那些年我们一起卷过的卷积

极市导读
本篇文章将回顾那些年的一些经典卷积神经网络,并提炼要点且从网络结构、工作亮点、核心实现代码方面来进行阐述。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
引言
卷积是图像神经网络中的重要组成部分,它担起提取特征的重任,每当你编写一个网络结构的时候,它总会大喊"我来组成头部!",这么重要的头部自然值得我们好好地重视起来了"认真脸jpg",本篇文章将回顾那些年的一些经典卷积神经网络,并提炼要点且从以下几方面来进行阐述。
-
可供参考的资料、ImageNet 1000分类效果(采用224大小图片的效果,部分来自paperwithcode部分来自论文自身)。 -
网络的整体 or 核心结构图。 -
作者构建这些卷积网络的亮点。 -
具体的核心实现代码。
神经网络架构
(63.3% - 2012) AlexNet
论文: ImageNet Classification with Deep Convolutional Neural Networks
(https://proceedings.neurips.cc/paper/2012/file/c399862d3b9d6b76c8436e924a68c45b-Paper.pdf)
Blog : AlexNet: The First CNN to win Image Net
(https://www.kaggle.com/code/blurredmachine/alexnet-architecture-a-complete-guide/notebook)
效果: ImageNet top-1 accuracy 63.3%
结构图:
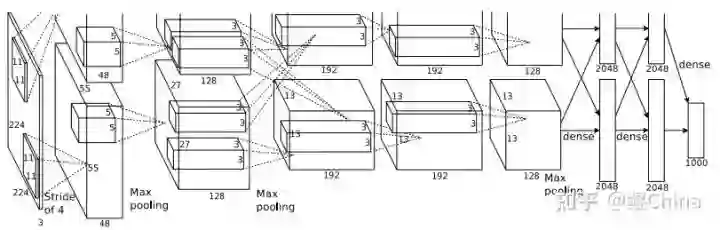
成就
-
第一个在ImageNet上跑起来的神经网络,在当年的竞赛中成绩大幅度领先第二名。
创新
-
2张GTX580 3G显存上训练百万级别的数据,在模型训练上做了一些工程的改进,现在单张A100显存能到80G,足以见当年的艰难。 -
使用大卷积(11x11、5x5)和 全连接层,事实证明潮流是一个cycle,现在大卷积又开始流行起来了= =。 -
RELU:非线性激活单元,直到现在依然很流。 -
Dropout:防止过拟合,有模型ensemble的效果,后续应用广泛。 -
Local Response Normalization:一种正则化方法帮助模型更好的训练,后续基本没人用,大家可以阅读原文了解下。
代码:
class AlexNet(nn.Module):
def __init__(self, num_classes: int = 1000) -> None:
super(AlexNet, self).__init__()
self.features = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=11, stride=4, padding=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(64, 192, kernel_size=5, padding=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(192, 384, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(384, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(256, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
)
self.avgpool = nn.AdaptiveAvgPool2d((6, 6))
self.classifier = nn.Sequential(
nn.Dropout(),
nn.Linear(256 * 6 * 6, 4096),
nn.ReLU(inplace=True),
nn.Dropout(),
nn.Linear(4096, 4096),
nn.ReLU(inplace=True),
nn.Linear(4096, num_classes),
)
def forward(self, x: torch.Tensor) -> torch.Tensor:
x = self.features(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.classifier(x)
return x
(74.5% - 2014) VGG
论文: Very Deep Convolutional Networks for Large-Scale Image Recognition
(https://link.zhihu.com/?target=https%3A//arxiv.org/abs/1409.1556)
Blog: 一文读懂VGG网络
(https://zhuanlan.zhihu.com/p/41423739)
效果: ImageNet top-1 accuracy 74.5%
结构图:
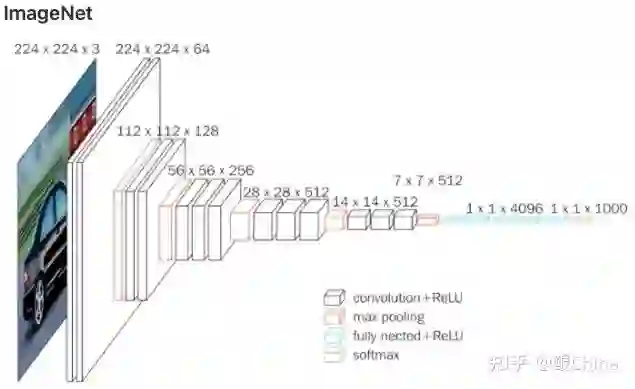
成就: ImageNet成绩大幅超过AlexNet,引领了未来网络朝着深度加深的方向进行。
创新: 使用3X3卷积核代替11X11, 5X5,将网络的深度做进一步加深的同时引入更多的非线性层。
代码:
import torch.nn as nn
cfg = {
"vgg11": [64, "M", 128, "M", 256, 256, "M", 512, 512, "M", 512, 512, "M"],
"vgg13": [64, 64, "M", 128, 128, "M", 256, 256, "M", 512, 512, "M", 512, 512, "M"],
"vgg16": [64, 64, "M", 128, 128, "M", 256, 256, 256, "M", 512, 512, 512, "M", 512, 512, 512, "M"],
"vgg19": [64, 64, "M", 128, 128, "M", 256, 256, 256, 256, "M", 512, 512, 512, 512, "M", 512, 512, 512, 512, "M"],
}
class VGG(nn.Module):
def __init__(self, vgg_name, num_outputs=10):
super().__init__()
self.features = self._make_layers(cfg[vgg_name])
self.classifier = nn.Linear(512, num_outputs)
def forward(self, x):
out = self.features(x)
out = out.view(out.size(0), -1)
out = self.classifier(out)
return out
def _make_layers(self, cfg):
layers = []
in_channels = 3
for x in cfg:
if x == "M":
layers += [nn.MaxPool2d(kernel_size=2, stride=2)]
else:
layers += [
nn.Conv2d(in_channels, x, kernel_size=3, padding=1),
nn.BatchNorm2d(x),
nn.ReLU(inplace=True),
]
in_channels = x
layers += [nn.AvgPool2d(kernel_size=1, stride=1)]
return nn.Sequential(*layers)
(80.0% - 2016) Inception
论文:
-
Inception V1(https://arxiv.org/pdf/1409.4842v1.pdf) -
Inception V2&3(https://arxiv.org/pdf/1512.00567v3.pdf) -
Inception V4(https://arxiv.org/pdf/1602.07261.pdf)
Blog : [A Simple Guide to the Versions of the Inception Network]
(https://towardsdatascience.com/a-simple-guide-to-the-versions-of-the-inception-network-7fc52b863202)
效果: ImageNet top-1 accuracy 80.00%
结构图:
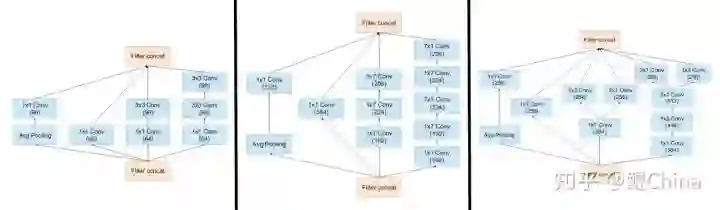
创新:
-
使用多尺度卷积核来提取信息,V1-V4基本就是在做这件事,无非是不断的优化性能。 -
提出了Label Smoothing,这个东西比赛用的挺多的。
(78.6% - 2015) ResNet
论文:[Deep Residual Learning for Image Recognition]
(https://arxiv.org/abs/1512.03385)
Blog :
-
Resnet到底在解决一个什么问题呢?(https://www.zhihu.com/question/64494691/answer/786270699)
-
你必须要知道CNN模型:ResNet(https://zhuanlan.zhihu.com/p/31852747)
效果: ImageNet top-1 accuracy 78.2% or 82.4%([ResNet strikes back: An improved training procedure in timm]
(https://paperswithcode.com/paper/resnet-strikes-back-an-improved-training))
结构图:
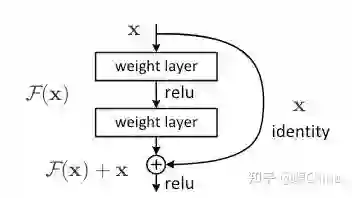
成就: 利用残差结构使得网络达到了前所未有的深度同时性能继续提升、同时使损失函数平面更加光滑(看过很多解释,这个个人觉得比较靠谱)
创新: 残差网络
代码:! key是关键代码、其实就一行~
class ResNetBasicBlock(nn.Module):
expansion = 1
def __init__(self, in_planes, out_planes, stride=1):
super().__init__()
self.conv1 = nn.Conv2d(in_planes, out_planes, kernel_size=3, stride=stride, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(out_planes)
self.conv2 = nn.Conv2d(out_planes, out_planes, kernel_size=3, stride=1, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(out_planes)
self.shortcut = nn.Sequential()
# print(f"in_planes : {in_planes} | self.expansion * out_planes : {self.expansion * out_planes}")
if stride != 1 or in_planes != self.expansion * out_planes:
self.shortcut = nn.Sequential(
nn.Conv2d(in_planes, self.expansion * out_planes, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(self.expansion * out_planes),
)
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x)))
# print(f" conv 1: {out.shape}")
out = self.bn2(self.conv2(out))
# print(f" conv 2: {out.shape}")
out += self.shortcut(x) #! key
# print(f"shortcut: {out.shape}")
out = F.relu(out) # 然后一起relu
# print("===" * 10)
return out
(77.8% - 2016) DenseNet
*论文: *Densely Connected Convolutional Networks
(https://arxiv.org/abs/1608.06993)
Blog :
-
CVPR 2017最佳论文作者解读:DenseNet 的“what”、“why”和“how”(https://www.leiphone.com/category/ai/0MNOwwfvWiAu43WO.html) -
[pytorch源码解读]之DenseNet的源码解读(https://blog.csdn.net/u014453898/article/details/105670550)
效果: ImageNet top-1 accuracy 77.8%
结构图:
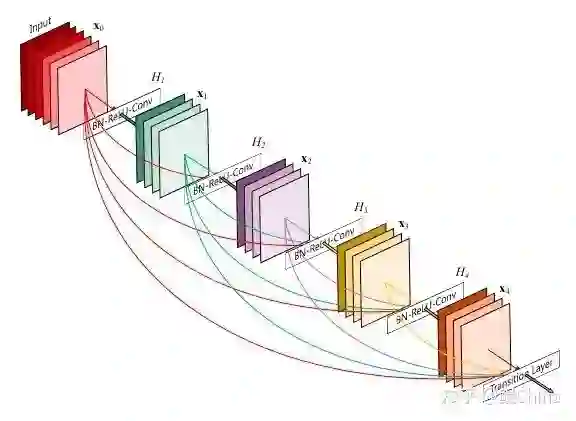
创新: 利用DenseBlock进行新特征的探索和原始特征的多次重用
代码:! key是关键代码、其实就一行~
class Bottleneck(nn.Module):
def __init__(self, in_planes, growth_rate):
super(Bottleneck, self).__init__()
self.bn1 = nn.BatchNorm2d(in_planes)
self.conv1 = nn.Conv2d(in_planes, 4 * growth_rate, kernel_size=1, bias=False)
self.bn2 = nn.BatchNorm2d(4 * growth_rate)
self.conv2 = nn.Conv2d(4 * growth_rate, growth_rate, kernel_size=3, padding=1, bias=False)
def forward(self, x):
out = self.conv1(F.relu(self.bn1(x)))
out = self.conv2(F.relu(self.bn2(out)))
out = torch.cat([out, x], 1) #! key
return out
(80.9% - 2016) ResNext
论文: ResNext : Aggregated Residual Transformations for Deep Neural Networks
(https://arxiv.org/abs/1611.05431)
Blog :
-
ResNeXt详解(https://zhuanlan.zhihu.com/p/51075096)
-
ResNeXt的分类效果为什么比Resnet好?(https://www.zhihu.com/question/323424817/answer/1078704765)
效果: ImageNet top-1 accuracy 80.9%
结构图:
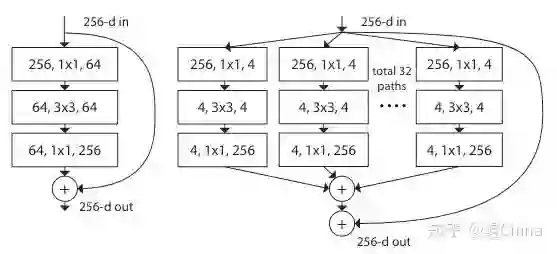
创新: 提出Group的概念、利用Group增加特征的丰富度和多样性,类似multi-head attention。
代码:! key是关键代码、其实就一行~
import torch.nn as nn
import torch.nn.functional as F
class Block(nn.Module):
"""Grouped convolution block."""
expansion = 2
def __init__(self, in_planes, cardinality=32, bottleneck_width=4, stride=1):
super(Block, self).__init__()
group_width = cardinality * bottleneck_width
self.conv1 = nn.Conv2d(in_planes, group_width, kernel_size=1, bias=False)
self.bn1 = nn.BatchNorm2d(group_width)
self.conv2 = nn.Conv2d(
group_width, group_width, kernel_size=3, stride=stride, padding=1, groups=cardinality, bias=False
) #! key
self.bn2 = nn.BatchNorm2d(group_width)
self.conv3 = nn.Conv2d(group_width, self.expansion * group_width, kernel_size=1, bias=False)
self.bn3 = nn.BatchNorm2d(self.expansion * group_width)
self.shortcut = nn.Sequential()
if stride != 1 or in_planes != self.expansion * group_width:
self.shortcut = nn.Sequential(
nn.Conv2d(in_planes, self.expansion * group_width, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(self.expansion * group_width),
)
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x)))
out = F.relu(self.bn2(self.conv2(out)))
out = self.bn3(self.conv3(out))
out += self.shortcut(x)
out = F.relu(out)
return out
(81.2% - 2016) Res2Net
论文: Res2Net: A New Multi-scale Backbone Architecture
(https://arxiv.org/pdf/1904.01169.pdf)
Blog: Res2Net:新型backbone网络,超越ResNet(https://zhuanlan.zhihu.com/p/86331579)
效果: ImageNet top-1 accuracy 81.23%
结构图:
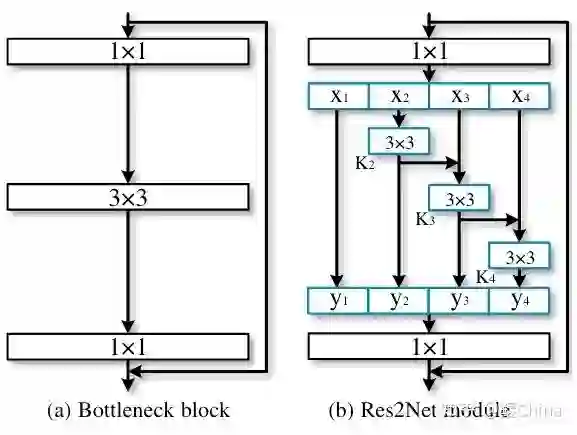
亮点: 将多特征图的处理从layer并行的形势改为hierarchical
代码: 因为修改了特征图的交互为hierarchical,所以代码有点多
class Bottle2neck(nn.Module):
expansion = 4
def __init__(self, inplanes, planes, stride=1, downsample=None, baseWidth=26, scale=4, stype="normal"):
"""Constructor
Args:
inplanes: input channel dimensionality
planes: output channel dimensionality
stride: conv stride. Replaces pooling layer.
downsample: None when stride = 1
baseWidth: basic width of conv3x3
scale: number of scale.
type: 'normal': normal set. 'stage': first block of a new stage.
"""
super(Bottle2neck, self).__init__()
# todo baseWidth, width, scale的含义
width = int(math.floor(planes * (baseWidth / 64.0)))
print(f"width : {width}")
self.conv1 = nn.Conv2d(inplanes, width * scale, kernel_size=1, bias=False)
print(f"width * scale : {width * scale}")
self.bn1 = nn.BatchNorm2d(width * scale)
# nums的含义
if scale == 1:
self.nums = 1
else:
self.nums = scale - 1
# todo stype的含义
if stype == "stage":
self.pool = nn.AvgPool2d(kernel_size=3, stride=stride, padding=1)
# 这里似乎是核心改进点
convs = []
bns = []
for i in range(self.nums):
convs.append(nn.Conv2d(width, width, kernel_size=3, stride=stride, padding=1, bias=False))
bns.append(nn.BatchNorm2d(width))
self.convs = nn.ModuleList(convs)
self.bns = nn.ModuleList(bns)
print(f"convs : {len(convs)}")
self.conv3 = nn.Conv2d(width * scale, planes * self.expansion, kernel_size=1, bias=False)
self.bn3 = nn.BatchNorm2d(planes * self.expansion)
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
self.stype = stype
self.scale = scale
self.width = width
print("============= init finish =============")
def forward(self, x):
residual = x
print(f"x : {x.shape}")
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
print(f"conv1 : {out.shape}")
spx = torch.split(out, self.width, 1)
for i in spx:
print(i.shape)
print(f"len(spx) : {len(spx)}")
for i in range(self.nums):
if i == 0 or self.stype == "stage":
sp = spx[i]
else:
sp = sp + spx[i]
print(f"sp : {sp.shape}")
sp = self.convs[i](sp)
sp = self.relu(self.bns[i](sp))
if i == 0:
out = sp
else:
out = torch.cat((out, sp), 1) # 相当于y2-y3-y4
if self.scale != 1 and self.stype == "normal":
out = torch.cat((out, spx[self.nums]), 1) # 相当于y1的部分
elif self.scale != 1 and self.stype == "stage":
out = torch.cat((out, self.pool(spx[self.nums])), 1)
out = self.conv3(out)
out = self.bn3(out)
if self.downsample is not None:
residual = self.downsample(x)
out += residual
out = self.relu(out)
return out
(81.3% - 2017) SENet
论文:[Squeeze-and-Excitation Networks]
(https://arxiv.org/abs/1709.01507)
Blog : 最后一届ImageNet冠军模型:SENet(https://zhuanlan.zhihu.com/p/65459972)
效果: ImageNet top-1 accuracy 81.3%
结构图:
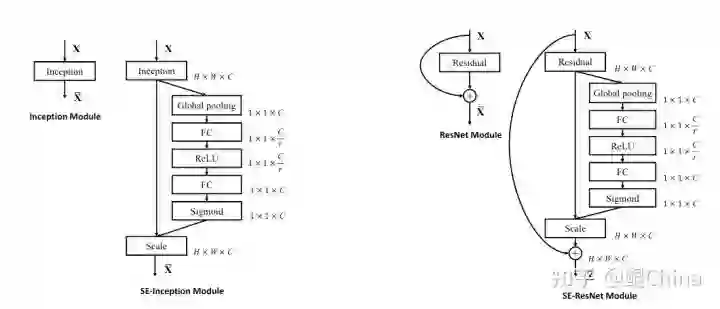
创新: 提出SELayer、利用可插拔的SELayer调节不同Channel的重要性,和Attention效果类似。
代码:
class SELayer(nn.Module):
def __init__(self, channel, reduction=16):
super(SELayer, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Sequential(
nn.Linear(channel, channel // reduction, bias=False),
nn.ReLU(inplace=True),
nn.Linear(channel // reduction, channel, bias=False),
nn.Sigmoid(),
)
def forward(self, x):
b, c, _, _ = x.size()
y = self.avg_pool(x).view(b, c) # 将(b,c,1,1)转换为(b,c)
y = self.fc(y).view(b, c, 1, 1) # 将(b,c)转换为(b,c,1,1), 方便做attention
return x * y.expand_as(x)
(80.1% - 2017) DPN
论文: Dual Path Networks
(https://arxiv.org/pdf/1707.01629.pdf)
Blog : DPN详解(Dual Path Networks)(https://zhuanlan.zhihu.com/p/351198007)
效果: ImageNet top-1 accuracy 80.07%
结构图:

创新:将resnet和densenet的思想做了结合。
代码:! key是关键代码、其实就一行~
class DPNBottleneck(nn.Module):
def __init__(self, last_planes, in_planes, out_planes, dense_depth, stride, first_layer):
super(DPNBottleneck, self).__init__()
self.out_planes = out_planes
self.dense_depth = dense_depth
self.conv1 = nn.Conv2d(last_planes, in_planes, kernel_size=1, bias=False)
self.bn1 = nn.BatchNorm2d(in_planes)
self.conv2 = nn.Conv2d(in_planes, in_planes, kernel_size=3, stride=stride, padding=1, groups=32, bias=False)
self.bn2 = nn.BatchNorm2d(in_planes)
self.conv3 = nn.Conv2d(in_planes, out_planes + dense_depth, kernel_size=1, bias=False)
self.bn3 = nn.BatchNorm2d(out_planes + dense_depth)
self.shortcut = nn.Sequential()
if first_layer:
self.shortcut = nn.Sequential(
nn.Conv2d(last_planes, out_planes + dense_depth, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(out_planes + dense_depth),
)
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x)))
out = F.relu(self.bn2(self.conv2(out)))
out = self.bn3(self.conv3(out))
x = self.shortcut(x)
d = self.out_planes
out = torch.cat(
[x[:, :d, :, :] + out[:, :d, :, :], x[:, d:, :, :], out[:, d:, :, :]], 1
) #! key + is residual, cat is dense
out = F.relu(out)
return out
(78.0% - 2019) DLA
论文: Deep Layer Aggregation
(https://larxiv.org/pdf/1707.06484.pdf)
效果: ImageNet top-1 accuracy **78%**,来自论文,但是我觉得效果应该至少是resnext级别的,至少他在cifar10上的表现是最好的,可参考 https://github.com/kuangliu/pytorch-cifar 的效果列表
结构图:
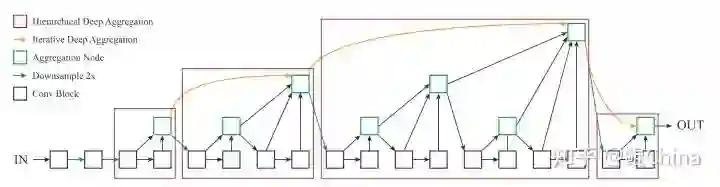
创新: 采用IDA和HDA两种结构来进一步提炼conv的表达
代码:
"""DLA in PyTorch.
Reference:
Deep Layer Aggregation. https://arxiv.org/abs/1707.06484
"""
import torch
import torch.nn as nn
import torch.nn.functional as F
# dla相当于只有HDA + IDA
class BasicBlock(nn.Module):
expansion = 1
def __init__(self, in_planes, planes, stride=1):
super(BasicBlock, self).__init__()
self.conv1 = nn.Conv2d(in_planes, planes, kernel_size=3, stride=stride, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(planes)
self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=1, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(planes)
self.shortcut = nn.Sequential()
if stride != 1 or in_planes != self.expansion * planes:
self.shortcut = nn.Sequential(
nn.Conv2d(in_planes, self.expansion * planes, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(self.expansion * planes),
)
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x)))
out = self.bn2(self.conv2(out))
out += self.shortcut(x)
out = F.relu(out)
return out
class Root(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size=1):
super(Root, self).__init__()
self.conv = nn.Conv2d(
in_channels, out_channels, kernel_size, stride=1, padding=(kernel_size - 1) // 2, bias=False
)
self.bn = nn.BatchNorm2d(out_channels)
def forward(self, xs):
x = torch.cat(xs, 1)
out = F.relu(self.bn(self.conv(x)))
return out
class Tree(nn.Module):
def __init__(self, block, in_channels, out_channels, level=1, stride=1):
super(Tree, self).__init__()
self.level = level
if level == 1:
self.root = Root(2 * out_channels, out_channels)
self.left_node = block(in_channels, out_channels, stride=stride)
self.right_node = block(out_channels, out_channels, stride=1)
else:
self.root = Root((level + 2) * out_channels, out_channels)
for i in reversed(range(1, level)):
subtree = Tree(block, in_channels, out_channels, level=i, stride=stride)
self.__setattr__("level_%d" % i, subtree)
self.prev_root = block(in_channels, out_channels, stride=stride)
self.left_node = block(out_channels, out_channels, stride=1)
self.right_node = block(out_channels, out_channels, stride=1)
def forward(self, x):
xs = [self.prev_root(x)] if self.level > 1 else []
for i in reversed(range(1, self.level)):
level_i = self.__getattr__("level_%d" % i)
x = level_i(x)
xs.append(x)
x = self.left_node(x)
xs.append(x)
x = self.right_node(x)
xs.append(x)
out = self.root(xs)
return out
class DLA(nn.Module):
def __init__(self, block=BasicBlock, num_classes=10):
super(DLA, self).__init__()
self.base = nn.Sequential(
nn.Conv2d(3, 16, kernel_size=3, stride=1, padding=1, bias=False), nn.BatchNorm2d(16), nn.ReLU(True)
)
self.layer1 = nn.Sequential(
nn.Conv2d(16, 16, kernel_size=3, stride=1, padding=1, bias=False), nn.BatchNorm2d(16), nn.ReLU(True)
)
self.layer2 = nn.Sequential(
nn.Conv2d(16, 32, kernel_size=3, stride=1, padding=1, bias=False), nn.BatchNorm2d(32), nn.ReLU(True)
)
self.layer3 = Tree(block, 32, 64, level=1, stride=1)
self.layer4 = Tree(block, 64, 128, level=2, stride=2)
self.layer5 = Tree(block, 128, 256, level=2, stride=2)
self.layer6 = Tree(block, 256, 512, level=1, stride=2)
self.linear = nn.Linear(512, num_classes)
def forward(self, x):
out = self.base(x)
out = self.layer1(out)
out = self.layer2(out)
out = self.layer3(out)
out = self.layer4(out)
out = self.layer5(out)
out = self.layer6(out)
out = F.avg_pool2d(out, 4)
out = out.view(out.size(0), -1)
out = self.linear(out)
return out
def test():
net = DLA()
print(net)
x = torch.randn(1, 3, 32, 32)
y = net(x)
print(y.size())
if __name__ == "__main__":
test()
(86.8% - 2021) EfficientNet v1 v2
论文:
-
EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks (https://arxiv.org/pdf/1905.11946v5.pdf) -
EfficientNetV2: Smaller Models and Faster Training (https://arxiv.org/pdf/2104.00298v3.pdf)
Blog :
-
令人拍案叫绝的EfficientNet和EfficientDet (https://zhuanlan.zhihu.com/p/96773680)
-
时隔两年,EfficientNet v2来了!更快,更小,更强!(https://zhuanlan.zhihu.com/p/361947957)
效果: ImageNet top-1 accuracy 86.8%
创新:是AutoDL在深度学习上一次非常成功的尝试
-
EfficientNet V1 uniformly scales all three dimensions(width, depth, resolution) with a fixed ratio。 -
EfficientNet V1 加入一些新block,扩大了搜索空间,并且不是equally scaling up every stage。
代码:
from torchvision.models import efficientnet_b0
model = efficientnet_b0()
个人愚见
其实这些年的CNN其实一直在尝试各种卷积的组合,从深度、宽度、注意力机制、各种Block组合形式上作文章,和传统机器学习的特征工程何其相似,只是需要更多的成本代价去尝试,大多都是经验性质的创新,原理上的不多,后面的VIT系列会有更多的一些创新,从整体设计上创造新的局面,但是也无法完全丢弃CNN,所以了解历史CNN的设计模式还是十分有必要的,本文理解有误的地方希望多多指正。

公众号后台回复“开学”获取CVPR、ICCV、VALSE等论文资源下载~
# CV技术社群邀请函 #

备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
极市&深大CV技术交流群已创建,欢迎深大校友加入,在群内自由交流学术心得,分享学术讯息,共建良好的技术交流氛围。
“
点击阅读原文进入CV社区
收获更多技术干货


