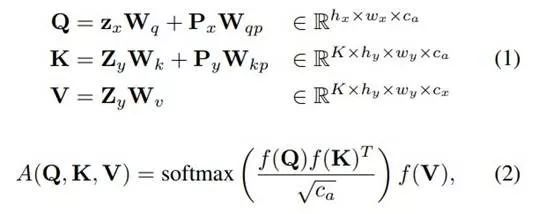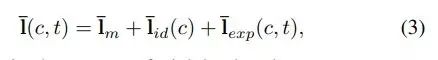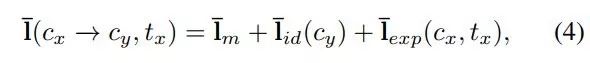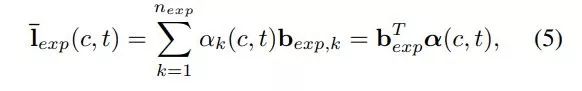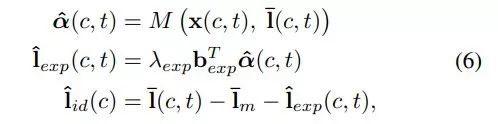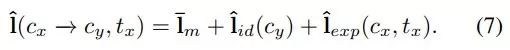选自arXiv
作者:Sungjoo Ha等人
机器之心编译
参与:魔王、张倩
还记得几年前火遍全网的「小咖秀」吗?在那个应用中,大家可以配合 APP 提供的音频、字幕像唱 KTV 一样创作搞怪视频,可谓过足了戏瘾。那如果反过来让大咖们模仿你呢?是不是更过瘾?
近日,韩国初创公司 Hyperconnect 就提出了这样一款「大咖秀」AI 模型,可以让爱因斯坦、奥黛丽·赫本、杰克马等一众大咖模仿你的面部表情和动作。
![]()
![]()
![]()
Hyperconnect 公司提出的这一模型名为 MarioNETte,原义为「牵线木偶(marionette)」。
顾名思义,这款应用实现的操作就是对目标人物的「操控」。
而且实现起来非常简单,只需要目标人脸(即上图中的川普、杰克马等人)的少量照片+给出动作的人物视频(即上图中最左边的韩国小哥,论文中叫做「驱动人脸」),合成人物的逼真度和各项指标都超越了之前的 few-shot 方法。
该模型是人脸重现(face reenactment)技术的一种。
给出目标人脸和驱动人脸(driver face),人脸重现技术将合成一张「新」的脸,这张脸具备驱动人脸的动作,同时保留目标人脸的身份特征。
当然,这种「大咖秀」技术并非韩国研究者首创。
之前的研究者利用 CycleGAN 或其他 few-shot 方法来实现这一目标,但方法各有缺陷。
有人利用 CycleGAN 实现了高度逼真的人脸重现结果。
但是,基于 CycleGAN 的方法需要好几分钟来处理每个目标的训练数据,且仅能对预定义人物执行人脸重现,而需要重现未见过目标的情况在现实环境中在所难免,因此,这些方法对于现实应用缺乏吸引力。
few-shot 人脸重现方法试图利用自适应实例归一化(adaptive instance normalization,AdaIN)或变形模块(warping module)等操作,重现没见过的目标。
但是,当前最优的方法会遭遇如何保留人物身份的问题,即无法保留目标人脸的身份信息,导致重现结果出现瑕疵。
而当驱动人脸的身份不同于目标人脸时,这个问题变得更加严重了。
图 1 展示了有问题的人脸重现和成功的人脸重现示例,它们分别来自之前的方法和韩国初创公司 Hyperconnect 提出的新方法。
其中,之前方法的失败大致可以归类为以下三种不同模式:
忽视身份不匹配,可能导致驱动人脸的身份干扰人脸合成,使得生成人脸与驱动人脸相似(图 1a);
压缩向量表征(如 AdaIN 层)无法保留目标人物的身份信息,可能导致生成的人脸丢失具体的特征(图 1b);
在处理大动作时,变形操作出现问题(图 1c)。
![]()
图 1:
人物身份信息保留失败的示例 vs 新方法生成的改进结果。
Hyperconnect 提出一个新框架 MarioNETte,旨在以 few-shot 的方式重现未见目标人脸,同时保留其身份特征。
研究者采用图像注意力模块和目标特征对齐,使 MarioNETte 在生成图像时直接注入目标人脸的特征。
此外,研究者还提出了新型关键点 transformer(landmark transformer),用无监督的方式调整人脸身份不匹配的问题,进而缓解保留目标人脸身份特征的问题。
研究者分别在 VoxCeleb1 和 CelebV 数据集上,对比了当目标人脸和驱动人脸重合及不同时当前最优方法的性能。
实验包括用户调查,实验结果表明,MarioNETte 方法优于之前最优的方法。
![]()
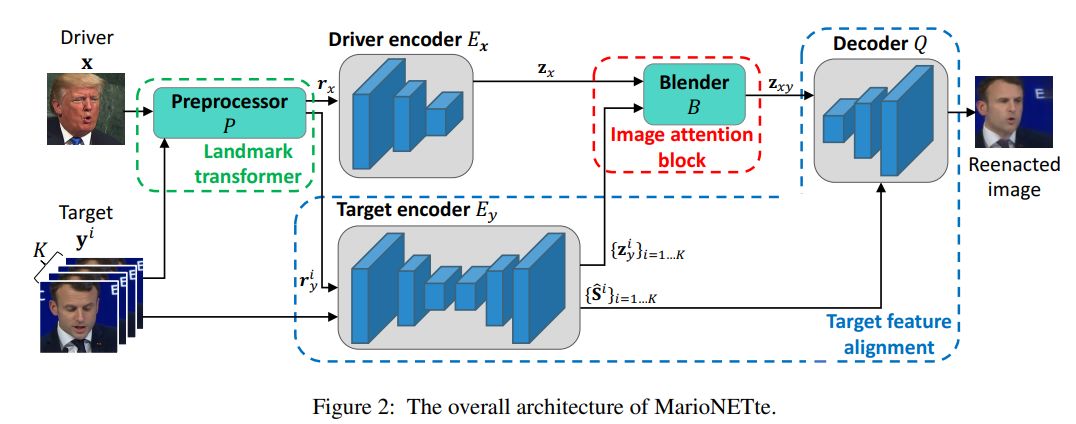
图 2 展示了 MarioNETte 模型的整体架构:
![]()
条件生成器 G 基于驱动人脸 x 和目标人脸 {y^i}_i=1...K 生成重人脸重现结果,判别器 D 预测该图像的真伪。
为了将目标人脸的风格信息迁移至驱动人脸,之前研究的解决方案是:
将目标信息编码为向量,并通过级联或 AdaIN 层将其与驱动人脸的特征混合。
但是,将目标编码为空间无关向量(spatial-agnostic vector)会导致目标人脸丢失空间信息。
此外,这些方法本身不针对多个目标图像,因而常使用其描述性统计(如均值或最大值)来处理多目标的情况,而这可能导致目标细节的丢失。
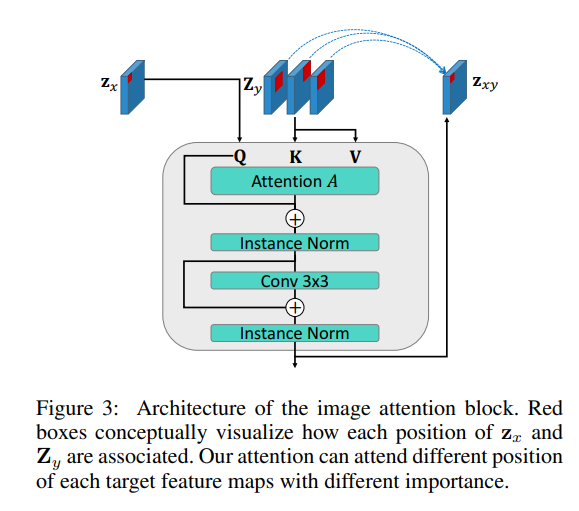
研究者提出图像注意力模块(见图 3)来缓解前述问题。
该模块受到 transformer 的编码器-解码器注意力的启发,在该模块中驱动特征图作为注意力 query,目标特征图作为注意力记忆。
该模块关注每个特征的恰当位置(图 3 红框),同时处理多个目标特征图(即 Z_y)。
![]()
给出驱动特征图
![]() 和目标特征图
和目标特征图
![]() ,
用以下方式计算注意力:
,
用以下方式计算注意力:
![]()
注意力层后面是实例归一化、残差连接和卷积层,用于生成输出特征图 z_xy。
图像注意力模块提供了一种将多个目标图像的信息直接迁移至驱动人脸姿势的机制。
目标人脸身份的细粒度细节可以通过对低级特征的变形来保存。
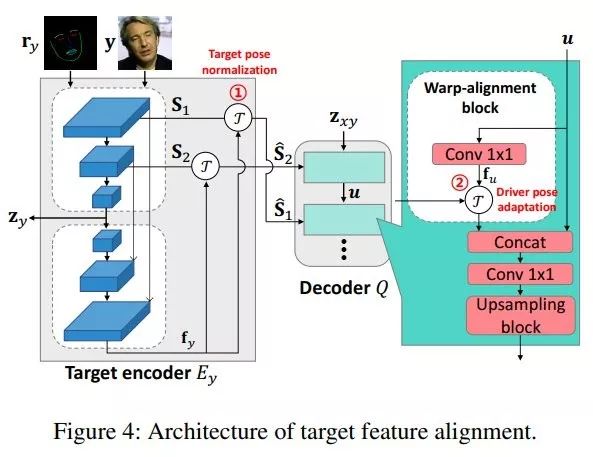
之前方法通过计算目标人脸和驱动人脸的关键点区别来估计变形流图(warping flow map)或仿射变换矩阵,而 Hyperconnect 研究者独辟蹊径,提出目标特征对齐(见图 4),按两个阶段将目标特征图变形:
1)目标姿势归一化,用于生成姿势归一化的目标特征图;
2)驱动姿势适应(driver pose adaptation),即将归一化的目标特征图与驱动人脸的姿势对齐。
该流程使得模型能够更好地处理不同人脸的结构差异。
![]()
两个人脸关键点之间的巨大结构差异可能导致人脸重现质量严重下降。
该问题的常规解决方案是为每一个人脸学习一种变换,或者准备一份具备相同表情的成对关键点数据。
但是,这些方法在 few-shot 设置中不太现实(因为需要处理未见人脸),而且我们很难获得标注数据。
为了克服这一难题,Hyperconnect 研究者提出一种新型关键点 transformer,将驱动人脸的面部表情迁移至随机的目标人脸。
关键点 transformer 利用无标注人脸的多个视频,以无监督形式训练。
关键点分解(landmark decomposition)
给出不同人脸的视频片段,将第 c 个视频的第 t 帧表示为 x(c, t),将 3D 关键点表示为 l(c, t)。
研究者首先通过统一尺度、平移和旋转,将每个关键点转换为归一化关键点 ¯l(c, t)。
受人脸 3D 形变模型的启发,研究者假设归一化关键点可被分解为以下形式:
![]()
给出目标关键点 ¯l(c_y, t_y) 和驱动关键点 ¯l(c_x, t_x),研究者希望生成如下关键点:
![]()
即既具备目标人脸身份特征又拥有驱动人脸表情的关键点。
当具备足够多的 c_y 图像时,我们可以计算 ¯l_id(c_y) 和 ¯l_exp,但在 few-shot 设置下,我们很难将未见图像的关键点解耦为两项。
关键点解耦(landmark disentanglement)
为了在 few-shot 设置下解耦人脸身份和表情几何,研究者提出一种神经网络,为线性 base 提供系数。
之前,此类方法已经广泛应用于建模复杂人脸几何的任务中。
研究者将表情关键点分割为多个人脸语义组(如嘴、鼻子和眼睛),并对每个组执行 PCA,进而从训练数据中提取表情 base:
![]()
该神经网络(即关键点解耦器 M)基于图像 x(c, t) 和关键点 ¯l(c, t) 估计 α(c, t)。
图 5 展示了该关键点解耦器的架构。
模型训练完成后,我们可以按照以下方式计算人脸身份和表情几何:
![]()
在推断过程中,根据公式 6 处理目标关键点和驱动关键点。
当给出多个目标图像时,我们对所有 ˆl_id(c_y) 取均值。
最后,关键点 transformer 将关键点转换为:
![]()
栅格化之后是去归一化,即恢复原有的尺度、平移和旋转,从而为生成器生成适合的关键点。
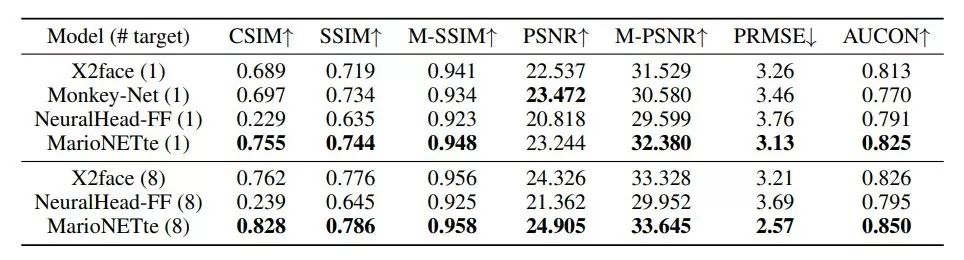
表 1 展示了模型在 VoxCeleb1 数据集上的自重现结果。
在 few-shot 设置下,MarioNETte 在每个度量指标上的性能均超越其他模型;
在 one-shot 设置下,MarioNETte 也在每个度量指标(PSNR 除外)上超越了其他模型。
而且 MarioNETte 实现了最好的 M-PSNR 性能,这表明它在人脸区域上的性能优于基线模型。
NeuralHead-FF 的低 CSIM 得分间接证明了基于 AdaIN 的方法缺乏能力。
![]()
表 1:
在 VoxCeleb1 数据集上的自重现评估结果。
(向上/向下的箭头表示该度量指标值越高/低越好。
)
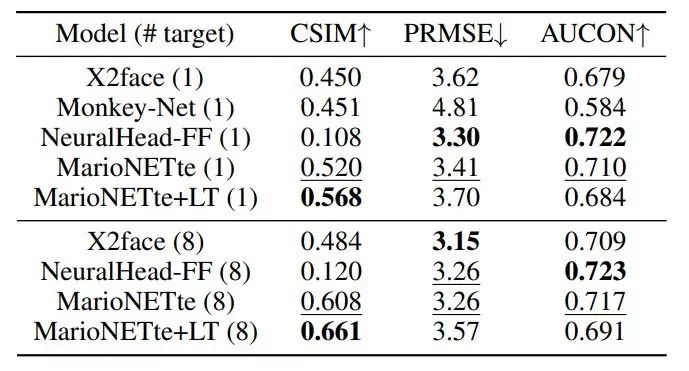
表 2 展示了在 CelebV 数据集上对不同人物执行人脸重现的评估结果,图 6 展示了 MarioNETte 和基线方法生成的图像。
MarioNETte 和 MarioNETte+LT 恰当地保存了目标人脸的身份信息,因此它们的 CSIM 性能优于其他模型。
![]()
表 2:
在 CelebV 数据集上对不同人物执行人脸重现的评估结果。
粗体和带下划线的数字分别对应每个指标的最优和次优值。
![]()
图 6:
以 one-shot 设置对不同人物执行人脸重现时,MarioNETte 方法和基线方法生成的图像。
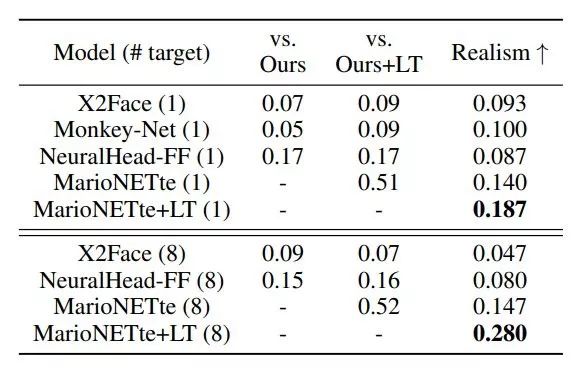
表 3 展示了 MarioNETte 模型比已有方法更受用户欢迎,其逼真度分数也比其他方法高出一截。
这一结果表明,MarioNETte 能够创建逼真的人脸重现结果,同时保留目标人脸的身份信息。
![]()
表 3:
在 CelebV 数据集上对不同人物执行人脸重现的用户调查结果。
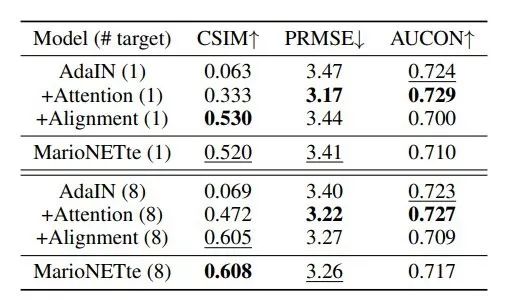
表 4 展示了控制变量实验的结果。
对于人物身份保留问题(即 CSIM),仅依赖 AdaIN 残差模块的 AdaIN 方法很难结合风格特征。
+Attention 通过关注合适的坐标,在 one-shot 和 few-shot 设置中都极大地缓解了这一问题。
+Alignment 的 CSIM 分数比+Attention 更高,但是它很难为未见过的姿势和表情生成合理的图像,因而其 PRMSE 和 AUCON 性能较差。
MarioNETte 利用了注意力和目标特征对齐,其在每一个度量指标上的性能均优于 +Alignment。
![]()
表 4:
控制变量模型在 CelebV 数据集上对不同人物执行人脸重现的性能对比。
![]()
图 7:
a)驱动图像和目标图像与注意力图重叠。
光泽处表示注意力密集的地方。
b)+Alignment 的失败案例和 MarioNETte 生成的结果。
「WAIC 开发者·临港人工智能开发者大会」将于 2019 年 12 月 6 日-7 日在上海临港举办。本次大会设有主题演讲、开发者工作坊、开发者挑战赛、技术和产业闭门研讨会等环节。邀请全球AI开发者在现场:听前沿理论+学实战干货+动手挑战赛。点击阅读原文,立即报名。
![]()





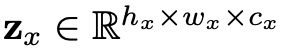 和目标特征图
和目标特征图
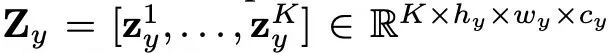 ,
用以下方式计算注意力:
,
用以下方式计算注意力: