【ICLR2022】Vision Transformer 模型工作机制的最新理论

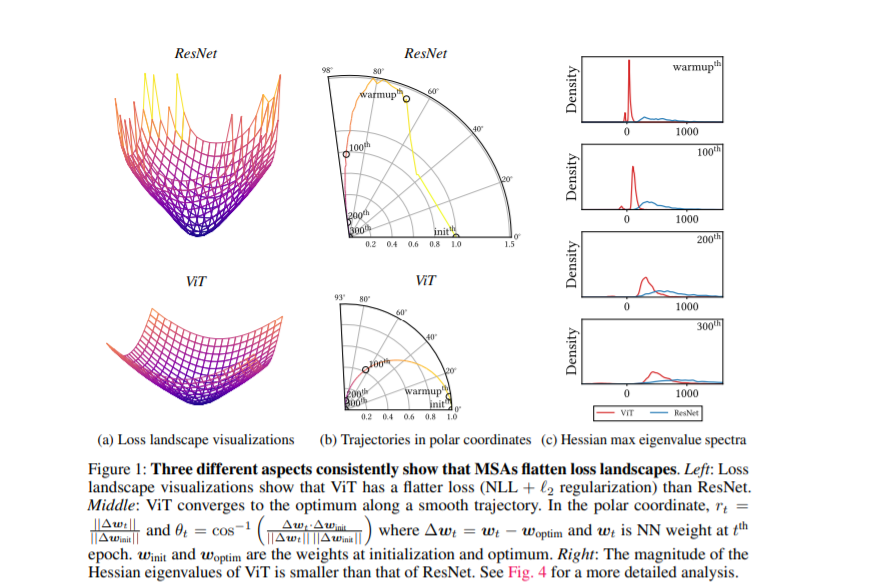
在深度神经网络之后,以多头自注意力机制为核心的Vision Transformer因其对输入全局关联的强大建模能力得到了广泛应用和研究。尽管现有研究在模型结构、损失函数、训练机制等方面提出了诸多改进,但少有研究对Vision Transformer的工作机制进行了深入探索。本文为ICLR 2022中的亮点论文之一,提供了不同解释来帮助理解Vision Transformer (ViT)的优良特性:1)多头自注意力机制不仅提高了精度,而且通过使损失的超平面变得平坦,提高了泛化程度;2)多头自注意力机制和卷积模块表现出相反的行为。例如,多头自注意力机制是低通滤波器,而卷积模块是高通滤波器;3)多层的神经网络的行为就像一系列小的个体模型的串联;4)最后阶段的卷积模块在预测中起着关键作用。
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“VT22” 就可以获取《【ICLR2022】Vision Transformer 模型工作机制的最新理论》专知下载链接



登录查看更多
相关内容





相关VIP内容
相关资讯