让大卫雕塑跳舞、蒙娜丽莎说话,英伟达视频合成有如此多「骚操作」
机器之心报道
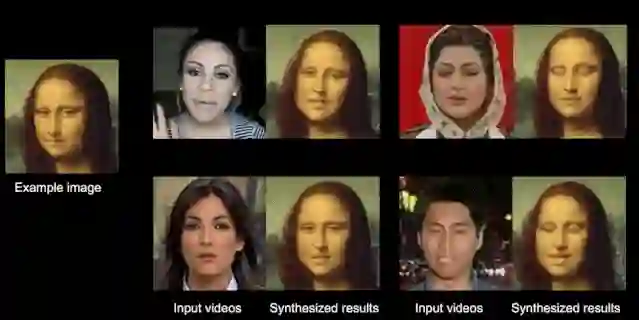
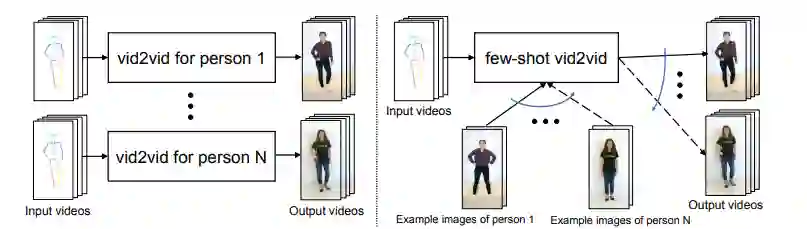
用视频到视频的合成技术生成会跳舞的小哥哥(小姐姐) 或自己本人已经不是什么无法解决的问题,但这些方法通常需要大量目标人物的数据,而且学到的模型泛化能力相对不足。为了解决这个问题,来自英伟达的研究者提出了一种新的 few-shot 合成框架,仅借助少量目标示例图像就能合成之前未见过的目标或场景的视频,在跳舞、头部特写、街景等场景中都能得到逼真的结果。该论文已被 NeurIPS 2019 接收。
论文:https://nvlabs.github.io/few-shot-vid2vid/main.pdf
项目代码:https://nvlabs.github.io/few-shot-vid2vid/




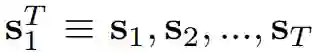 ,转化为输出图像的序列,即
,转化为输出图像的序列,即
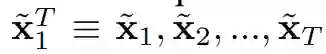 。
在这一过程中,以语义图像序列为条件的输出图像分布和标注图像分布是近似的。
换言之,视频到视频合成旨在实现
。
在这一过程中,以语义图像序列为条件的输出图像分布和标注图像分布是近似的。
换言之,视频到视频合成旨在实现
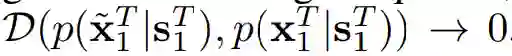 ,其中 D 是分布散度测量,如 Jensen-Shannon 散度(简称「J-S 散度」)或 Wasserstein 散度。
为了对条件分布进行建模,现有研究利用了简化的马尔可夫假设(Markov assumption),并通过以下方程得出序列生成模型:
,其中 D 是分布散度测量,如 Jensen-Shannon 散度(简称「J-S 散度」)或 Wasserstein 散度。
为了对条件分布进行建模,现有研究利用了简化的马尔可夫假设(Markov assumption),并通过以下方程得出序列生成模型:

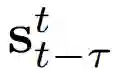 ,还有Τ-1 生成的图像
,还有Τ-1 生成的图像
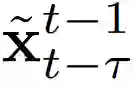 生成输出图像。
生成输出图像。
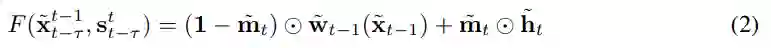
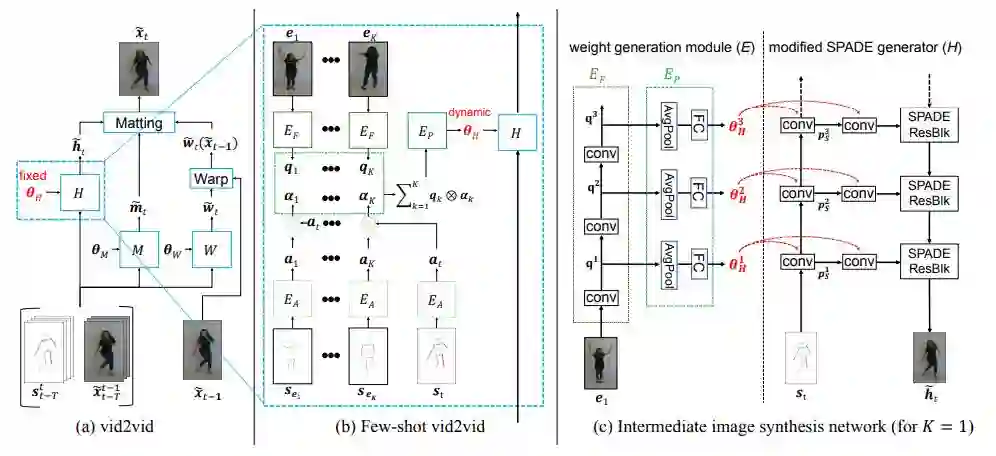
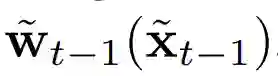 和合成的中间图
像 h_t tilde 生成的。
和合成的中间图
像 h_t tilde 生成的。
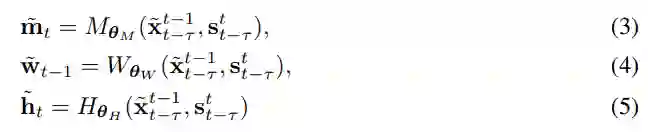
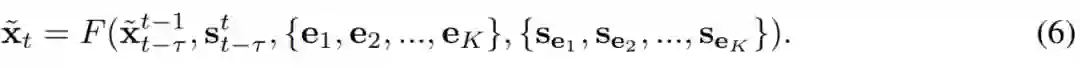
基于注意力的聚合(K > 1)
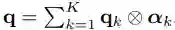 ,
然后将其输入到多层感知机 E_P 以生成网络权重(见下文中的图 2(b))。
这种聚合机制在不同示例图像包含目标的不同部分时很有帮助。
例如,当示例图像分别包含目标人物的正面和背面时,该注意力图可以在合成期间帮助捕捉相应的身体部位。
,
然后将其输入到多层感知机 E_P 以生成网络权重(见下文中的图 2(b))。
这种聚合机制在不同示例图像包含目标的不同部分时很有帮助。
例如,当示例图像分别包含目标人物的正面和背面时,该注意力图可以在合成期间帮助捕捉相应的身体部位。
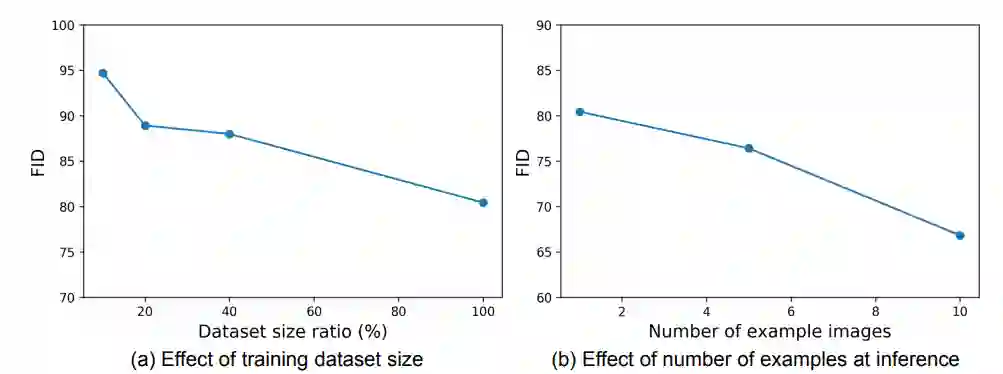
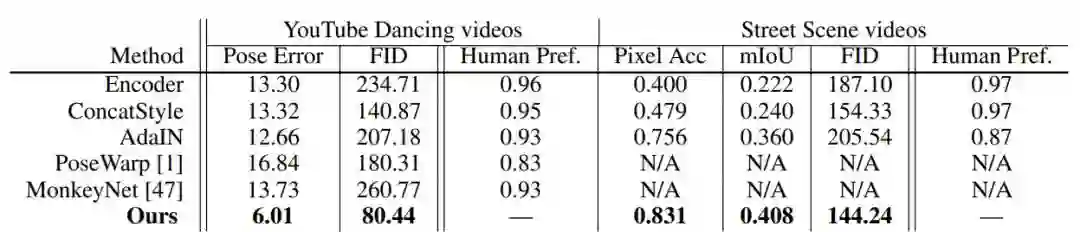
实验结果






登录查看更多
相关内容

专知会员服务
27+阅读 · 2019年8月10日


相关VIP内容
专知会员服务
27+阅读 · 2019年8月10日
相关资讯
相关论文