
【导读】Transformer系列的算法模型是当下研究的热点之一。基于Transformer的模型在自然语言处理、计算机视觉等领域得到了广泛的应用,最具代表性的就是作为预训练模型的核心构件,如BERT等。之前已经有相关系列Transformer综述。来自中科院计算所的研究人员从计算机视觉三个基本任务(分类、检测和分割)的角度对一百多种不同的视觉变换器进行了综述,值得关注。
摘要
Transformer 是一种基于注意力的编码器-解码器架构,彻底改变了自然语言处理领域。受这一重大成就的启发,最近在将类似 Transformer 的体系结构应用于计算机视觉 (CV) 领域方面进行了一些开创性工作,这些工作已经证明了它们在各种 CV 任务上的有效性。与现代卷积神经网络 (CNN) 相比,visual Transformers 依靠有竞争力的建模能力,在 ImageNet、COCO 和 ADE20k 等多个基准测试中取得了令人印象深刻的性能。在本文中,我们全面回顾了针对三个基本 CV 任务(分类、检测和分割)的一百多种不同的视觉变换器,其中提出了一种分类法来根据它们的动机、结构和使用场景来组织这些方法. 由于训练设置和面向任务的差异,我们还在不同的配置上评估了这些方法,以方便直观地进行比较,而不仅仅是各种基准测试。此外,我们揭示了一系列基本但未开发的方面,这些方面可能使 Transformer 从众多架构中脱颖而出,例如,松弛的高级语义嵌入以弥合视觉和顺序 Transformer 之间的差距。最后,提出了三个有前景的未来研究方向,以供进一步研究。
https://www.zhuanzhi.ai/paper/81663beebc3e71dadb416550ed549c65
引言
Transformer [1]作为一种基于注意力的结构,首次在序列建模和机器翻译任务中显示出巨大的力量。如图1所示,Transformer已经逐渐成为自然语言处理(NLP)的主要深度学习模型。最新的主流模型是一些自监督的变形金刚,预先从足够的数据集训练,然后在小而具体的下游任务[2]-[9]上进行微调。生成预训练Transformer (GPT)族[2]-[4]利用Transformer解码器执行自回归语言建模任务,而Transformer的双向编码器表示(BERT)[5]及其变体[6]、[7]作为构建在Transformer编码器上的自动编码器语言模型。
在计算机视觉(CV)领域,在视觉转换器模型之前,卷积神经网络(CNN)已经成为一个主导范式[10]-[12]。受NLP[1]和[13]中自注意力机制的巨大成功启发,一些基于CNN的模型试图通过一个额外的空间[14]-[16]或通道级别[17]-[19]的自注意力层来捕捉长期依赖。而另一些人则试图用全局[20]或局部自注意力块[21]-[25]来完全替代传统的卷积。虽然Cordonnier等人从理论上证明了自注意力块[26]的有效性和效率,但在主流基准上,这些纯注意力模型仍然不如当前最先进的(SOTA) CNN模型。
如上所述,基于注意力的模型在视觉识别领域受到了极大的关注,而vanilla Transformer在NLP领域取得了巨大的成功。受到这些启发,最近有许多作品将Transformer移植到CV任务中,并取得了可比性的结果。例如Dosovitskiy等人[27]提出了一种使用图像patch作为图像分类输入的纯Transformer,在许多图像分类基准上已经实现了SOTA。此外,visual transformer在其他CV任务中也取得了良好的性能,如检测[28]、分割[29]、跟踪[30]、图像生成[31]、增强[32]。如图1所示,在[27]、[28]之后,在过去的一年中,针对各个领域提出了数百种基于transformer的模型。因此,我们迫切需要一个系统的文献调研来识别、分类和批判性地评估这些新出现的视觉Transformer的表现。考虑到读者可能来自不同的领域,我们针对这些现有的视觉变形金刚进行三个基本的CV任务,包括分类、检测和分割。如图2所示,本综述将所有这些现有方法根据其任务、动机和结构特征分为多个组。其中一些可能部分重叠。例如,一些改进不仅提高了骨干在图像分类中的性能,而且还提高了密集预测任务(即检测和分割)的性能,许多深度和层次的方法也通过改进CNN和attention来实现。
去年发表了几篇关于Transformer的综述,Tay等[86]综述了Transformer在NLP中的效率,Khan等[87]和Han等[88]总结了早期的视觉变形和先前的注意力模型,以及一些没有系统方法的语言模型。Lin等人介绍了Transformer的最新综述,对Transformer的各种变体进行了系统的综述,并简要地提到了可视化应用[89]。基于这些观察,本文旨在对近期的视觉Transformer进行全面的回顾,并对现有的方法进行系统的分类:
(1)全面性和可读性。本文全面回顾了100多个视觉Transformers的三个基本任务:分类、检测和分割。我们选取并分析了50多个具有代表性的模型,如图2所示。我们不仅从单一的角度对每个模型进行详尽的分析,而且还通过递进、对比和多视角分析等意义来建立它们之间的内在联系。
(2)直观的比较。由于这些Transformers在不同的任务中遵循不同的训练方案和超参数设置,本综述通过将它们在不同的数据集和限制下分离,呈现了多个横向比较。在此基础上,我们总结了针对每个任务设计的一系列有前途的组件,包括: 基于层次结构的主干浅局部卷积,基于稀疏注意的空间先验加速,以及用于分割的通用掩模预测方案。
(3) 深入分析。我们进一步提供了以下方面的重要见解: 从顺序任务到视觉任务的转换过程,Transformer与其他视觉网络之间的对应关系,以及不同任务中可学习嵌入(即类标记、对象查询、掩码嵌入)的相关性。最后,展望了未来的研究方向。例如,编码器-解码器Transformer骨干可以通过学习嵌入来统一三个子任务。
本文的其余部分组织如下。第2节介绍了原始Transformer的概述架构和关键组件。第三章总结了Transformer 主干的综合分类,并简要讨论了图像分类。然后我们回顾了当代的Transformer检测器,包括第四节中的Transformer neck和backbone。第五节根据嵌入的形式(即patch embedding和query embedding),阐明了在分割领域中主流的Transformer变体。此外,第二章-第四章还简要分析了其相应领域的绩效评价的具体方面。第六章从三个方面进行了进一步的探讨,并指出了未来进一步研究的方向。
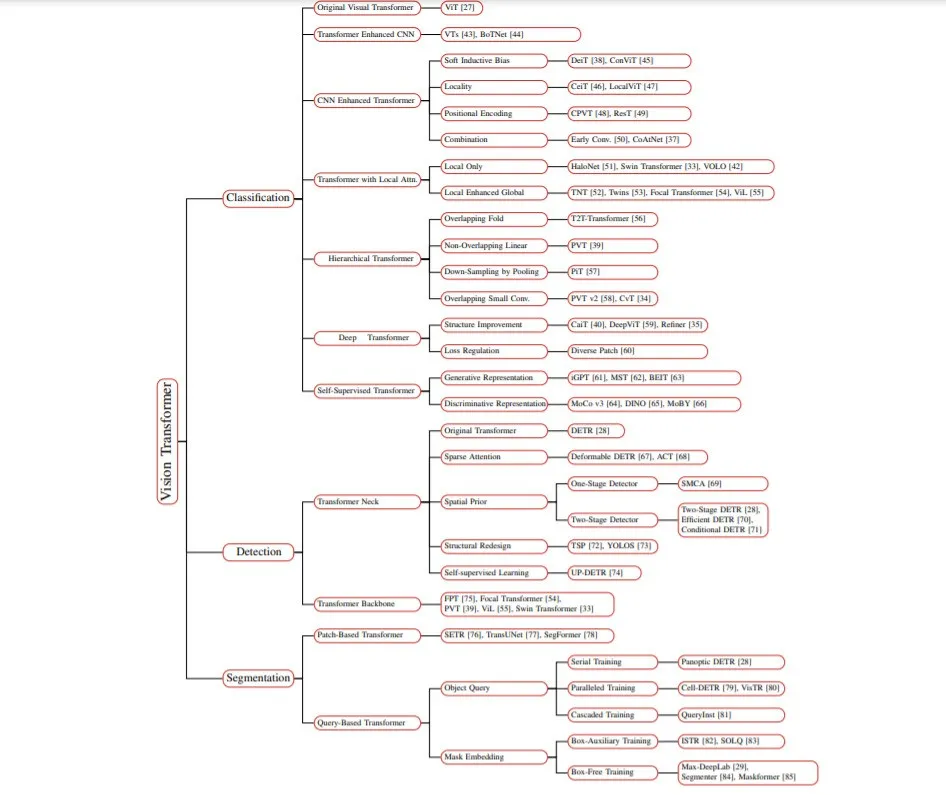
总结
在上述比较和讨论的基础上,我们现就以下三项基本任务近期的改进情况作一简要总结。
-
对于分类,一个深度层次的Transformer主干可以有效地降低计算复杂度[39],并在深度避免特征过平滑[35],[40],[59],[60]。同时,早期卷积[37]足以捕获低级特征,可以显著增强浅层的鲁棒性,降低计算复杂度。卷积投影[46]、[47]和局部注意力机制[33]、[42]都可以改善Transformer的局部性。[48]、[49]也可能是一种用位置编码替代的新方法。
-
在检测方面,Transformer骨干得益于编码器-解码器结构,比仅使用编码器的Transformer检测器计算更少[73]。因此,解码器是必要的,但由于其收敛速度慢[72],需要的堆栈很少[70]。此外,稀疏注意力[67]有利于降低计算复杂度,加速Transformer的收敛,而空间先验[67]、[69]、[71]则有利于Transformer的性能,收敛速度稍快。
-
对于分割,编码器-解码器Transformer模型可以通过一系列可学习的掩码嵌入[29],[84],[137],将三个分割子任务统一为一个掩码预测问题。这种无箱方法在多个基准上实现了最新的SOTA[137]。此外,还证明了基于box-based Transformer的特定混合任务级联模型[81]在实例分割任务中获得了更高的性能。

