降维打击:这款GAN可以让真人「二次元化」
选自arXiv
作者:Kaidi Cao、Jing Liao、Lu Yuan
机器之心编译
来自清华、香港城市大学和微软的研究者最近提出了 CariGAN,可以在没有成对图像的情况下将真人照片自动转换成形式夸张的漫画。目前这篇论文已经被 SIGGRAPH Asia 2018 大会收录。
漫画可被定义为通过素描、铅笔笔画或其他艺术形式以简化或夸大的形式描绘人物的形式(通常是面部)。作为传达幽默或讽刺的一种形式,漫画通常用于娱乐,作为礼品或纪念品,也可由街边艺术家创作。艺人可以从被画者面部捕捉到独特的特征,并进行夸大和艺术化。
众所周知,我们能看到的绝大多数照片和漫画的例子都是不成对的,所以直接进行「翻译」是不可行的,我们无法通过有监督学习来训练计算机实现这种风格迁移,如自编码器、Pix2Pix,或是其他适用于成对图像的神经网络。

图 1. 人脸漫画化结果对比。(b)为手绘漫画,(c)为风格迁移自动生成,(d)为 CycleGAN,(e)和(f)为新论文的结果。其中(d)(e)(f)都是在同一个数据集上进行训练的。
总而言之,生成漫画有两个关键:形状夸张和外观风格化,如图 1 (a)(b) 所示。在这篇论文中,研究者提出了一个用于非成对图像到漫画转换的 GAN,他们将其称之为「CariGANs」。该网络会使用两个组件以明确模拟人脸漫画的几何夸张形状和外观风格。
其中 CariGeoGAN 只建模几何到几何的形状转换,即人脸图像形状到人脸漫画形状的转换。另外一个组件 CariStyGAN 会将漫画中的外表风格转换到人脸图像中,并且不产生任何几何形变。两个 GAN 进行独立的训练,这可以令学习过程更加鲁棒。
为了构建非成对图像间的关系,CariGeoGAN 和 CariStyGAN 都使用 cycle-consistency 的网络结构,它广泛应用于交叉领域或无监督图像转换任务中。最后,夸张的形状对经过风格迁移的人脸进行变形,从而获得最终的输出结果。
CariGeoGAN 使用人脸特征点的 PCA 表征作为 GAN 的输入和输出。该表征隐性地强制执行该网络中较为重要的人脸形状约束。此外,研究者还在 CariGeoGAN 中考虑新的特征损失(characteristic loss),以鼓励独特人脸特征的夸张表达,避免不规则失真。CariGeoGAN 输出人脸特征点位置,而不是图像,这样在图像实现形状变形之前可以调整夸张程度。这使得输出结果可控,且具备几何形状多样性。
至于风格,CariStyGAN 用于像素到像素的迁移,不会产生任何几何变形。为了排除训练 CariStyGAN 时的几何推断,研究者通过 CariGeoGAN 的逆几何映射将所有原始漫画变形为人脸图像的形状,从而创建中间漫画数据集。
总体而言,本文的贡献可以总结为以下几点:
展示了非成对照片到漫画转换的首个深度神经网络。
展示了用于几何夸张的 CariGeoGAN,是使用 cycle-consisteny 的 GAN 实现几何形状跨域转换的首次尝试。
展示了用于外观风格化的 CariStyGAN,允许多模态图像转换,同时通过添加感知损失保留生成漫画的一致性。
该 CariGAN 允许用户仅通过调参或给出一个示例漫画来控制几何形状与外观风格中的夸张程度。
论文:CariGANs: Unpaired Photo-to-Caricature Translation

论文链接:https://arxiv.org/pdf/1811.00222.pdf
摘要:人脸漫画是一种用夸张手法传递幽默感或讽刺性的人脸绘画艺术形式。本研究提出首个用于非成对图像转漫画的生成对抗网络(GAN)——CariGANs。它显性地使用两个组件建模几何夸张线条和外观风格:CariGeoGAN,仅建模从人脸图像到漫画的几何变换;CariStyGAN,将漫画的外观风格迁移到人脸图像,且不存在任何几何变形。通过这种方式,一个困难的跨域转换问题被分解成两个较为简单的任务。从感官角度来看,CariGANs 生成的漫画与人类手绘的漫画相差无几,同时与当前最优的方法相比,CariGANs 生成的漫画更好地保存了人脸特征的一致性。此外,CariGANs 允许用户调整参数或者为用户提供示例漫画,从而使用户可以控制几何线条夸张程度、改变漫画的颜色/纹理风格。
方法
就漫画生成而言,之前基于示例学习的方法对成对图像-漫画数据非常依赖,需要艺术家为每张图像绘制对应的漫画。因此构建这样的成对图像数据集是不可行的,因为成本极高且需要花费大量时间。而本文提出的方法如下图所示利用两个 GAN 分别学习几何形变与风格,从而借助 CycleGAN 的思想处理非成对图像的转换。

图 2:本研究提出方法的整体流程图。输入图像来自 CelebA 数据集。

图 3:第一行图像是来自人像数据库的部分样本,第二行是漫画。
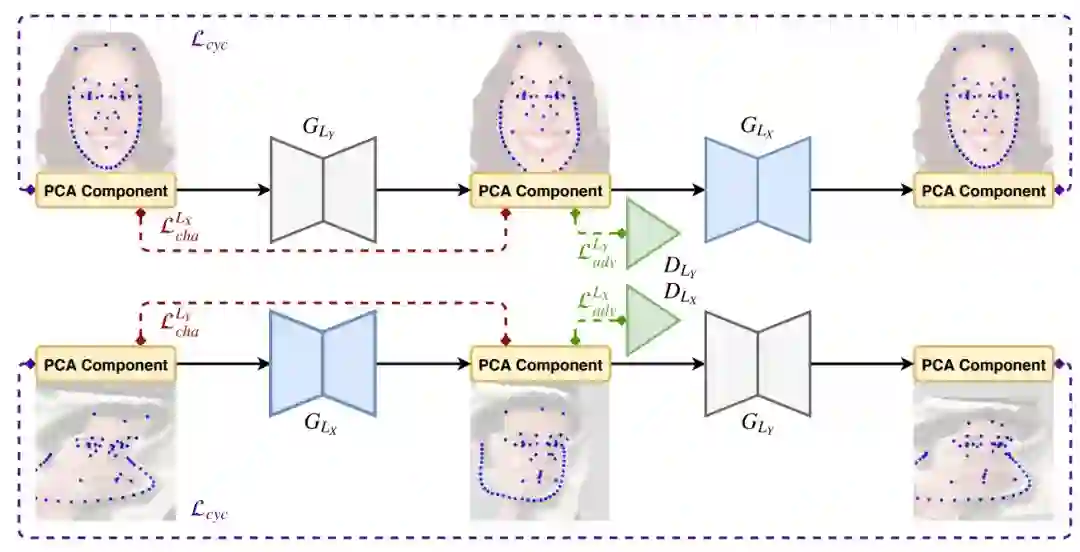
图 4:CariGeoGAN 的架构。它基本上遵循 CycleGAN 的网络结构,cycle Loss 为 L_cyc,对抗损失为 L_gan。但是我们的输入和输出是向量而非图像,我们添加了 characteristic loss L_cha 以增加人物的独特特征。
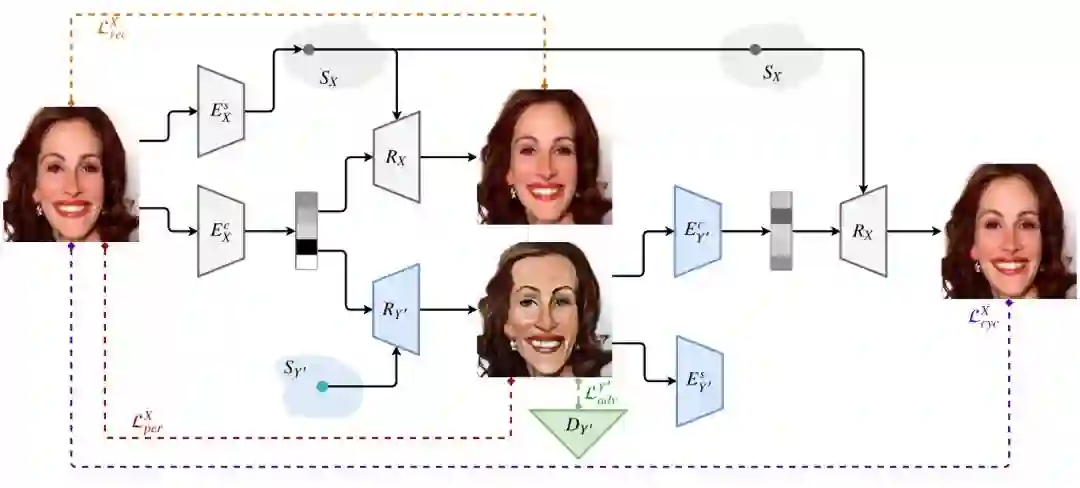
图 8:CariStyGan 架构。为简洁起见,此处我们仅展示了 X → Y ′ 变换的网络架构。Y ′ → X 变换的网络架构与该架构对称。输入图像来自 CelebA 数据集。

图 7:CariStyGAN 与 CycleGAN 和 MUNIT 的对比。所有网络使用同样的数据集进行训练来学习外观风格映射 X ⇒ Y ′。
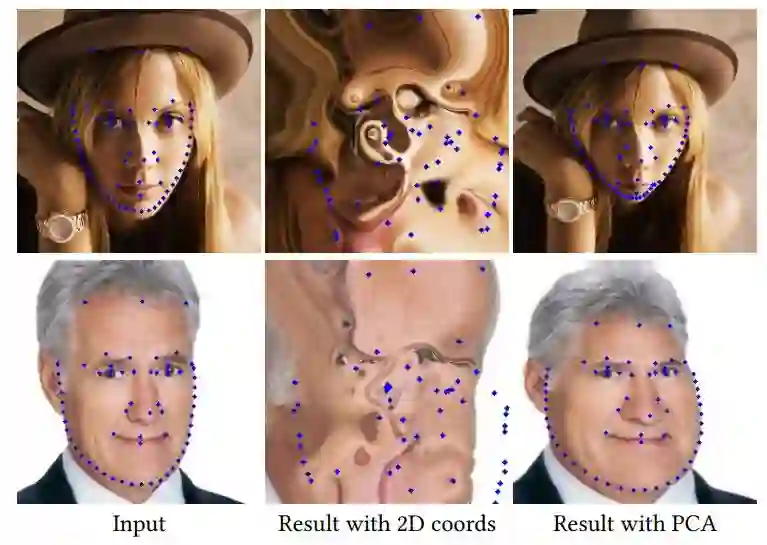
图 10:在 CariGeoGAN 中使用 PCA 表征和使用 2D 坐标的对比。输入图像来自 CelebA 数据集。
对比和结果

图 12:风格嵌入系统的 T-SNE 可视化。其中灰点表示图像、红点表示手绘的人脸漫画、绿点表示生成的结果。一种不同点所对应的示例图像以对应的色彩框标注出来。

图 16:对比基于深度学习的人脸漫画方法,从左到右分别为两种一般的图像风格迁移方法、两种基于面部特性的风格迁移方法、两种单模型图像转换网络和多模态图像转换网络(MUNIT)。输入图像都选自 CelebA 数据集中,但除去了用于训练的 10K 张图像。

本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com



