
【导读】注意力机制是深度学习核心的构建之一,注意力机制是深度学习核心的构件之一,来自Mohammed Hassanin等学者发表了《深度学习视觉注意力》综述论文,提供了50种注意力技巧的深入综述,并根据它们最突出的特征进行了分类。

受人类认知系统的启发,注意力是一种模仿人类对特定信息的认知意识的机制,将关键细节放大,从而更多地关注数据的本质方面。深度学习已经在许多应用中运用了注意力来提高性能。有趣的是,同样的注意力设计可以适合处理不同的数据形式,并且可以很容易地并入大型网络。此外,多个互补注意力机制可以整合到一个网络中。因此,注意力技巧变得非常有吸引力。然而,文献缺乏对注意力技术的全面研究,以指导研究者将注意力运用到深度模型中。注意,除了在训练数据和计算资源方面的要求外,Transformers 在自注意力中只覆盖了许多可用类别中的一个类别。我们填补了这一空白,提供了50种注意力技巧的深入综述,并根据它们最突出的特征进行了分类。我们通过介绍成功注意力机制背后的基本概念来开始我们的讨论。接下来,我们提供了一些要素,如每种注意力类别的优势和局限性,描述了它们的基本构建模块,主要用途的基本公式,以及专门用于计算机视觉的应用。在此基础上,对注意力机制所面临的挑战和有待解决的问题进行了综述。最后,我们对未来可能的研究方向提出建议。
https://www.zhuanzhi.ai/paper/6e69019b739b12b44c0806f84e842412
引言
注意力与人类的认知系统有着天然的联系。根据认知科学,人类的视神经接收到的数据量超过了它的处理能力。因此,人脑对输入的信息进行权衡,只关注必要的信息。随着机器学习的最新发展,特别是深度学习,以及处理大型和多输入数据流的能力不断提高,研究人员在许多领域采用了类似的概念,并制定了各种注意机制,以提高机器翻译[1]、[2]、视觉识别[3],生成模型[4],多智能体强化学习[5]等。在过去的十年中,深度学习取得了突飞猛进的发展,导致许多深度神经网络架构能够学习数据中的复杂关系。一般来说,神经网络提供隐式注意力,从数据中提取有意义的信息。
在为机器翻译问题[6]设计的编码器-解码器架构中,首次引入了深度学习中的显式注意力机制来解决遗忘问题。由于网络的编码器部分侧重于生成一个代表性的输入向量,因此解码器从表示向量生成输出。采用双向回归神经网络[6]解决遗忘问题,从输入序列中生成上下文向量,然后根据上下文向量和之前的隐藏状态对输出进行解码。上下文向量由中间表示的加权和计算,这使得该方法成为显式注意力的一个例子。此外,利用LSTM[7]生成上下文向量和输出。两种方法都考虑到编码器的所有隐藏状态来计算上下文向量。然而,[8]引入了另一种思路,它让注意力力机制只关注隐藏状态的子集,从而生成上下文向量中的每个项。与之前的注意力方法相比,这种方法的计算成本较低,并显示了全局注意力机制和局部注意力机制之间的权衡。
另一个基于注意力的突破是由Vaswani et al.[2]提出的,他们基于自注意机制创建了一个完整的架构。输入序列中的项首先被并行编码为称为键、查询和值的多个表示。此体系结构(称为Transformer)有助于更有效地捕获输入序列中每个项相对于其他项的重要性。最近,许多研究人员对基本的Transformer架构进行了扩展,用于特定的应用。为了关注到图像中的重要部分并抑制不必要的信息,基于注意力的学习的进步已经在多个计算机视觉任务中找到了方法,要么对每个图像像素使用不同的注意力地图,将其与其他像素[3]、[4]、或生成一个注意力映射来提取整个图像[10],[11]的全局表示。然而,注意力机制的设计高度依赖于手头的问题。为了加强对输入中关键信息对应的隐藏状态的选择,注意力技术被用作基于视觉的任务中的插件单元,减轻了梯度消失的风险。综上所述,计算注意力分数,并确定或随机地选择隐藏状态。
在过去的几年里,注意力一直是重要的研究工作的中心,在许多不同的机器学习和视觉应用中,对图像注意力已经蓬勃发展,例如,分类[12],检测[13],图像描述[14],3D分析[15]等。尽管注意力技术在深度学习中的表现令人印象深刻,但目前还没有文献综述对所有的注意力机制(尤其是基于深度学习的视觉注意机制)进行全面的综述,并根据它们的基本底层结构对它们进行分类,突出它们的优缺点。最近,研究人员调研了特定于应用的注意力技术,重点是基于NLP的[16]、基于Transformer的[17]、[18]和基于图形的方法[19]。然而,目前还没有一项全面的研究对基于深度学习的注意力技术的进行广泛调研。
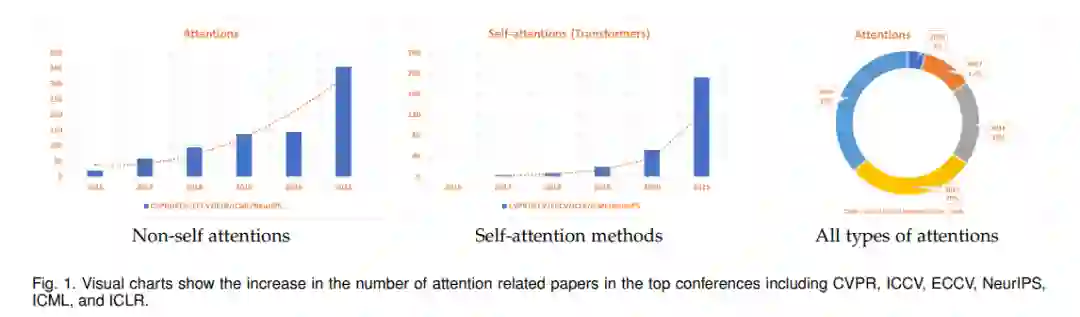
在本文中,我们回顾视觉注意力技术。我们的调研涵盖了许多基本的构建块(操作和功能)和完整的架构,这些架构旨在学习合适的表示,同时使模型注意到输入图像或视频中的相关和重要信息。我们的调研广泛地对计算机视觉文献中提出的注意力机制进行分类,包括软注意力、硬注意力、多模态、算术、类注意力和逻辑注意力。我们注意到有些方法不只属于一个类别;然而,我们将每个方法归入与该类别的其他方法有主要关联的类别。遵循这样的分类有助于跟踪常见的注意力机制特征,并提供了可能有助于设计新的注意力技术的见解。图2显示了注意力机制的分类。我们强调,由于大量的论文如图1所示发表,因此在视觉方面有必要注意力调研。从图1可以明显看出,去年发表的文章数量与往年相比明显增加,我们预计在未来几年也会有类似的趋势。此外,我们的综述列出了重要的文章,以帮助计算机视觉和机器学习社区在他们的模型中采用最合适的注意力机制,并避免重复的注意方法。它还确定了研究差距,提供了当前的研究背景,提出了合理的研究方向和未来的重点领域。
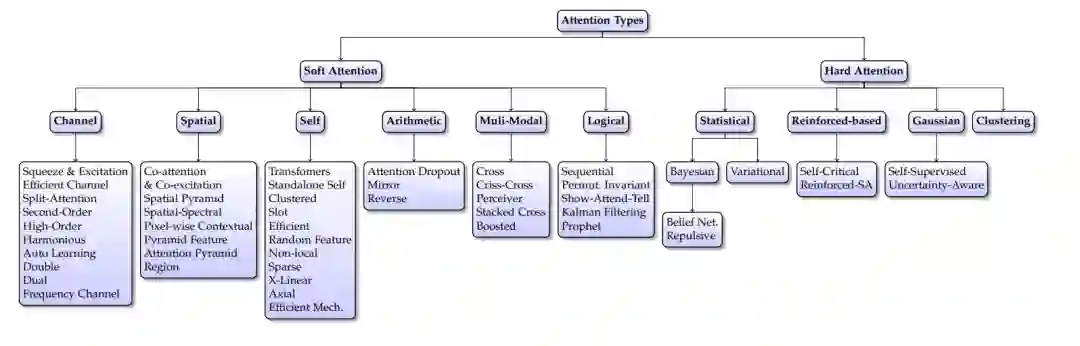
注意力类型的分类。根据注意力的执行方法对注意力进行分类。有些注意力技巧可以适用于多个类别;在这种情况下,注意力是根据最主要的特征和主要应用进行分组的。
由于transformers 已经在许多视觉应用中使用; 一些综述总结了transformers在计算机视觉中的最新趋势。尽管transformers 提供了很高的精度,但这是以很高的计算复杂度为代价的,这阻碍了其在移动和嵌入式系统应用中的可行性。此外,基于transformers 的模型比CNN需要更多的训练数据,缺乏有效的硬件设计和通用性。根据我们的综述,在被调研的50种不同的注意力类别中,transformers只涵盖了自注意力的一种类别。另一个显著的区别是,我们的调查关注的是注意力类型,而不是基于transformers的调查[17]、[18]所涵盖的应用。
视觉注意力
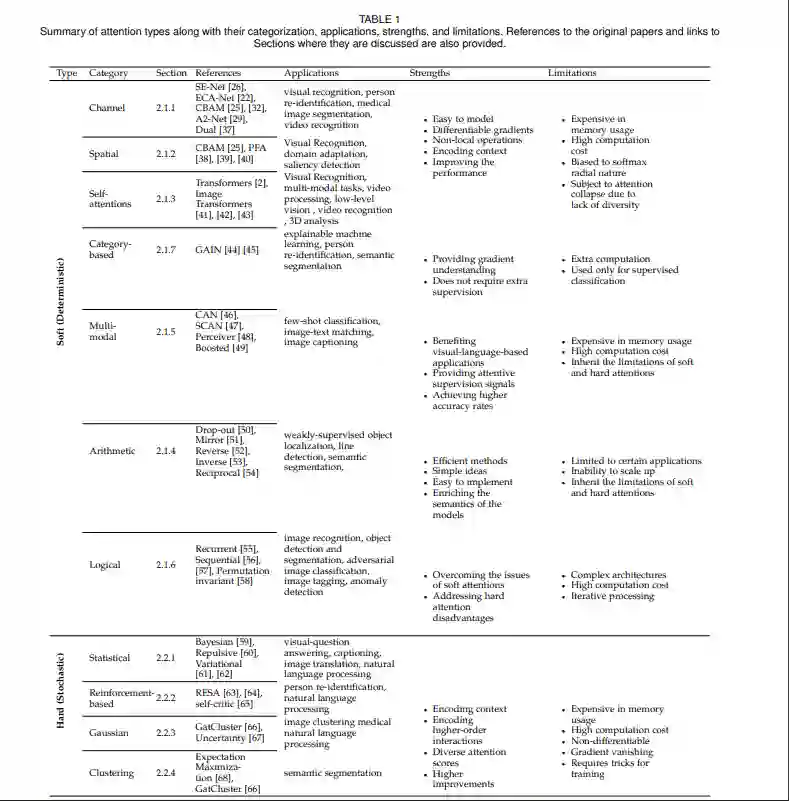
视觉中注意力的主要目的是模仿人类视觉认知系统,关注输入图像中的基本特征[20]。我们根据用于生成注意分数的主要功能对注意方法进行分类,如softmax或sigmoid。表1给出了这个综述类别的总结、应用、优点和局限性。
软注意力
本节回顾了软注意力方法,如通道注意力、空间注意力和自注意力。在通道注意力方面,分数是根据通道计算的,因为每个特征图(通道)都关注输入的特定部分。在空间注意力方面,主要思想是注意力图像中的关键区域。关注感兴趣的区域有助于对象检测、语义分割和人的重新识别。与通道注意力相反,空间注意力空间图中的重要部分(以宽度和高度为界)。它可以独立使用,也可以作为一种补充机制来引导注意力。另一方面,通过提取输入序列标记之间的关系,提出了自注意力对高阶交互和上下文信息进行编码。它与通道注意力在产生注意力分数的方式上不同,它主要计算相同输入的两个映射(K, Q)之间的相似性,而通道注意从单个映射图产生分数。然而,自注意力和通道注意力都在通道上起作用。软注意力方法主要使用softmax、sigmoid等软函数,以所有输入实体[8]加权和计算注意力得分。由于这些方法是可微的,它们可以通过反向传播技术进行训练。然而,它们还面临着其他问题,如高计算复杂度和为无参与对象分配权重。
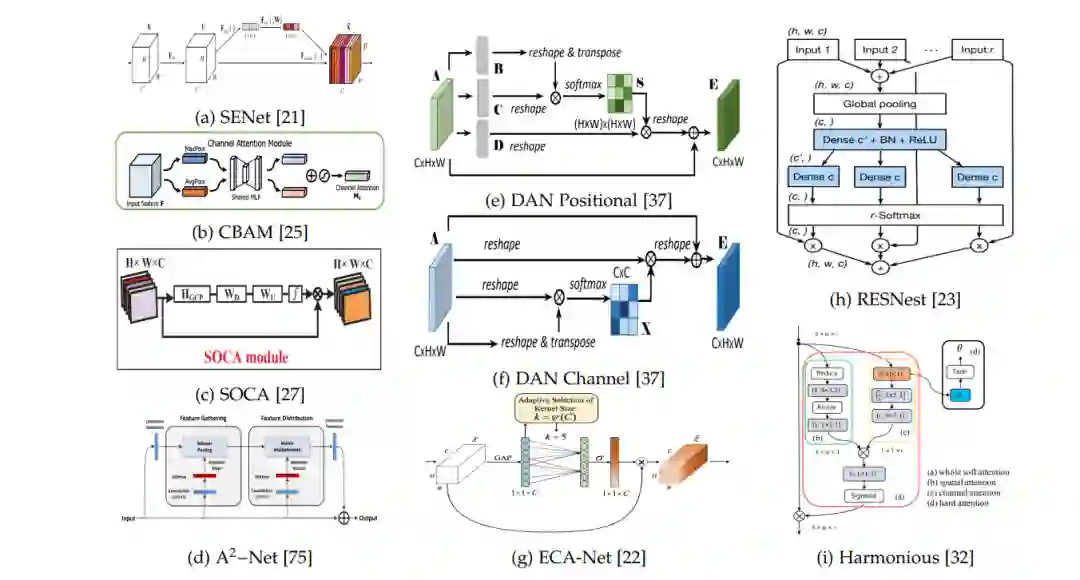
基于通道注意力方法的核心结构。
硬(随机)的注意力
不是使用隐藏状态的加权平均,硬注意力选择其中一个状态作为注意力得分。提出硬注意力取决于回答两个问题: (1) 如何对问题建模,以及 (2) 如何在不消除梯度的情况下训练它。在这一部分中,讨论了硬注意力的方法及其训练机制。它包括贝叶斯注意、变分推理、强化注意力和高斯注意力的讨论。贝叶斯注意力与变分注意力的主要思想是将潜在随机变量作为注意力分数。强化注意力用伯努利-Sigmoid单位代替Softmax[174],而高斯注意力则使用二维高斯核来代替。同样,自注意力[65]使用一种强化技术来生成注意力分数,而期望-最大化使用EM来生成分数。
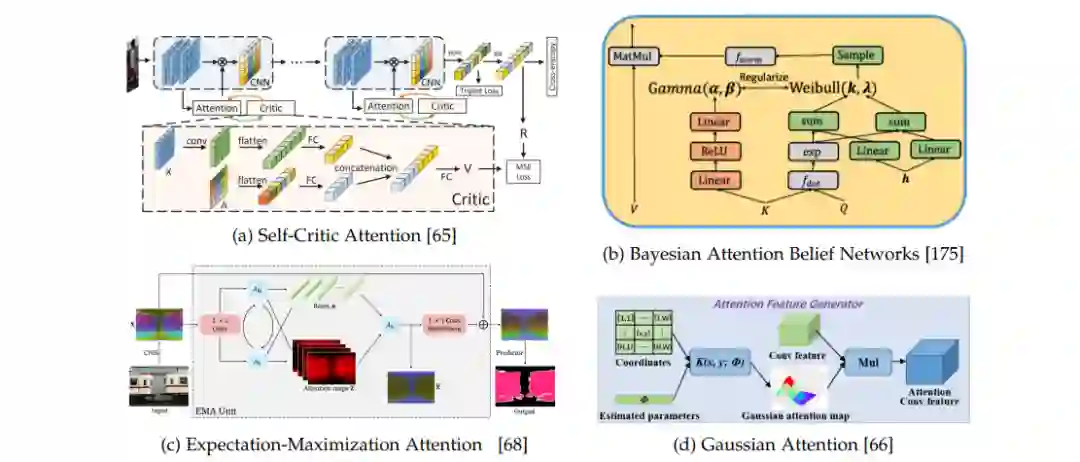
硬注意力架构
