【专知-Java Deeplearning4j深度学习教程04】使用CNN进行文本分类:图文+代码
点击上方“专知”关注获取更多AI知识!
【导读】主题链路知识是我们专知的核心功能之一,为用户提供AI领域系统性的知识学习服务,一站式学习人工智能的知识,包含人工智能( 机器学习、自然语言处理、计算机视觉等)、大数据、编程语言、系统架构。使用请访问专知 进行主题搜索查看 - 桌面电脑访问www.zhuanzhi.ai, 手机端访问www.zhuanzhi.ai 或关注微信公众号后台回复" 专知"进入专知,搜索主题查看。继Pytorch教程后,我们推出面向Java程序员的深度学习教程DeepLearning4J。Deeplearning4j的案例和资料很少,官方的doc文件也非常简陋,基本上所有的类和函数的都没有解释。为此,我们推出来自中科院自动化所专知小组博士生Hujun与Sanglei创作的-分布式Java开源深度学习框架Deeplearning4j学习教程,第四篇,使用CNN进行文本分类。
使用多层神经网络分类MNIST数据集
基于DL4J的CNN、AutoEncoder、RNN、Word2Vec等模型的实现
卷积神经网络(Convolutional Neural Network, CNN), 最早应用在图像处理领域。 从最早的mnist手写体数字识别,到ImageNet大规模图像分类比赛,再到炙手可热的自动驾驶技术,CNN在其中都起到了举足轻重的作用。
最近CNN也被成功的应用到自然语言处理领域(Natural Language Processing), 并取得了引人注目的成果。我将在本文中归纳什么是CNN,并以一个简单的文本分类的例子介绍怎样将CNN应用于NLP。CNN背后的直觉知识在计算机视觉的用例里更容易被理解,因此我就先从那里开始,然后慢慢过渡到自然语言处理。
什么是卷积运算
卷积神经网络与之前讲到的常规的神经网络非常相似:它们都是由神经元组成,神经元中有具有学习能力的权重和偏差。每个神经元都得到一些输入数据,进行内积运算后再进行激活函数运算。
那么有哪些地方变化了呢?卷积神经网络的结构基于一个假设,即输入数据是二维的图像,基于该假设,我们就向结构中添加了一些特有的性质。这些特有属性使得前向传播函数实现起来更高效,并且大幅度降低了网络中参数的数量。
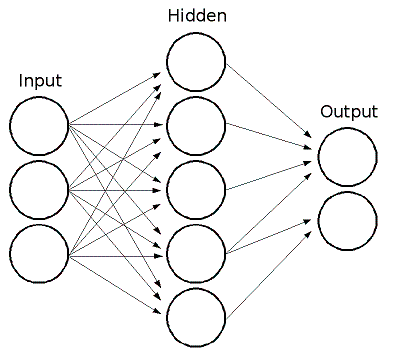
上图是常规的全连接网络, 我们可以看到这里的输入层就是一维向量,后续的处理方式使用简单的全连接层就可以了。而卷积网络的输入要求是二维向量,这就需要向网络结构中加入一些新的特性来处理,也就是卷积操作
http://deeplearning.stanford.edu/wiki/index.php/Feature_extraction_using_convolution
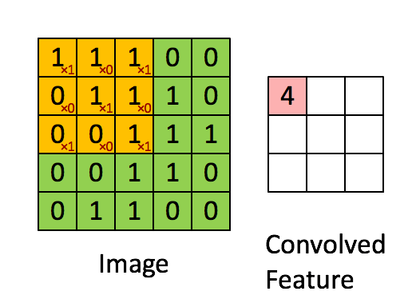
图中绿色为一个二值图像,每个值代表一个像素(0是黑,1是白)。(更典型的是像素值为0-255的灰阶图像)
图中黄色的滑动窗口叫卷积核、过滤器或者特征检测器,也是一个矩阵。
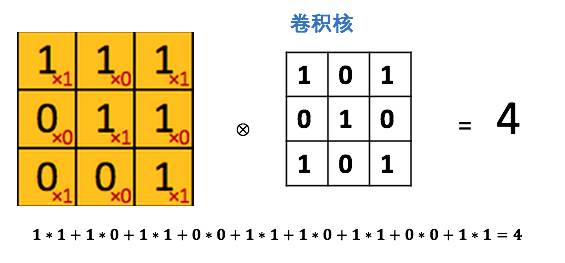
将这个大小是3x3的过滤器中的每个元素(红色小字)与图像中对应位置的值相乘,然后对它们求和,得到右边粉红色特征图矩阵的第一个元素值。
在整个图像矩阵上滑动这个过滤器来得到完整的卷积特征图如下:
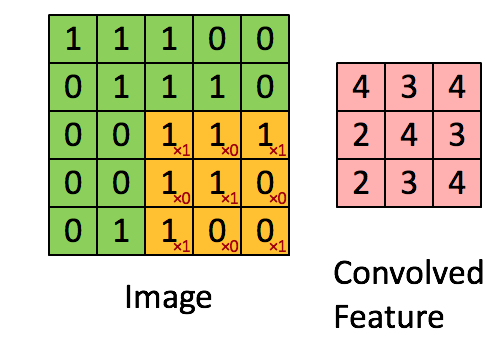
什么是卷积神经网络?
知道了卷积运算了吧。那CNN又是什么呢?CNN本质上就是多层卷积运算,外加对每层的输出用非线性激活函数做转换,比如用ReLU和tanh。
常规的神经网络把每个输入神经元与下一层的输出神经元相连接。这种方式也被称作是全连接层。
在CNN中我们不这样做,而是用输入层的卷积结果来计算输出, 也就是上图中的(Convolved Feature)。
这相当于是局部连接,每块局部的输入区域与输出的一个神经元相连接。对每一层应用不同的滤波器,往往是如上图所示成百上千个,然后汇总它们的结果。
这里也涉及到池化层(降采样),我会在后文做解释。
在训练阶段,CNN基于你想完成的任务自动学习卷积核的权重值。
举个例子,在图像分类问题中,第一层CNN模型或许能学会从原始像素点检测到一些边缘线条,然后根据边缘线条在第二层检测出一些简单的形状,然后基于这些形状检测出更高级的特征,比如脸部轮廓等。最后一层是利用这些高级特征的一个分类器。
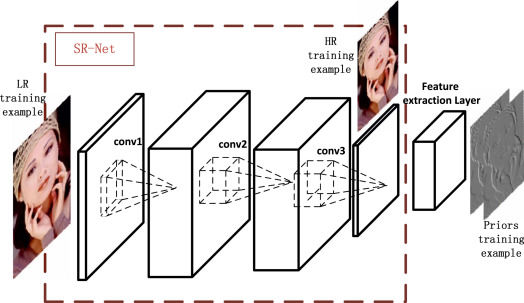
为什么要用卷积神经网络?
图像处理中,往往会将图像看成是一个或者多个二维向量,传统的神经网络采用全联接的方式,即输入层到隐藏层的神经元都是全部连接的,这样做将导致参数量巨大,使得网络训练耗时甚至难以训练,而CNN则通过局部链接、权值共享等方法避免这一困难。
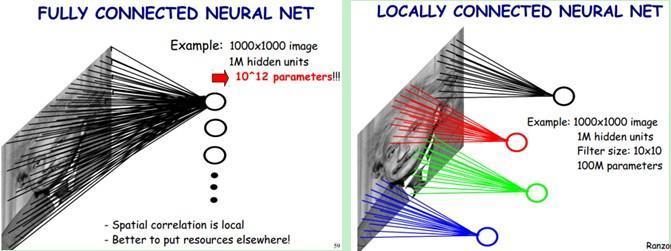
局部连接
对于一个1000 × 1000的输入图像而言,如果下一个隐藏层的神经元数目为10^6个,采用全连接则有1000 × 1000 × 10^6 = 10^12个权值参数,如此数目巨大的参数几乎难以训练;而采用局部连接,假如局部感受野是10 x 10,隐藏层的每个神经元仅与图像中10 × 10的局部图像相连接,那么此时的权值参数数量为10 × 10 × 10^6 = 10^8,将直接减少4个数量级。
权值共享
隐含层每个神经元都连接10 * 10 个图像区域,也就是说每一个神经元存在100个连接权值参数。如果我们每个神经元这100个参数相同呢?将这10 × 10个权值参数共享给剩下的神经元,也就是说隐藏层中10^6个神经元的权值参数相同,那么此时不管隐藏层神经元的数目是多少,需要训练的参数就是这 10 × 10个权值参数(也就是卷积核(也称滤波器)的大小)
这大概就是CNN的一个神奇之处,尽管只有这么少的参数,依旧有出色的性能。但是,这样仅提取了图像的一种特征,如果要多提取出一些特征,可以增加多个卷积核,不同的卷积核能够得到图像的不同映射下的特征,称之为Feature Map。如果有100个卷积核,最终的权值参数也仅为100 × 100 = 10^4个而已。另外,偏置参数也是共享的,同一种滤波器共享一个。
感觉好厉害,那如何将CNN用于NLP呢?
要将CNN用到文本处理中首先要解决的就是文本的表示问题。前面提到CNN的输入是一个二维向量,图像的像素表示天然具有这种形式。而对于文本来说,我们通常采用词向量的方法来将一段话表示成二维向量形式。
词向量的基本思想是将每个词表示为n维稠密,连续的实数向量,通常是几十到几百维不等。而这些向量表示保存了每个词在语料中出现的一些上下信息,这样我们就可以简单的通过直接计算词表示两个向量的cos距离,来的到他们之间的相似度。现在有很多词向量的学习方式,最具代表性的应该是13年google发表的两篇word2vec,其在随之发布了简单的word2vec工具包,并在语义维度上得到了很好的验证,极大的推动了文本分析的进程。
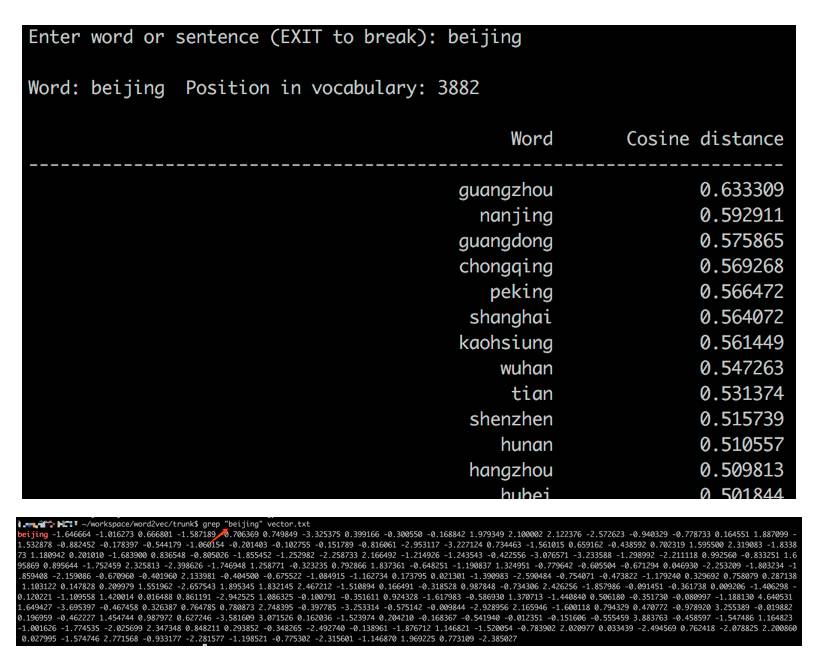
下边是一个简单的向量相似度计算的例子。与“beijing” 这个词的表示向量距离相近的是一些其他的城市名。 而“北京”在这里是用一个200维的向量表示的。
在有了每个词的向量表示后,通过简单的拼接将一段文本表示成2维矩阵形式。在这里每一行是一个词的向量表示。
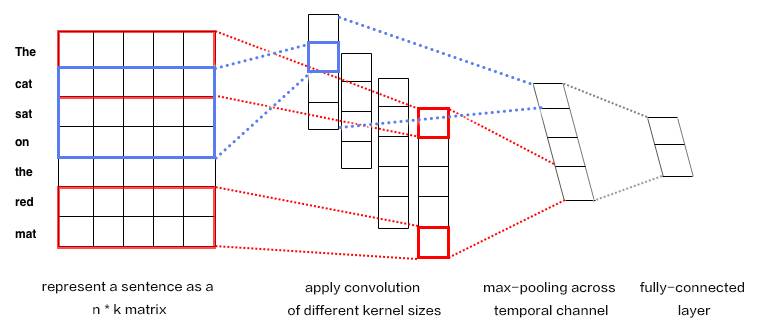
输入是一个句子,为了使其可以进行卷积,首先需要将其转化为向量表示,通常使用word2vec实现。
k表示词向量的维度,n是一段文本的长度。文本被表示成[sentence_lengh * word_dimension]的一个二维向量。图中表示为7*5
卷积核每次只对图像的一小块区域运算,但在处理自然语言时滤波器通常覆盖上下几行(几个词)。因此,卷积核的宽度也就和输入矩阵的宽度也就是向量维度相等了。尽管高度,或者区域大小可以随意调整,但一般滑动窗口的覆盖范围是2~5行。
示意图中我们对卷积核设置了2行和3行两种尺寸,每种尺寸各有两种滤波器。的到4个feature map
每个卷积核对句子矩阵做卷积运算,得到(不同程度的)filter。然后对每个filter做最大值池化,也就是只记录filter的最大值。这样,就由4个字典生成了一串单变量特征向量(univariate feature vector)
然后这4个特征拼接形成一个特征向量,传给网络的倒数第二层。最后的softmax层以这个特征向量作为输入,用其来对句子做分类;我们假设这里是二分类问题,因此得到两个可能的输出状态。
池化(pooling)操作
简单来说pooling操作可以进一步减少网络参数,通常max-pooling 对每一filter提取的向量进行操作,最后每一个filter对应一个数字。除此之外还有mean-pooling,就是将filter中的向量所有向量求平均得到一个数字。
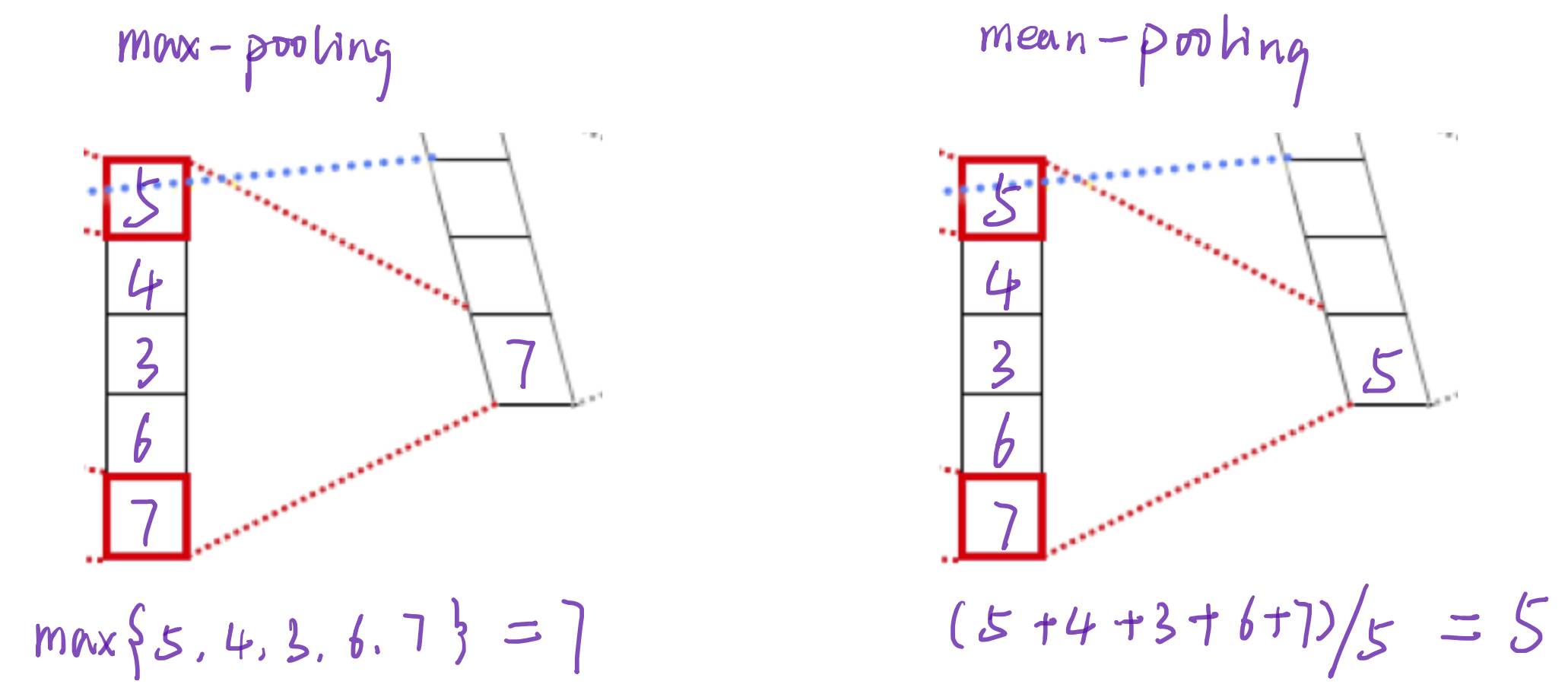
这样操作过后4个5维的filter就转化成了1个4维的向量。而这个4维的向量就可以看成整段文本的的一个向量表示形式。得到了这个表示后,就可以将其应用在许多文本处理的问题中,比如简单的文本分类,聚类。
用DL4J实现基于CNN的文本分类
注意:
本示例需要额外引入deeplearning4j-nlp的Maven依赖
需要手动下载预训练的词向量和IMDB数据集,下载地址和存放路径在代码注释中。
运行时请将JVM的最大内存设置大一些,具体方法请查看注释。
import org.apache.commons.io.FileUtils;
import org.apache.commons.io.FilenameUtils;
import org.deeplearning4j.eval.Evaluation;
import org.deeplearning4j.iterator.CnnSentenceDataSetIterator;
import org.deeplearning4j.iterator.LabeledSentenceProvider;
import org.deeplearning4j.iterator.provider.FileLabeledSentenceProvider;
import org.deeplearning4j.models.embeddings.loader.WordVectorSerializer;
import org.deeplearning4j.models.embeddings.wordvectors.WordVectors;
import org.deeplearning4j.nn.api.Layer;
import org.deeplearning4j.nn.conf.*;
import org.deeplearning4j.nn.conf.graph.MergeVertex;
import org.deeplearning4j.nn.conf.layers.ConvolutionLayer;
import org.deeplearning4j.nn.conf.layers.GlobalPoolingLayer;
import org.deeplearning4j.nn.conf.layers.OutputLayer;
import org.deeplearning4j.nn.conf.layers.PoolingType;
import org.deeplearning4j.nn.graph.ComputationGraph;
import org.deeplearning4j.nn.weights.WeightInit;
import org.deeplearning4j.optimize.listeners.ScoreIterationListener;
import org.nd4j.linalg.activations.Activation;
import org.nd4j.linalg.api.ndarray.INDArray;
import org.nd4j.linalg.dataset.api.iterator.DataSetIterator;
import org.nd4j.linalg.factory.Nd4j;
import org.nd4j.linalg.lossfunctions.LossFunctions;
import java.io.File;import java.util.*;/** * 本代码的模型来源于下面论文: * Convolutional Neural Networks for Sentence Classification - https://arxiv.org/abs/1408.5882 * * 本代码实现了论文中的static模型,即词向量被固定,不参与反向传播的模型 * *本代码用到的Maven依赖有: * 1.nd4j-native/nd4j-cuda-7.5/nd4j-cuda-8.0 * 2.deeplearning4j-core * 3.deeplearning4j-nlp * 4.slf4j-log4j12 * * 另外,需要手动下载预训练词向量和IMDB数据集: * 预训练词向量: https://github.com/mmihaltz/word2vec-GoogleNews-vectors * IMDB: http://ai.stanford.edu/~amaas/data/sentiment/aclImdb_v1.tar.gz * * 下载后按照下面路径放置: * * -代码所在磁盘根目录(如C盘或D盘) * -data * -dl4j * -aclImdb: 解压后的IMDB数据集 * -word2vec * -GoogleNews-vectors-negative300.bin.gz * * * @author Alex Black */public class CnnSentenceClassificationExample { /** IMDB数据集所在的目录(aclImdb文件夹的父文件夹) **/ public static final String DATA_PATH = "/data/dl4j"; /** 预训练词向量文件路径 */ public static final String WORD_VECTORS_PATH = "/data/dl4j/word2vec/GoogleNews-vectors-negative300.bin.gz"; //本示例比较耗费内存,运行程序前请设置参数调整JVM内存上限,例如加上-Xmx8000m将内存上限调整为8000M public static void main(String[] args) throws Exception { //配置信息 int batchSize = 32; int vectorSize = 300; //词向量维度. 本代码用的Google News词向量模型的维度是300 int nEpochs = 1; //epoch数量,扫描一遍数据集为一个epoch int truncateReviewsToLength = 256; //句子长度上线,即句子包含的最大单词数量 int cnnLayerFeatureMaps = 100; //每种大小卷积核的卷积核的数量 PoolingType globalPoolingType = PoolingType.MAX; Random rng = new Random(12345); //设置随机种子,使得每次运行程序都能获得同样的结果 //设置内存垃圾回收的周期 Nd4j.getMemoryManager().setAutoGcWindow(5000); ComputationGraphConfiguration config = new NeuralNetConfiguration.Builder() .trainingWorkspaceMode(WorkspaceMode.SINGLE).inferenceWorkspaceMode(WorkspaceMode.SINGLE) .weightInit(WeightInit.RELU) .activation(Activation.LEAKYRELU) .updater(Updater.ADAM) .convolutionMode(ConvolutionMode.Same) //This is important so we can 'stack' the results later .regularization(true).l2(0.0001) .learningRate(0.01) .graphBuilder() .addInputs("input") //以形状为[3, 词向量维度]的卷积核进行卷积 .addLayer("cnn3", new ConvolutionLayer.Builder() .kernelSize(3,vectorSize) .stride(1,vectorSize) .nIn(1) .nOut(cnnLayerFeatureMaps) .build(), "input") //以形状为[4, 词向量维度]的卷积核进行卷积 .addLayer("cnn4", new ConvolutionLayer.Builder() .kernelSize(4,vectorSize) .stride(1,vectorSize) .nIn(1) .nOut(cnnLayerFeatureMaps) .build(), "input") //以形状为[5, 词向量维度]的卷积核进行卷积 .addLayer("cnn5", new ConvolutionLayer.Builder() .kernelSize(5,vectorSize) .stride(1,vectorSize) .nIn(1) .nOut(cnnLayerFeatureMaps) .build(), "input") //拼接由三种不同形状卷积核进行的卷积变换的结果 .addVertex("merge", new MergeVertex(), "cnn3", "cnn4", "cnn5") //进行Max Pooling .addLayer("globalPool", new GlobalPoolingLayer.Builder() .poolingType(globalPoolingType) .dropOut(0.5) .build(), "merge") //用Pooling后得到的特征和一个全连接层进行文本分类 .addLayer("out", new OutputLayer.Builder() .lossFunction(LossFunctions.LossFunction.MCXENT) .activation(Activation.SOFTMAX) .nIn(3*cnnLayerFeatureMaps) .nOut(2) //2 classes: positive or negative .build(), "globalPool") .setOutputs("out") .build(); ComputationGraph net = new ComputationGraph(config); net.init(); System.out.println("Number of parameters by layer:"); for(Layer l : net.getLayers() ){ System.out.println("\t" + l.conf().getLayer().getLayerName() + "\t" + l.numParams()); } //根据预训练的词向量和IMDB数据集构建训练集和测试集 System.out.println("Loading word vectors and creating DataSetIterators"); WordVectors wordVectors = WordVectorSerializer.loadStaticModel(new File(WORD_VECTORS_PATH)); DataSetIterator trainIter = getDataSetIterator(true, wordVectors, batchSize, truncateReviewsToLength, rng); DataSetIterator testIter = getDataSetIterator(false, wordVectors, batchSize, truncateReviewsToLength, rng); //开始训练 System.out.println("Starting training"); net.setListeners(new ScoreIterationListener(100)); for (int i = 0; i < nEpochs; i++) { net.fit(trainIter); System.out.println("Epoch " + i + " complete. Starting evaluation:"); //评价训练的模型,这里包含了25000个句子,可能会花一些时间 Evaluation evaluation = net.evaluate(testIter); System.out.println(evaluation.stats()); } //取一个句子进行分类 String pathFirstNegativeFile = FilenameUtils.concat(DATA_PATH, "aclImdb/test/neg/0_2.txt"); String contentsFirstNegative = FileUtils.readFileToString(new File(pathFirstNegativeFile)); INDArray featuresFirstNegative = ((CnnSentenceDataSetIterator)testIter).loadSingleSentence(contentsFirstNegative); INDArray predictionsFirstNegative = net.outputSingle(featuresFirstNegative); List<String> labels = testIter.getLabels(); //输出这个句子被模型预测为Negative和Positive的概率 System.out.println("\n\nPredictions for first negative review:"); for( int i=0; i<labels.size(); i++ ){ System.out.println("P(" + labels.get(i) + ") = " + predictionsFirstNegative.getDouble(i)); } } private static DataSetIterator getDataSetIterator(boolean isTraining, WordVectors wordVectors, int minibatchSize, int maxSentenceLength, Random rng ){ String path = FilenameUtils.concat(DATA_PATH, (isTraining ? "aclImdb/train/" : "aclImdb/test/")); String positiveBaseDir = FilenameUtils.concat(path, "pos"); String negativeBaseDir = FilenameUtils.concat(path, "neg"); File filePositive = new File(positiveBaseDir); File fileNegative = new File(negativeBaseDir); Map<String,List<File>> reviewFilesMap = new HashMap<>(); reviewFilesMap.put("Positive", Arrays.asList(filePositive.listFiles())); reviewFilesMap.put("Negative", Arrays.asList(fileNegative.listFiles())); LabeledSentenceProvider sentenceProvider = new FileLabeledSentenceProvider(reviewFilesMap, rng); return new CnnSentenceDataSetIterator.Builder() .sentenceProvider(sentenceProvider) .wordVectors(wordVectors) .minibatchSize(minibatchSize) .maxSentenceLength(maxSentenceLength) .useNormalizedWordVectors(false) .build(); } }
运行结果:
2017-10-14 14:43:36 INFO Nd4jBackend:194 - Loaded [JCublasBackend] backend 2017-10-14 14:43:37 INFO Reflections:229 - Reflections took 170 ms to scan 122 urls, producing 54501 keys and 58577 values 2017-10-14 14:43:37 INFO NativeOpsHolder:49 - Number of threads used for NativeOps: 32 2017-10-14 14:43:38 INFO Reflections:229 - Reflections took 69 ms to scan 10 urls, producing 31 keys and 227 values 2017-10-14 14:43:38 INFO DefaultOpExecutioner:565 - Backend used: [CUDA]; OS: [Windows 10] 2017-10-14 14:43:38 INFO DefaultOpExecutioner:566 - Cores: [8]; Memory: [6.9GB]; 2017-10-14 14:43:38 INFO DefaultOpExecutioner:567 - Blas vendor: [CUBLAS] 2017-10-14 14:43:38 INFO CudaExecutioner:2116 - Device name: [GeForce GTX 1060 6GB]; CC: [6.1]; Total/free memory: [6442450944] 2017-10-14 14:43:39 INFO Reflections:229 - Reflections took 992 ms to scan 99 urls, producing 2323 keys and 9555 values 2017-10-14 14:43:39 INFO ComputationGraph:56 - Starting ComputationGraph with WorkspaceModes set to [training: SINGLE; inference: SINGLE] 2017-10-14 14:43:40 INFO Reflections:229 - Reflections took 100 ms to scan 10 urls, producing 407 keys and 1602 values Number of parameters by layer: cnn3 90100 cnn4 120100 cnn5 150100 globalPool 0 out 602 Loading word vectors and creating DataSetIterators Starting training 2017-10-14 14:45:18 INFO Nd4jBlas:37 - Number of threads used for BLAS: 0 2017-10-14 14:45:20 INFO ScoreIterationListener:64 - Score at iteration 0 is 0.7202949854867678 2017-10-14 14:47:15 INFO ScoreIterationListener:64 - Score at iteration 100 is 0.6463996689421923 2017-10-14 14:48:35 INFO ScoreIterationListener:64 - Score at iteration 200 is 0.4634944634627448 2017-10-14 14:49:42 INFO ScoreIterationListener:64 - Score at iteration 300 is 0.401260720151129 2017-10-14 14:50:51 INFO ScoreIterationListener:64 - Score at iteration 400 is 0.34404899690885465 2017-10-14 14:51:46 INFO ScoreIterationListener:64 - Score at iteration 500 is 0.3989343702531156 2017-10-14 14:52:38 INFO ScoreIterationListener:64 - Score at iteration 600 is 0.3147465993881237 2017-10-14 14:53:28 INFO ScoreIterationListener:64 - Score at iteration 700 is 0.29517011246749025 Epoch 0 complete. Starting evaluation: Examples labeled as Negative classified by model as Negative: 11371 times Examples labeled as Negative classified by model as Positive: 1129 times Examples labeled as Positive classified by model as Negative: 2948 times Examples labeled as Positive classified by model as Positive: 9553 times ==========================Scores======================================== # of classes: 2 Accuracy: 0.8369 Precision: 0.8442 Recall: 0.8369 F1 Score: 0.8241 ======================================================================== Predictions for first negative review: P(Negative) = 0.6227536797523499 P(Positive) = 0.37724635004997253
请登录www.zhuanzhi.ai,
搜索“DeepLearning4j”,查看获得代码。
明天请继续关注“DeepLearning4j”教程。
完整系列搜索查看,请PC登录
www.zhuanzhi.ai, 搜索“DeepLearning4j”即可得。
对DeepLearning4j教程感兴趣的同学,欢迎进入我们的专知DeepLearning4j主题群一起交流、学习、讨论,扫一扫如下群二维码即可进入:

如果群满,请扫描小助手,加入进群~

了解使用专知-获取更多AI知识!
阅读更多专知干货:
【干货】RL-GAN For NLP: 强化学习在生成对抗网络文本生成中扮演的角色
欢迎转发分享到微信群和朋友圈!

欢迎转发分享到微信群和朋友圈!
获取更多关于机器学习以及人工智能知识资料,请访问www.zhuanzhi.ai, 或者点击阅读原文,即可得到!
-END-
欢迎使用专知
专知,一个新的认知方式!目前聚焦在人工智能领域为AI从业者提供专业可信的知识分发服务, 包括主题定制、主题链路、搜索发现等服务,帮你又好又快找到所需知识。
使用方法>>访问www.zhuanzhi.ai, 或点击文章下方“阅读原文”即可访问专知
中国科学院自动化研究所专知团队
@2017 专知
专 · 知
关注我们的公众号,获取最新关于专知以及人工智能的资讯、技术、算法、深度干货等内容。扫一扫下方关注我们的微信公众号。


点击“阅读原文”,使用专知!




