
人工智能领域主题知识资料查看获取:【专知荟萃】人工智能领域26个主题知识资料全集(入门/进阶/论文/综述/视频/专家等)
同时欢迎各位用户进行专知投稿,详情请点击:
【诚邀】专知诚挚邀请各位专业者加入AI创作者计划!了解使用专知!
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请扫一扫如下二维码关注我们的公众号,获取人工智能的专业知识!

请加专知小助手微信(Rancho_Fang),加入专知主题人工智能群交流!加入专知主题群(请备注主题类型:AI、NLP、CV、 KG等)交流~

点击“阅读原文”,使用专知!



