论文浅尝 | 基于多原型mention向量的文本-实体联合学习

链接:http://anthology.aclweb.org/P/P17/P17-1149.pdf
概述
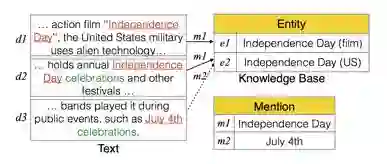
在知识库和文本的联合表示中,歧义是个困扰的难题。同一个 mention 可能在不同的语境下表述不同实体,同一个实体又有多种 mention 表示,如下图。本文提出了一个新的表示方法,可以在一个联合空间学习 mention 和实体的表示,同时解决歧义问题。
模型
作者提出了一个 mention sense 的概念,每一个 mention 对应一个 mention_sense,以表示当前的mention的真正含义。可以看出,mention_sense 是和实体一一对应的。作者从 wikipedia 的超链接里提取出 <m_l, e_j> 的组合,即mention超链接到某一实体。对于每一个这种组合,作者把它映射到一个 mention_sense 上:
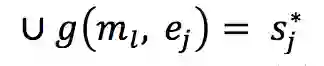
这样同一实体的 mention 会共享 mention_sense,而同一 mention 对应不同实体也会映射到不同的 mention_sense。作者把文本中的 mention 用 mention_sense 代替,来进行联合训练。
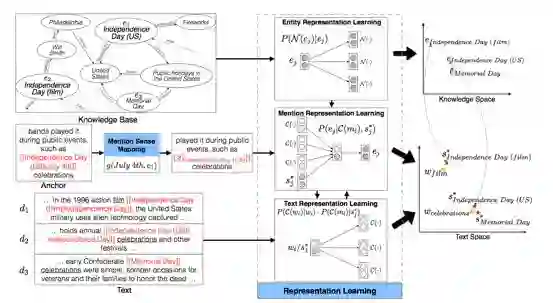
像大图的最右侧部分描述的一样,mention_sense 可以看成是文本空间和实体空间的一个链接。联合训练的似然函数由三部分组成,均采用 CBOW/skip-gram 的语言模型来得到向量:
1、实体空间
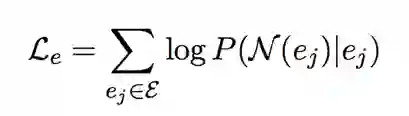
这个方法让共享邻居实体的实体词尽可能相似。
2、mention空间
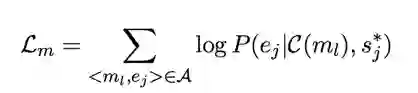
这个方法使得指向同一实体,且共享上下文的mention_sense尽可能相似。
3、文本空间
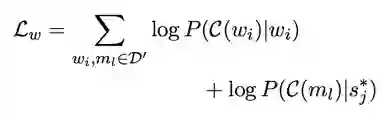
共现的词之间应尽可能相似,类似于 word2vec,只不过用 mention_sense 代替 mention。
实体链接
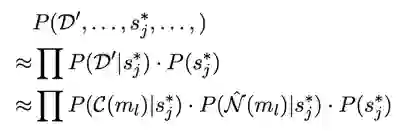
用上述学出的向量可以进行实体链接的工作。对于每一个实体,对所有 mention_sense 做如上计算,选出概率值最大的 mention_sense,再连接到对应的实体。因为一个句子可能包含多个实体,而全局优化代价过大,为了方便,作者假设实体和实体间独立,提出了 L2R(从左至右)和 S2C(从简至繁)的逐实体预测的方法。
实验
作者进行了自身对比,可以看出多实体比单一实体的效果好很多。
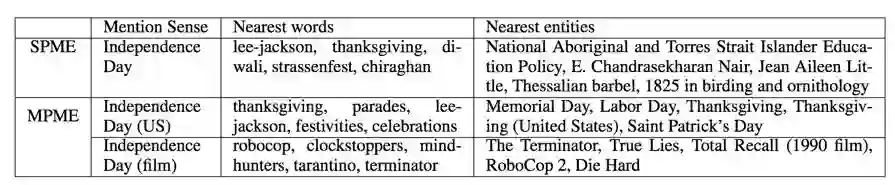
在实体相关预测和词语相关预测上,实体和词语联合学习的方法,也比单一学习提升了一些性能。
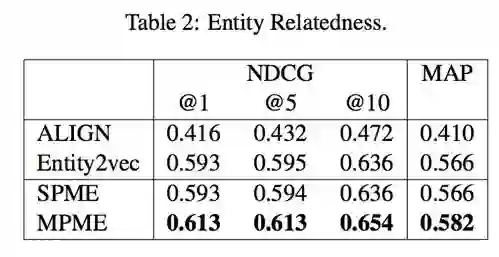
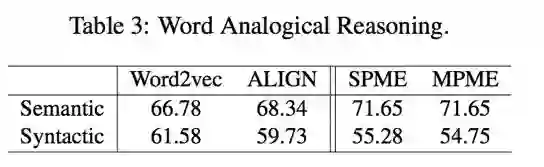
最后是上述实体链接的尝试:
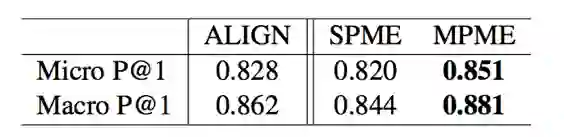
笔记整理:王冠颖,浙江大学硕士,研究方向为关系抽取、知识图谱。
OpenKG.CN
中文开放知识图谱(简称OpenKG.CN)旨在促进中文知识图谱数据的开放与互联,促进知识图谱和语义技术的普及和广泛应用。

转载须知:转载需注明来源“OpenKG.CN”、作者及原文链接。如需修改标题,请注明原标题。
点击阅读原文,进入 OpenKG 博客。




