爱丁堡大学最新《因果机器学习: 医疗健康与精准医疗应用》2022综述
因果机器学习如何用于医疗中?爱丁堡大学最新《因果机器学习医疗应用》综述, 探讨因果推理如何利用机器学习的最新进展,纳入临床决策支持系统的不同方面

因果机器学习(CML)在医疗保健领域越来越受欢迎。除了将领域知识添加到学习系统的固有能力之外,CML还提供了一个完整的工具集,用于研究系统对干预的反应(例如,给定治疗的结果)。量化干预的效果使我们能够在混杂因素存在的情况下做出可行的决策,同时保持鲁棒性。在此,我们将探讨因果推理如何利用机器学习的最新进展,纳入临床决策支持系统的不同方面。在本文中,我们使用阿尔茨海默病创建的例子来说明如何CML可以在临床场景中是有利的。此外,我们讨论了医疗保健应用中存在的重要挑战,如处理高维和非结构化数据,推广到非分布样本和时间关系,尽管研究社区的巨大努力仍有待解决。最后,我们回顾了因果表征学习、因果发现和因果推理的研究路线,这些研究为解决上述挑战提供了潜力。
随着强大的机器学习(ML)方法(如深度学习[1])的出现,医疗健康预测系统取得了相当大的进展。在医疗保健领域,临床决策支持(CDS)工具可以对诸如医学图像、临床免费文本注释、血液测试和遗传数据等电子健康记录(EHR)数据进行检测、分类和/或分割等任务进行预测。这些系统通常使用监督学习技术进行训练。然而,大多数由ML技术支持的CDS系统只学习数据中变量之间的关联,而不区分因果关系和(虚假)相关性。
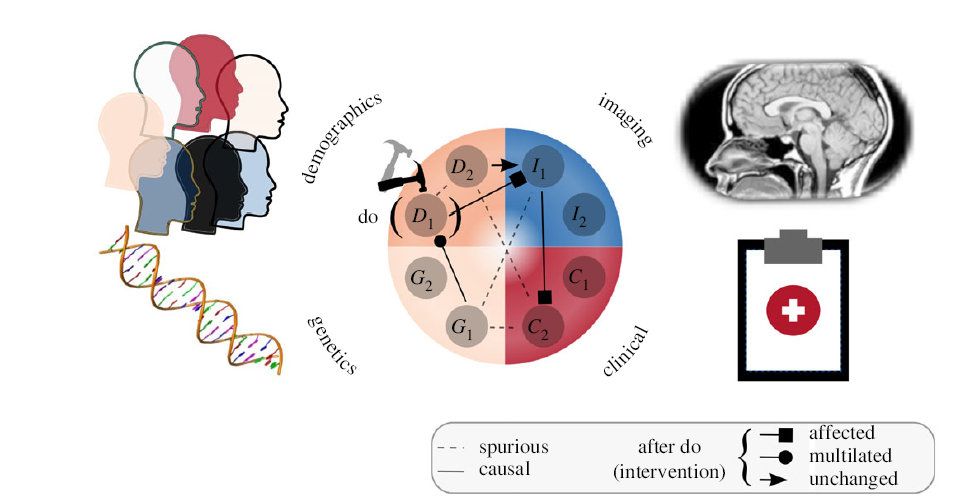
为什么我们要考虑医疗健康中的因果框架?
在过去的几十年里,CI在社会科学、计量经济学、流行病学和病因学等领域做出了一些贡献[4,5],最近它已经扩展到其他医疗健康领域,如医学影像学[14-16]和药理学[2]。在本节中,我们将详细阐述因果关系如何用于改善医疗决策。例如,尽管来自EHRs的数据通常是观察性的,但它们已经成功地用于若干ML应用,如建模疾病进展[18],预测疾病恶化[19]和发现危险因素[20],以及预测治疗反应[21]。此外,我们现在有证据表明,算法在成像任务中实现了超人的性能,如分割[22],检测病理和分类[23]。然而,精确医学试图实现的目标并不是以近乎完美的精度预测特定患者的疾病。相反,我们的目标是建立ML方法,从观察性患者数据中提取可操作的信息,以便做出介入(治疗)决定。这就需要CI,它超越了下面详细介绍的用于预测的标准监督学习方法。为了在患者层面做出可执行的决定,我们需要评估治疗效果。治疗效果是两种潜在结果的差异: 事实结果和反事实结果。为了进行可操作的预测,我们需要算法来学习如何对可能采取不同行动的假设场景进行推理,从而创建一个可以导航的决策边界,以改善患者的结果。最近有证据表明,人类使用反事实推理来做出因果判断[25],这为这种推理假设提供了支持。这就是为什么推断治疗效果的问题与潜在结果框架定义的标准监督学习[2]有本质区别[5,10]。根据定义,当使用观测数据集时,我们从未观察到与事实相反的结果。因此,针对个体的最佳治疗(精准医疗[26]的主要目标)只能通过能够进行因果推理的模型来确定,详见§3.3。
复杂数据的因果机器学习

在§3中,我们关注在因果模型已知(至少部分已知)且变量划分良好的情况下的因果推理。我们向读者推荐Bica等人[2]对这些方法进行全面的综述。然而,大多数医疗问题在因果推理的上游都有挑战。在本节中,我们强调处理高维和多模态数据以及时间信息的需要,并讨论从非结构化数据学习时在非分布设置中的泛化。
因果机器学习研究方向
本文的最后一部分讨论了CML在医疗健康中的应用,包括复杂的多模态、时间和非结构化数据,并讨论了一些未来的研究方向。我们根据§1中定义的三个类别来讨论CML:(i)因果表征学习; (ii) 因果关系的发现; (iii) 因果推理。
因果表示学习
表示学习[82]指的是ML的组合视图。我们考虑的不是输入域和输出域之间的映射,而是一种捕捉世界概念的中间表示。当考虑使用真实的医疗数据进行学习和推理时,这个概念是必不可少的。§4.3中考虑的高维和非结构化数据,没有被组织成可以直接用于当前因果模型的单位。在大多数情况下,感兴趣的变量不是,例如,图像本身,而是它的生成因素之一,例如AD例子中的灰质体积。因果表征学习[9]将学习世界因素的概念扩展到用因果模型建模变量之间的关系。换句话说,目标是将表示域Z建模为§2.1中的SCM。因果表征学习建立在解纠缠表征学习文献[83-85]的基础上,旨在强化更强的归纳偏差,而非解纠缠表征通常追求的因素独立假设。这个想法是为了强化遵循因果模型的潜在变量的层次结构,而因果模型又应该遵循真实的数据生成过程。
因果关系的发现
因果推理
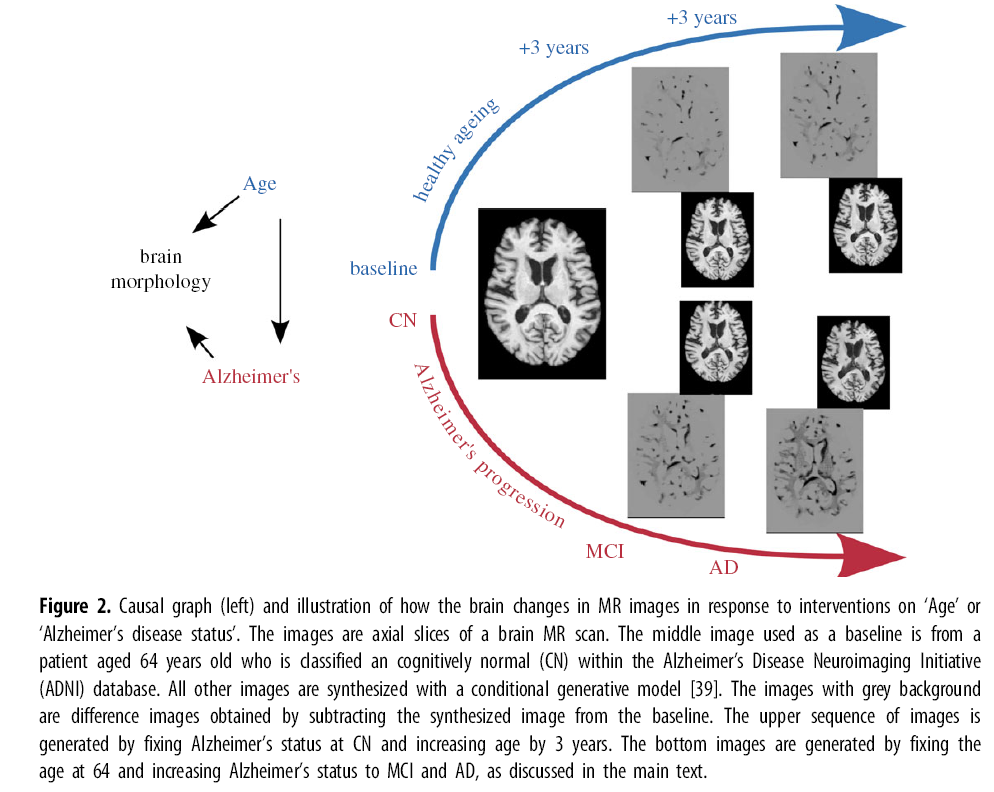
据推测,人类通过直觉理论[35]内在地构建了生成因果模型来想象近似的物理机制。同样,利用围绕干预的因果模型的力量开发模型也将是有用的。因果模型可以被正式地操纵以衡量干预的效果。使用因果模型来量化干预的效果并思考最佳决策被称为因果推理。正如前面§3.3中所讨论的,因果推理在医疗健康中的一个关键好处是围绕个性化决策。在SCMS(§2.1)中,个性化决策通常指的是回答关于历史情况的反事实问题的能力,例如“如果患者接受了替代治疗X会发生什么?”反事实可以通过(i)三步程序[53](绑架-动作-预测)进行估计,该程序最近通过深度学习[15,92]得到增强,使用生成模型,如归一化流[93]、变分自编码器[94]和扩散概率模型[95],或(ii)孪生网络[96],该网络增强了原始SCM,从而同时表示事实和反事实变量。深度孪生网络[97]利用神经网络进一步提高因果机制的灵活性。我们注意到,量化干预效果通常假设因果模型要么是明确给出的[15,98],要么是通过因果发现获得的[99]。Aglietti等人[98]利用他汀类药物对前列腺特异性抗原水平的因果效应模型来评估他们的方法[100],而Pawlowski等人[15]和Wang等人[101]则对大脑MRI图像的数据生成过程建模。Reinhold等[102]在Pawlowski等人[15]的基础上增加了多发性硬化病变的病理信息。在潜在结果框架(§2.2)中,已经提出了许多方法来根据观察数据估计个性化(也称为个体化或条件平均)治疗效果。这些技术包括贝叶斯加性回归树[103]、双ML[104,105]、带积分概率度量[106]或正交约束[107]的神经网络正则化、高斯过程[108]、生成式对抗网络[109]或基于能量的模型[110]。另一种估计CATE的趋势是基于元学习者[111,112]。在元学习设置中,传统的(监督)ML被用来预测潜在结果和倾向的条件期望。然后,通过取估计的潜在结果之间的差值[112]或使用带有回归调整、倾向加权或双鲁棒学习的两步程序[111]来计算CATE。
参考文献:
Jason Abrevaya, Yu-Chin Hsu, and Robert P Lieli. Estimating conditional average treatment effects. Journal of Business & Economic Statistics, 33(4):485–505, 2015. Emma L. Anderson, Laura D. Howe, Kaitlin H. Wade, Yoav Ben-Shlomo, W. David Hill, Ian J. Deary, Eleanor C. Sanderson, Jie Zheng, Roxanna Korologou-Linden, Evie Stergiakouli, George Davey Smith, Neil M. Davies, and Gibran Hemani. Education, intelligence and alzheimer’s disease: evidence from a multivariable two-sample mendelian randomization study. International Journal of Epidemiology, 49:1163–1172, 2020. doi: 10.1093/IJE/DYZ280.
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“CMLH” 就可以获取《爱丁堡大学最新《因果机器学习: 医疗健康与精准医疗应用》2022综述》专知下载链接




