【专知-PyTorch手把手深度学习教程02】CNN快速理解与PyTorch实现: 图文+代码
点击上方“专知”关注获取更多AI知识!
【导读】主题链路知识是我们专知的核心功能之一,为用户提供AI领域系统性的知识学习服务,一站式学习人工智能的知识,包含人工智能( 机器学习、自然语言处理、计算机视觉等)、大数据、编程语言、系统架构。使用请访问专知 进行主题搜索查看 - 桌面电脑访问www.zhuanzhi.ai, 手机端访问www.zhuanzhi.ai 或关注微信公众号后台回复" 专知"进入专知,搜索主题查看。值国庆佳节,专知特别推出独家特刊-来自中科院自动化所专知小组博士生huaiwen和Jin创作的-PyTorch教程学习系列, 今日带来第二篇
< 快速理解系列(一): 图文+代码, 让你快速理解CNN>
< 快速理解系列(二): 图文+代码, 让你快速理解LSTM>
< 快速理解系列(三): 图文+代码, 让你快速理解GAN >
< 快速理解系列(四): 图文+代码, 让你快速理解Dropout >
< NLP系列(一) 用Pytorch 实现 Word Embedding >
< NLP系列(二) 基于字符级RNN的姓名分类 >
< NLP系列(三) 基于字符级RNN的姓名生成 >
为了增进CNN的理解和使用,故写此文,以其与人交流,互有增益。欢迎大家交流指正。下面直奔主题。
一、神经网络(Neural Network)
要弄清楚什么是卷积神经网络,首先让我们了解一下什么是神经网络。在上一篇文章的内容中,我们实现了基本神经网络的构建和训练(具体实现细节参考上一篇文章的代码)。神经网络的输入是一个向量,然后在一系列的隐层中对它做变换。每个隐层都是由若干的神经元组成,每个神经元都与前一层中的某些神经元连接。同一隐层中,神经元相互独立不进行任何连接。某些层会将神经元全部连接,称为全连接层
神经元
下图是一个激活函数为
sigmoid函数的神经元sigmoid
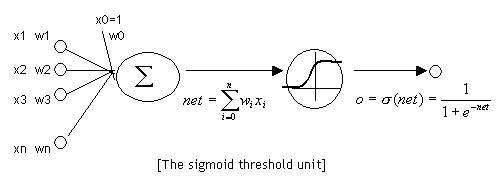
神经网络其实就是按照一定规则连接起来的多个神经元。下图展示了两个全连接(
full connected, FC)神经网络。image
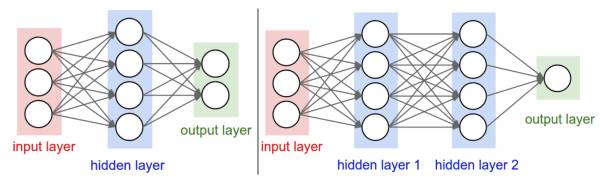
左边是一个2层神经网络,隐层由4个神经元(也可称为单元(unit))组成,输出层由2个神经元组成,输入层是3个神经元。右边是一个3层神经网络,两个含4个神经元的隐层。
二、卷积神经网络(Convolutional Neural Network)
卷积神经网络(
Convolutional Neural Network)简称CNN。它是近些年逐步兴起的一种人工神经网络结构, 因为利用卷积神经网络在图像和语音识别方面能够给出更优预测结果, 这一种技术也被广泛的传播和应用.在图像处理中,往往把图像表示为像素的向量,比如一个
1000×1000的图像,可以表示为一个1000000的向量。在以上提到的神经网络中,如果隐含层数目与输入层一样,即也是1000000时,那么输入层到隐含层的参数数据为1000000×1000000=10^12,这样就太多了,基本没法训练。所以图像处理要想练成神经网络大法,必先减少参数加快速度。
1、局部感知
卷积神经网络有两种方式可以降低参数数目,第一种方法叫做局部感知野(
receptive field)。一般认为人对外界的认知是从局部到全局的,对于一张图像来说, 同样是局部的像素联系较为紧密,而距离较远的像素相关性较弱。因而,每个神经元其实没有必要对全局图像进行感知,只需要对局部进行感知,然后在更高层将局部的信息综合起来就得到全局的信息即可。网络部分连通的思想,也是受启发于生物学里面的视觉系统结构。视觉皮层的神经元就是局部接受信息的(即这些神经元只响应某些特定区域的刺激)。感受野(
receptive field),它的尺寸是一个超参数(其实就是滤波器的空间尺)。在深度方向上,这个连接的大小总是和输入量的深度相等。需要再次强调的是,我们对待空间维度(宽和高)与深度维度是不同的:连接在空间(宽高)上是局部的,但是在深度上总是和输入数据的深度一致。image
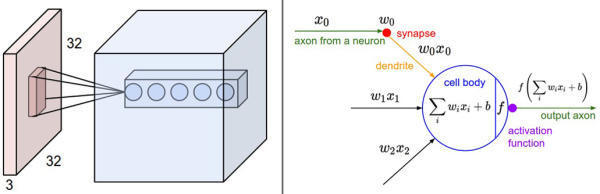
左边:红色的是输入数据(比如CIFAR-10中的图像),蓝色的部分是第一个卷积层中的神经元。卷积层中的每个神经元都只是与输入数据某些部分在空间上相连,但是与输入数据的所有深度维度全部相连(颜色通道, 如RGB)。在深度方向上有多个神经元(本例中5个),它们都接受输入数据的同一块区域(感受野相同)。至于深度列的讨论在下文中有。
右边:神经网络章节中介绍的神经元保持不变,它们还是计算权重和输入的内积,然后进行激活函数运算,只是它们的连接被限制在一个局部空间。
2、参数共享
其实用上面的方法参数仍然很多,这时候还有另一种方法解决这个问题,即参数(权值)共享。
例如在局部连接中,每个神经元都对应100个参数,一共1000000个神经元,如果这1000000个神经元的100个参数都是相等的,那么参数数目就变为100了。
怎么理解权值共享呢?我们可以这100个参数(也就是卷积操作)看成是提取特征的方式,该方式与位置无关。这其中隐含的原理则是:图像的一部分的统计特性与其他部分是一样的。这也意味着我们在这一部分学习的特征也能用在另一部分上,所以对于这个图像上的所有位置,我们都能使用同样的学习特征。
卷积层中每个神经元与输入数据之间进行局部连接,但是尚未讨论输出数据中神经元的数量,以及它们的排列方式。3个超参数控制着输出数据体的尺寸:深度(depth),步长(stride)和零填充(zero-padding)。下面是对它们的讨论:
输出数据的深度是一个超参数:它和使用的滤波器的数量一致,而每个滤波器在输入数据中寻找一些不同的东西。举例来说,如果第一个卷积层的输入是原始图像,那么在深度维度上的不同神经元将可能被不同方向的边界,或者是颜色斑点激活。我们将这些沿着深度方向排列、感受野相同的神经元集合称为深度列(
depth column),也有人使用纤维(fibre)来称呼它们。在滑动滤波器的时候,必须指定步长。当步长为1,滤波器每次移动1个像素。当步长为2(或者不常用的3,或者更多,这些在实际中很少使用),滤波器滑动时每次移动2个像素。这个操作会让输出数据体在空间上变小。
在下文可以看到,有时候将输入数据用0在边缘处进行填充是很方便的。这个零填充(
zero-padding)的尺寸是一个超参数。零填充有一个良好性质,即可以控制输出数据体的空间尺寸(最常用的是用来保持输入数据体在空间上的尺寸,这样输入和输出的宽高都相等)。
当上面的说法没有使你明白时,请务必仔细看一下下面卷积层的动态演示过程。
卷积层演示:下面是一个卷积层的运行演示。因为3D数据难以可视化,所以所有的数据(输入数据是蓝色,权重数据是红色,输出数据是绿色)都采取将深度切片按照列的方式排列展现。输入数据的尺寸是W_1=5,H_1=5,D_1=3,卷积层参数K=2,F=3,S=2,P=1。就是说,有2个滤波器,滤波器的尺寸是3* 3,它们的步长是2.因此,输出数据体的空间尺寸是(5-3+2)/2+1=3。注意输入数据体使用了零填充P=1,所以输入数据体外边缘一圈都是0。下面的例子在绿色的输出激活数据上循环演示,展示了其中每个元素都是先通过蓝色的输入数据和红色的滤波器逐元素相乘,然后求其总和,最后加上偏差得来。
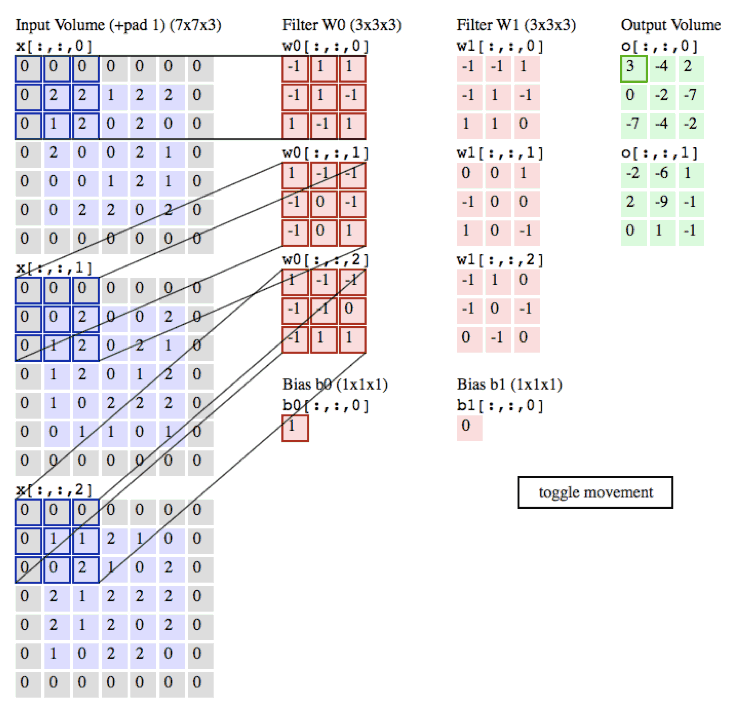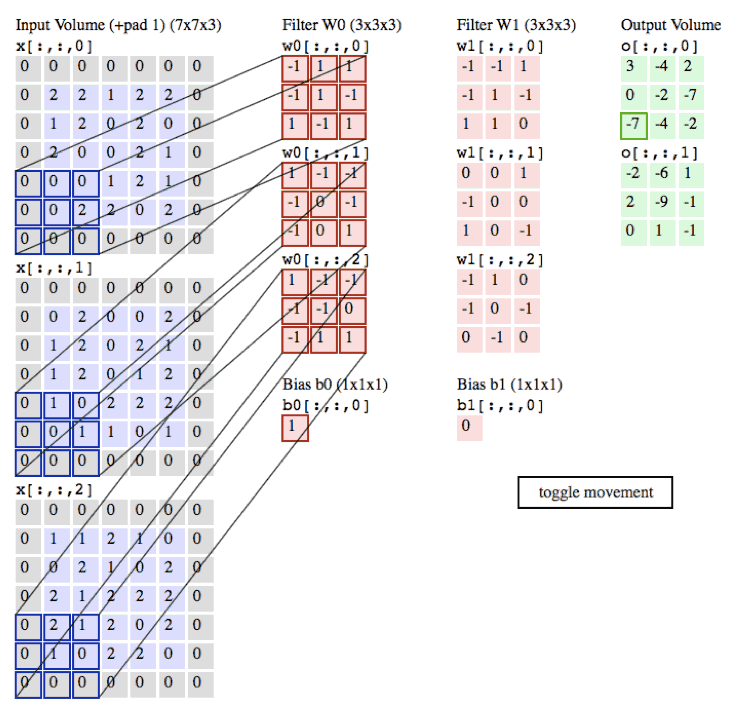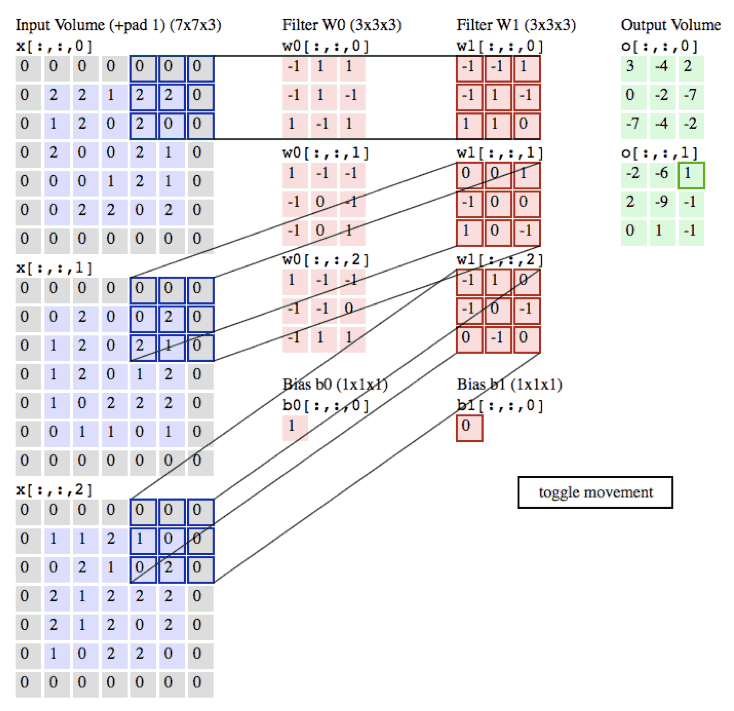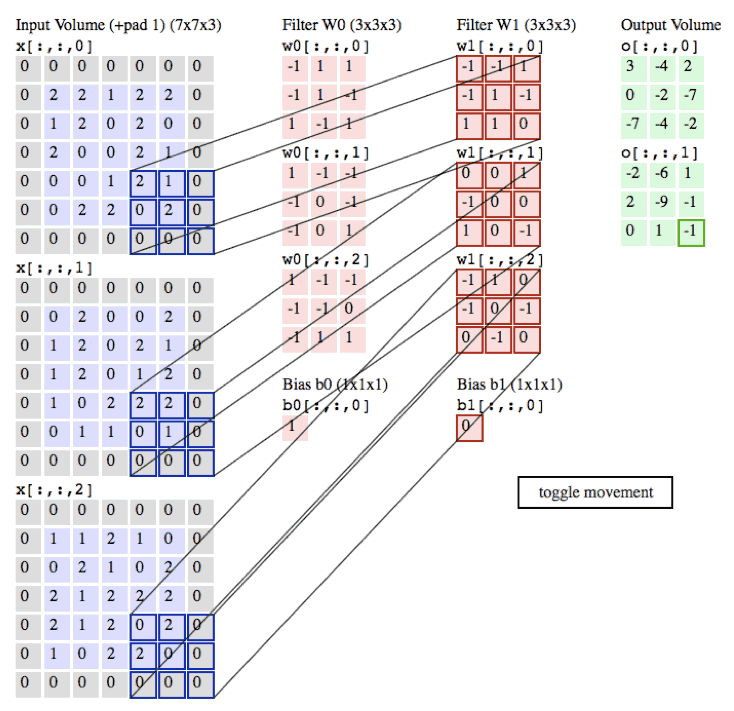
image
注意:请点击图片查看动画演示。如果gif不能正确播放,请读者前往斯坦福课程官网查看此演示。
3、Pooling
通常,在连续的卷积层之间会周期性地插入一个池化层。它的作用是逐渐降低数据体的空间尺寸,这样的话就能减少网络中参数的数量,使得计算资源耗费变少,也能有效控制过拟合。池化层使用MAX操作,对输入数据的每一个深度切片独立进行操作,改变它的空间尺寸。最常见的形式是池化层使用尺寸2x2的滤波器,以步长为2来对每个深度切片进行降采样,将其中75%的激活信息都丢掉。每个MAX操作是从4个数字中取最大值(也就是在深度切片中某个2x2的区域)。深度保持不变。
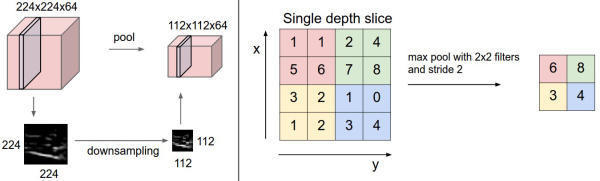
image
池化层在输入数据的每个深度切片上,独立地对其进行空间上的降采样。左边:本例中,输入数据尺寸[224x224x64]被降采样到了[112x112x64],采取的滤波器尺寸是2,步长为2,而深度不变。右边:最常用的降采样操作是取最大值,也就是最大汇聚,这里步长为2,每个取最大值操作是从4个数字中选取(即2x2的方块区域中)。
不使用池化层:很多人不喜欢池化操作,认为可以不使用它。比如在Striving for Simplicity: The All Convolutional Net一文中,提出使用一种只有重复的卷积层组成的结构,抛弃池化层。通过在卷积层中使用更大的步长来降低数据体的尺寸。有发现认为,在训练一个良好的生成模型时,弃用池化层也是很重要的。比如变分自编码(VAEs:variational autoencoders)和生成对抗网络(GANs:generative adversarial networks)。现在看起来,未来的卷积网络结构中,可能会很少使用甚至不使用池化层。
4、卷积神经网络的构建
卷积神经网络是由层组成的。每一层都有一个简单的API:用一些含或者不含参数的可导的函数,将输入的3D数据变换为3D的输出数据。
一个简单的卷积神经网络是由各种层按照顺序排列组成,网络中的每个层使用一个可以微分的函数将激活数据从一个层传递到另一个层。卷积神经网络主要由三种类型的层构成:卷积层,池化(Pooling)层和全连接层(全连接层和常规神经网络中的一样)。通过将这些层叠加起来,就可以构建一个完整的卷积神经网络。
层的排列规矩
卷积神经网络最常见的形式就是将一些卷积层和
ReLU层放在一起,其后紧跟池化层,然后重复如此直到图像在空间上被缩小到一个足够小的尺寸,在某个地方过渡成成全连接层也较为常见。最后的全连接层得到输出,比如分类评分等。换句话说,最常见的卷积神经网络结构如下:INPUT -> [[CONV -> RELU] * N -> POOL?] * M -> [FC -> RELU] * K -> FC其中*指的是重复次数,POOL?指的是一个可选的汇聚层。其中
N >=0,通常N<=3,M>=0,K>=0,通常K<3。
三、卷积神经网络CNN的PyTorch实现
使用
Mnist数据集实现的CNN。导入包
import torch
import torch.nn as nn
import torchvision.datasets as normal_datasets
import torchvision.transforms as transforms
from torch.autograd import Variable下载数据集
num_epochs = 1
batch_size = 100
learning_rate = 0.001
# 将数据处理成Variable, 如果有GPU, 可以转成cuda形式
def get_variable(x):
x = Variable(x)
return x.cuda() if torch.cuda.is_available() else x
# 从torchvision.datasets中加载一些常用数据集
train_dataset = normal_datasets.MNIST(
root='./mnist/', # 数据集保存路径
train=True, # 是否作为训练集
transform=transforms.ToTensor(), # 数据如何处理, 可以自己自定义
download=True) # 路径下没有的话, 可以下载
# 见数据加载器和batch
test_dataset = normal_datasets.MNIST(root='./mnist/',
train=False,
transform=transforms.ToTensor())处理数据,使用
DataLoader进行batch训练
train_loader = torch.utils.data.DataLoader(dataset=train_dataset,
batch_size=batch_size,
shuffle=True)
test_loader = torch.utils.data.DataLoader(dataset=test_dataset,
batch_size=batch_size,
shuffle=False)建立计算图模型
# 两层卷积
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
# 使用序列工具快速构建
self.conv1 = nn.Sequential(
nn.Conv2d(1, 16, kernel_size=5, padding=2),
nn.BatchNorm2d(16),
nn.ReLU(),
nn.MaxPool2d(2))
self.conv2 = nn.Sequential(
nn.Conv2d(16, 32, kernel_size=5, padding=2),
nn.BatchNorm2d(32),
nn.ReLU(),
nn.MaxPool2d(2))
self.fc = nn.Linear(7 * 7 * 32, 10)
def forward(self, x):
out = self.conv1(x)
out = self.conv2(out)
out = out.view(out.size(0), -1) # reshape
out = self.fc(out)
return out
cnn = CNN()
if torch.cuda.is_available():
cnn = cnn.cuda()定义优化器
optimizer和损失
# 选择损失函数和优化方法
loss_func = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(cnn.parameters(), lr=learning_rate)进行
batch训练
for epoch in range(num_epochs):
for i, (images, labels) in enumerate(train_loader):
images = get_variable(images)
labels = get_variable(labels)
outputs = cnn(images)
loss = loss_func(outputs, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if (i + 1) % 100 == 0:
print('Epoch [%d/%d], Iter [%d/%d] Loss: %.4f'
% (epoch + 1, num_epochs, i + 1, len(train_dataset) // batch_size, loss.data[0]))
# 测试模型
cnn.eval() # 改成测试形态, 应用场景如: dropout
correct = 0
total = 0
for images, labels in test_loader:
images = get_variable(images)
labels = get_variable(labels)
outputs = cnn(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels.data).sum()
print(' 测试 准确率: %d %%' % (100 * correct / total))
# Save the Trained Model
torch.save(cnn.state_dict(), 'cnn.pkl')四、CNN常见模型之ResNet
ResNet——MSRA何凯明团队的Residual Networks,在2015年ImageNet上大放异彩,在ImageNet的classification、detection、localization以及COCO的detection和segmentation上均斩获了第一名的成绩,而且Deep Residual Learning for Image Recognition也获得了CVPR2016的best paper,实在是实至名归。论文地址
模型的PyTorch代码如下:
import torch
import torch.nn as nn
import torchvision.datasets as normal_datasets
import torchvision.transforms as transforms
from torch.autograd import Variable
num_epochs = 1
lr = 0.001
def get_variable(x):
x = Variable(x)
return x.cuda() if torch.cuda.is_available() else x
# 图像预处理
transform = transforms.Compose([
transforms.Scale(40),
transforms.RandomHorizontalFlip(),
transforms.RandomCrop(32),
transforms.ToTensor()])
# 加载CIFAR-10
train_dataset = normal_datasets.CIFAR10(root='./cifar_10/',
train=True,
transform=transform,
download=True)
test_dataset = normal_datasets.CIFAR10(root='./cifar_10/',
train=False,
transform=transforms.ToTensor())
train_loader = torch.utils.data.DataLoader(dataset=train_dataset,
batch_size=100,
shuffle=True)
test_loader = torch.utils.data.DataLoader(dataset=test_dataset,
batch_size=100,
shuffle=False)
# 3x3 卷积
def conv3x3(in_channels, out_channels, stride=1):
return nn.Conv2d(in_channels, out_channels, kernel_size=3,
stride=stride, padding=1, bias=False)
# Residual Block
class ResidualBlock(nn.Module):
def __init__(self, in_channels, out_channels, stride=1, downsample=None):
super(ResidualBlock, self).__init__()
self.conv1 = conv3x3(in_channels, out_channels, stride)
self.bn1 = nn.BatchNorm2d(out_channels)
self.relu = nn.ReLU(inplace=True)
self.conv2 = conv3x3(out_channels, out_channels)
self.bn2 = nn.BatchNorm2d(out_channels)
self.downsample = downsample
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
if self.downsample:
residual = self.downsample(x)
out += residual
out = self.relu(out)
return out
# ResNet Module
class ResNet(nn.Module):
def __init__(self, block, layers, num_classes=10):
super(ResNet, self).__init__()
self.in_channels = 16
self.conv = conv3x3(3, 16)
self.bn = nn.BatchNorm2d(16)
self.relu = nn.ReLU(inplace=True)
self.layer1 = self.make_layer(block, 16, layers[0])
self.layer2 = self.make_layer(block, 32, layers[0], 2)
self.layer3 = self.make_layer(block, 64, layers[1], 2)
self.avg_pool = nn.AvgPool2d(8)
self.fc = nn.Linear(64, num_classes)
def make_layer(self, block, out_channels, blocks, stride=1):
downsample = None
if (stride != 1) or (self.in_channels != out_channels):
downsample = nn.Sequential(
conv3x3(self.in_channels, out_channels, stride=stride),
nn.BatchNorm2d(out_channels))
layers = []
layers.append(block(self.in_channels, out_channels, stride, downsample))
self.in_channels = out_channels
for i in range(1, blocks):
layers.append(block(out_channels, out_channels))
return nn.Sequential(*layers)
def forward(self, x):
out = self.conv(x)
out = self.bn(out)
out = self.relu(out)
out = self.layer1(out)
out = self.layer2(out)
out = self.layer3(out)
out = self.avg_pool(out)
out = out.view(out.size(0), -1)
out = self.fc(out)
return out
resnet = ResNet(ResidualBlock, [2, 2, 2, 2])
if torch.cuda.is_available():
resnet = resnet.cuda()
loss_func = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(resnet.parameters(), lr=lr)
# 训练
for epoch in range(num_epochs):
for i, (images, labels) in enumerate(train_loader):
images = get_variable(images)
labels = get_variable(labels)
outputs = resnet(images)
loss = loss_func(outputs, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if (i + 1) % 100 == 0:
print("Epoch [%d/%d], Iter [%d/%d] Loss: %.4f" % (epoch + 1, num_epochs, i + 1, 500, loss.data[0]))
# 衰减学习率
if (epoch + 1) % 20 == 0:
lr /= 3
optimizer = torch.optim.Adam(resnet.parameters(), lr=lr)
# 测试
correct = 0
total = 0
for images, labels in test_loader:
images = get_variable(images)
labels = get_variable(labels)
outputs = resnet(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels.data).sum()
print(' 测试 准确率: %d %%' % (100 * correct / total))
# 保存模型参数
torch.save(resnet.state_dict(), 'resnet.pkl')reference:
http://lawlite.me/2017/05/10/PyTorch/#1、卷积神经网络-CNN
http://www.cnblogs.com/nsnow/p/4562308.html
http://cs231n.github.io/convolutional-networks/
https://zhuanlan.zhihu.com/p/22038289
http://pytorch-cn.readthedocs.io/zh/latest/
https://github.com/pytorch/pytorch
https://morvanzhou.github.io/tutorials/machine-learning/torch/
明天继续推出:专知PyTorch深度学习教程系列-< 快速理解系列(二): 图文+代码, 让你快速理解LSTM>,敬请关注。
完整系列搜索查看,请PC登录
www.zhuanzhi.ai, 搜索“PyTorch”即可得。
对PyTorch教程感兴趣的同学,欢迎进入我们的专知PyTorch主题群一起交流、学习、讨论,扫一扫如下群二维码即可进入:

了解使用专知-获取更多AI知识!
-END-
欢迎使用专知
专知,一个新的认知方式!目前聚焦在人工智能领域为AI从业者提供专业可信的知识分发服务, 包括主题定制、主题链路、搜索发现等服务,帮你又好又快找到所需知识。
使用方法>>访问www.zhuanzhi.ai, 或点击文章下方“阅读原文”即可访问专知
中国科学院自动化研究所专知团队
@2017 专知
专 · 知
关注我们的公众号,获取最新关于专知以及人工智能的资讯、技术、算法、深度干货等内容。扫一扫下方关注我们的微信公众号。


点击“ 阅读原文 ”,使用 专知!



